 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUSTC-KXDIGIT System Description for ASVspoof5 Challenge
Paper and Code
Sep 03, 2024
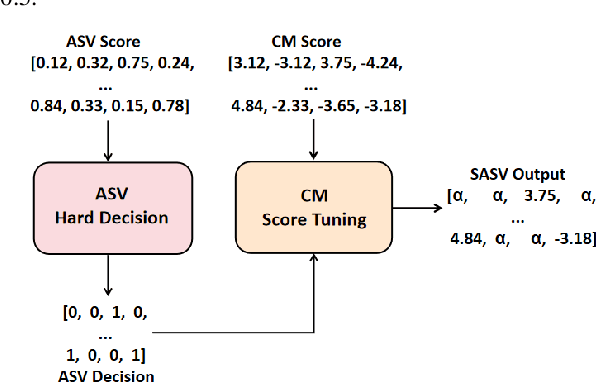
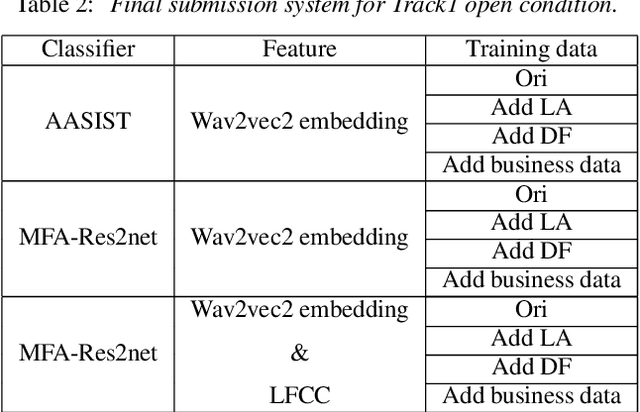
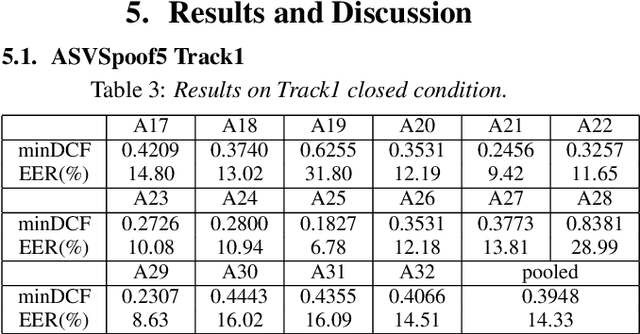
This paper describes the USTC-KXDIGIT system submitted to the ASVspoof5 Challenge for Track 1 (speech deepfake detection) and Track 2 (spoofing-robust automatic speaker verification, SASV). Track 1 showcases a diverse range of technical qualities from potential processing algorithms and includes both open and closed conditions. For these conditions, our system consists of a cascade of a frontend feature extractor and a back-end classifier. We focus on extensive embedding engineering and enhancing the generalization of the back-end classifier model. Specifically, the embedding engineering is based on hand-crafted features and speech representations from a self-supervised model, used for closed and open conditions, respectively. To detect spoof attacks under various adversarial conditions, we trained multiple systems on an augmented training set. Additionally, we used voice conversion technology to synthesize fake audio from genuine audio in the training set to enrich the synthesis algorithms. To leverage the complementary information learned by different model architectures, we employed activation ensemble and fused scores from different systems to obtain the final decision score for spoof detection. During the evaluation phase, the proposed methods achieved 0.3948 minDCF and 14.33% EER in the close condition, and 0.0750 minDCF and 2.59% EER in the open condition, demonstrating the robustness of our submitted systems under adversarial conditions. In Track 2, we continued using the CM system from Track 1 and fused it with a CNN-based ASV system. This approach achieved 0.2814 min-aDCF in the closed condition and 0.0756 min-aDCF in the open condition, showcasing superior performance in the SASV system.