 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Dynamic Graph Relation Learning for Urban Metro Flow Prediction
Apr 06, 2022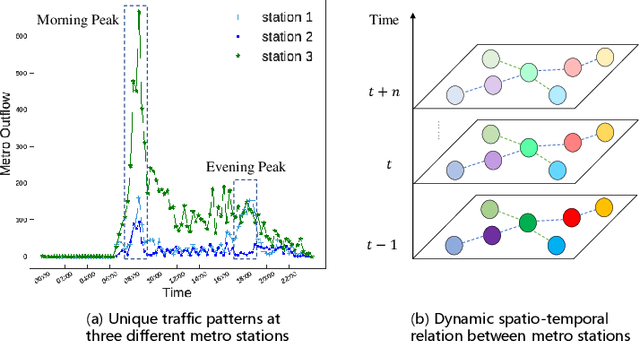

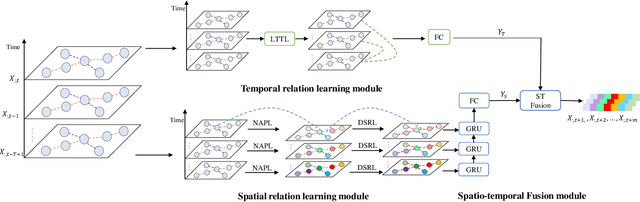

Urban metro flow prediction is of great value for metro operation scheduling, passenger flow management and personal travel planning. However, it faces two main challenges. First, different metro stations, e.g. transfer stations and non-transfer stations, have unique traffic patterns. Second, it is challenging to model complex spatio-temporal dynamic relation of metro stations. To address these challenges, we develop a spatio-temporal dynamic graph relational learning model (STDGRL) to predict urban metro station flow. First, we propose a spatio-temporal node embedding representation module to capture the traffic patterns of different stations. Second, we employ a dynamic graph relationship learning module to learn dynamic spatial relationships between metro stations without a predefined graph adjacency matrix. Finally, we provide a transformer-based long-term relationship prediction module for long-term metro flow prediction. Extensive experiments are conducted based on metro data in Beijing, Shanghai, Chongqing and Hangzhou. Experimental results show the advantages of our method beyond 11 baselines for urban metro flow prediction.
DCEF: Deep Collaborative Encoder Framework for Unsupervised Clustering
Jun 12, 2019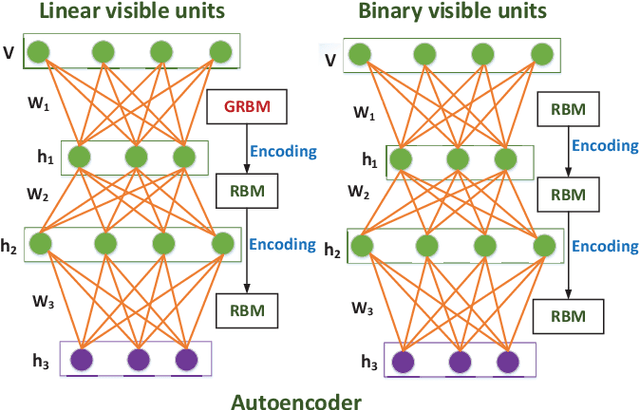

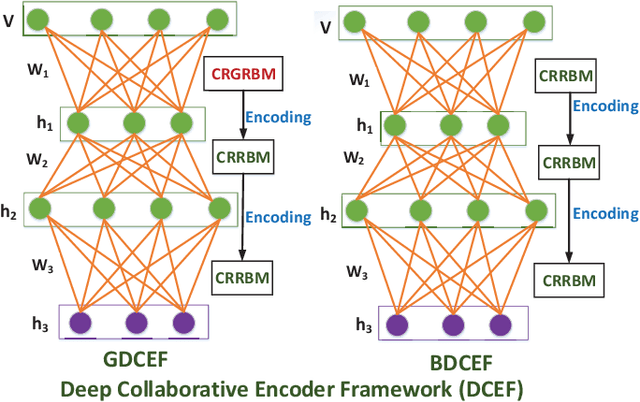
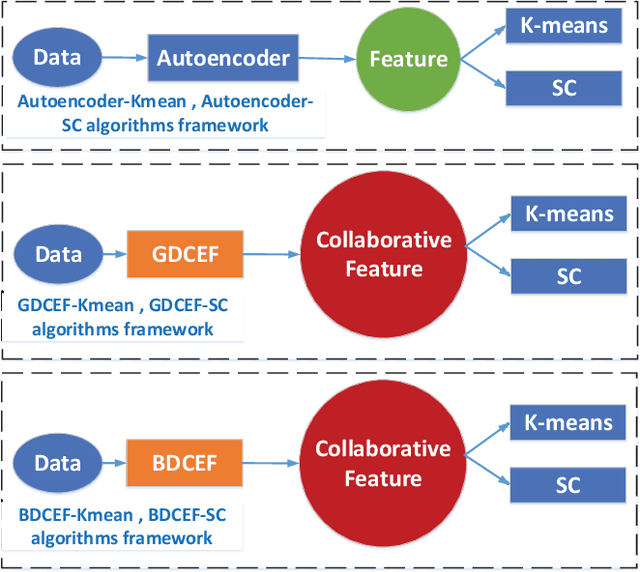
Collaborative representation is a popular feature learning approach, which encoding process is assisted by variety types of information. In this paper, we propose a collaborative representation restricted Boltzmann Machine (CRRBM) for modeling binary data and a collaborative representation Gaussian restricted Boltzmann Machine (CRGRBM) for modeling realvalued data by applying a collaborative representation strategy in the encoding procedure. We utilize Locality Sensitive Hashing (LSH) to generate similar sample subsets of the instance and observed feature set simultaneously from input data. Hence, we can obtain some mini blocks, which come from the intersection of instance and observed feature subsets. Then we integrate Contrastive Divergence and Bregman Divergence methods with mini blocks to optimize our CRRBM and CRGRBM models. In their training process, the complex collaborative relationships between multiple instances and features are fused into the hidden layer encoding. Hence, these encodings have dual characteristics of concealment and cooperation. Here, we develop two deep collaborative encoder frameworks (DCEF) based on the CRRBM and CRGRBM models: one is a DCEF with Gaussian linear visible units (GDCEF) for modeling real-valued data, and the other is a DCEF with binary visible units (BDCEF) for modeling binary data. We explore the collaborative representation capability of the hidden features in every layer of the GDCEF and BDCEF framework, especially in the deepest hidden layer. The experimental results show that the GDCEF and BDCEF frameworks have more outstanding performances than the classic Autoencoder framework for unsupervised clustering task on the MSRA-MM2.0 and UCI datasets, respectively.
Reconstruction of Hidden Representation for Robust Feature Extraction
Oct 23, 2018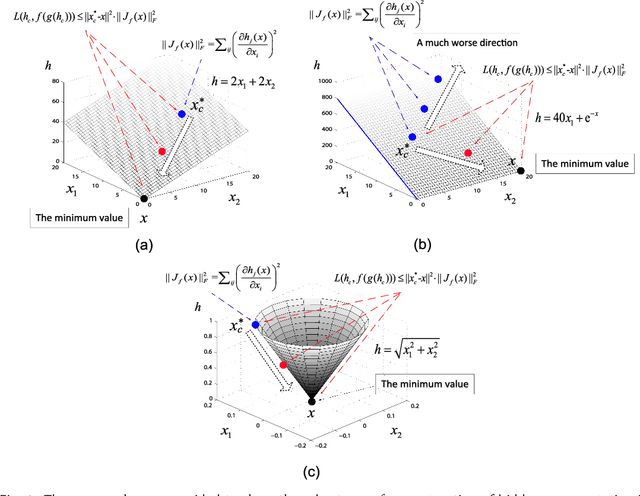
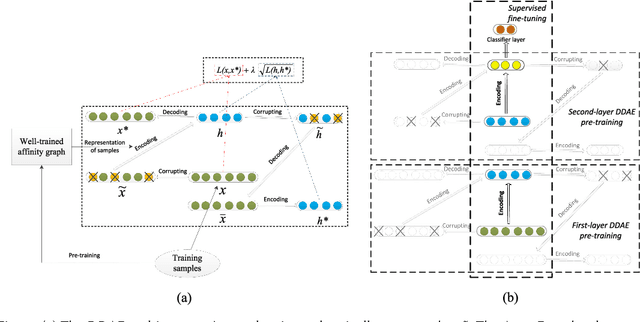
This paper aims to develop a new and robust approach to feature representation. Motivated by the success of Auto-Encoders, we first theoretical summarize the general properties of all algorithms that are based on traditional Auto-Encoders: 1) The reconstruction error of the input can not be lower than a lower bound, which can be viewed as a guiding principle for reconstructing the input. Additionally, when the input is corrupted with noises, the reconstruction error of the corrupted input also can not be lower than a lower bound. 2) The reconstruction of a hidden representation achieving its ideal situation is the necessary condition for the reconstruction of the input to reach the ideal state. 3) Minimizing the Frobenius norm of the Jacobian matrix of the hidden representation has a deficiency and may result in a much worse local optimum value. We believe that minimizing the reconstruction error of the hidden representation is more robust than minimizing the Frobenius norm of the Jacobian matrix of the hidden representation. Based on the above analysis, we propose a new model termed Double Denoising Auto-Encoders (DDAEs), which uses corruption and reconstruction on both the input and the hidden representation. We demonstrate that the proposed model is highly flexible and extensible and has a potentially better capability to learn invariant and robust feature representations. We also show that our model is more robust than Denoising Auto-Encoders (DAEs) for dealing with noises or inessential features. Furthermore, we detail how to train DDAEs with two different pre-training methods by optimizing the objective function in a combined and separate manner, respectively. Comparative experiments illustrate that the proposed model is significantly better for representation learning than the state-of-the-art models.
A Hybrid Method for Traffic Flow Forecasting Using Multimodal Deep Learning
Jul 06, 2018

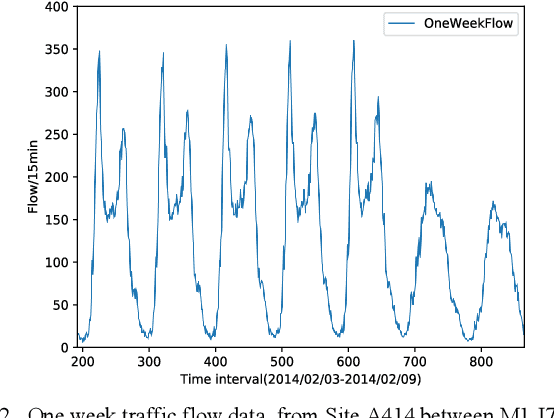

Traffic flow forecasting has been regarded as a key problem of intelligent transport systems. In this work, we propose a hybrid multimodal deep learning method for short-term traffic flow forecasting, which jointly learns the spatial-temporal correlation features and interdependence of multi-modality traffic data by multimodal deep learning architecture. According to the highly nonlinear characteristics of multi-modality traffic data, the base module of our method consists of one-dimensional Convolutional Neural Networks (CNN) and Gated Recurrent Units (GRU). The former is to capture the local trend features and the latter is to capture long temporal dependencies. Then, we design a hybrid multimodal deep learning framework (HMDLF) for fusing share representation features of different modality traffic data based on multiple CNN-GRU modules. The experiment results indicate that the proposed multimodal deep learning framework is capable of dealing with complex nonlinear urban traffic flow forecasting with satisfying accuracy and effectiveness.
Three-Stream Convolutional Networks for Video-based Person Re-Identification
Nov 22, 2017


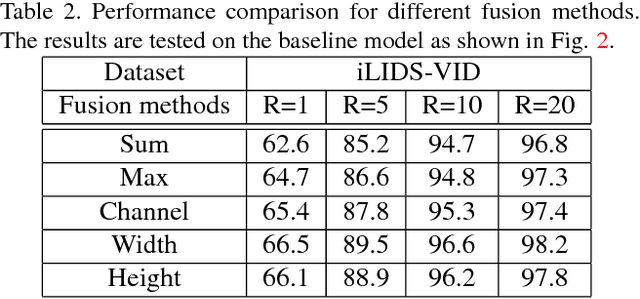
This paper aims to develop a new architecture that can make full use of the feature maps of convolutional networks. To this end, we study a number of methods for video-based person re-identification and make the following findings: 1) Max-pooling only focuses on the maximum value of a receptive field, wasting a lot of information. 2) Networks with different streams even including the one with the worst performance work better than networks with same streams, where each one has the best performance alone. 3) A full connection layer at the end of convolutional networks is not necessary. Based on these studies, we propose a new convolutional architecture termed Three-Stream Convolutional Networks (TSCN). It first uses different streams to learn different aspects of feature maps for attentive spatio-temporal fusion of video, and then merges them together to study some union features. To further utilize the feature maps, two architectures are designed by using the strategies of multi-scale and upsampling. Comparative experiments on iLIDS-VID, PRID-2011 and MARS datasets illustrate that the proposed architectures are significantly better for feature extraction than the state-of-the-art models.