 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraceable Drug Recommendation over Medical Knowledge Graphs
Oct 31, 2025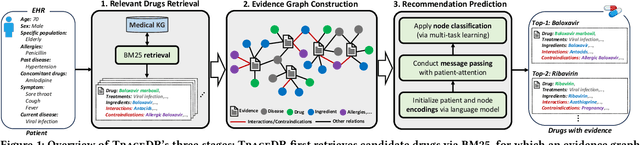
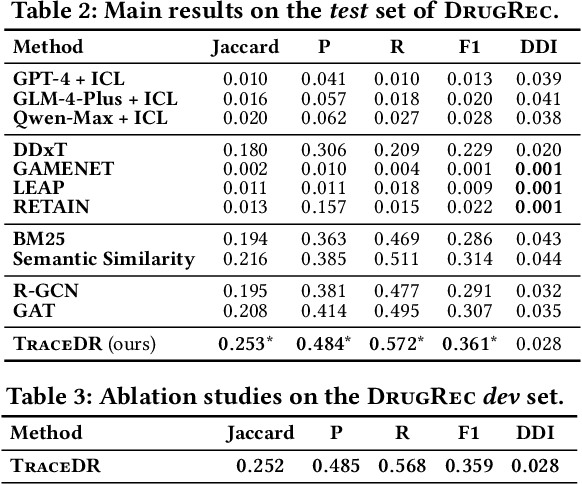

Drug recommendation (DR) systems aim to support healthcare professionals in selecting appropriate medications based on patients' medical conditions. State-of-the-art approaches utilize deep learning techniques for improving DR, but fall short in providing any insights on the derivation process of recommendations -- a critical limitation in such high-stake applications. We propose TraceDR, a novel DR system operating over a medical knowledge graph (MKG), which ensures access to large-scale and high-quality information. TraceDR simultaneously predicts drug recommendations and related evidence within a multi-task learning framework, enabling traceability of medication recommendations. For covering a more diverse set of diseases and drugs than existing works, we devise a framework for automatically constructing patient health records and release DrugRec, a new large-scale testbed for DR.
A Pre-trained Data Deduplication Model based on Active Learning
Jul 31, 2023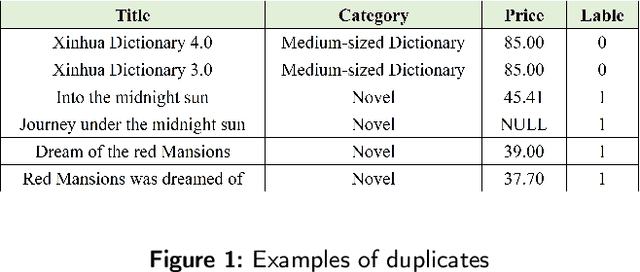


In the era of big data, the issue of data quality has become increasingly prominent. One of the main challenges is the problem of duplicate data, which can arise from repeated entry or the merging of multiple data sources. These "dirty data" problems can significantly limit the effective application of big data. To address the issue of data deduplication, we propose a pre-trained deduplication model based on active learning, which is the first work that utilizes active learning to address the problem of deduplication at the semantic level. The model is built on a pre-trained Transformer and fine-tuned to solve the deduplication problem as a sequence to classification task, which firstly integrate the transformer with active learning into an end-to-end architecture to select the most valuable data for deduplication model training, and also firstly employ the R-Drop method to perform data augmentation on each round of labeled data, which can reduce the cost of manual labeling and improve the model's performance. Experimental results demonstrate that our proposed model outperforms previous state-of-the-art (SOTA) for deduplicated data identification, achieving up to a 28% improvement in Recall score on benchmark datasets.
A Missing Value Filling Model Based on Feature Fusion Enhanced Autoencoder
Aug 29, 2022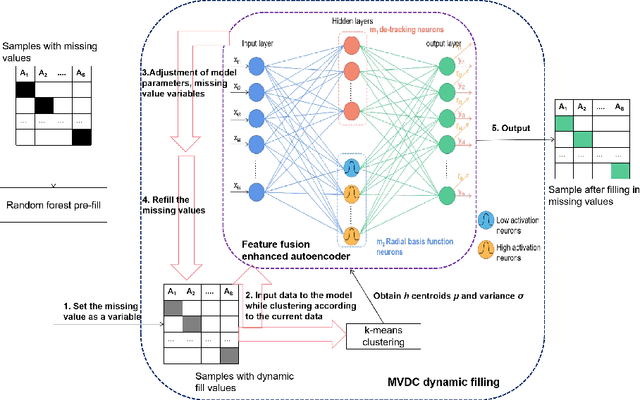
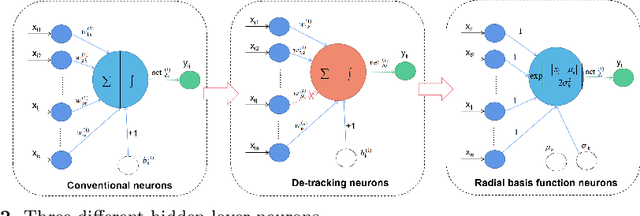
With the advent of the big data era, the data quality problem is becoming more and more crucial. Among many factors, data with missing values is one primary issue, and thus developing effective imputation models is a key topic in the research community. Recently, a major research direction is to employ neural network models such as selforganizing mappings or automatic encoders for filling missing values. However, these classical methods can hardly discover correlation features and common features simultaneously among data attributes. Especially,it is a very typical problem for classical autoencoders that they often learn invalid constant mappings, thus dramatically hurting the filling performance. To solve the above problems, we propose and develop a missing-value-filling model based on a feature-fusion-enhanced autoencoder. We first design and incorporate into an autoencoder a hidden layer that consists of de-tracking neurons and radial basis function neurons, which can enhance the ability to learn correlated features and common features. Besides, we develop a missing value filling strategy based on dynamic clustering (MVDC) that is incorporated into an iterative optimization process. This design can enhance the multi-dimensional feature fusion ability and thus improves the dynamic collaborative missing-value-filling performance. The effectiveness of our model is validated by experimental comparisons to many missing-value-filling methods that are tested on seven datasets with different missing rates.
DRAformer: Differentially Reconstructed Attention Transformer for Time-Series Forecasting
Jun 11, 2022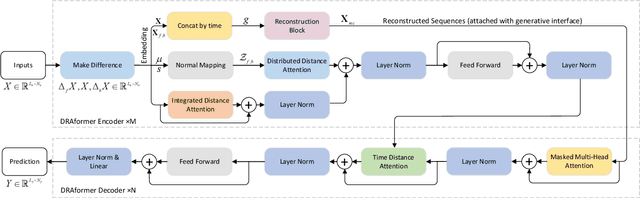
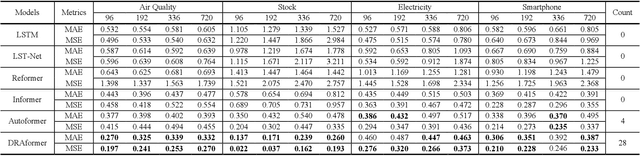
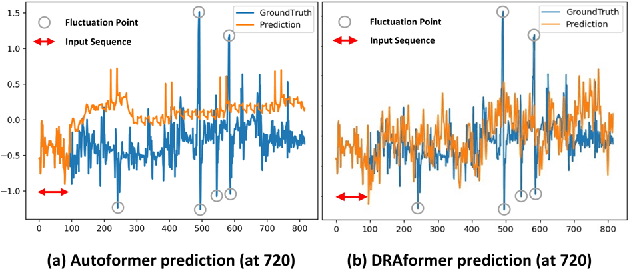

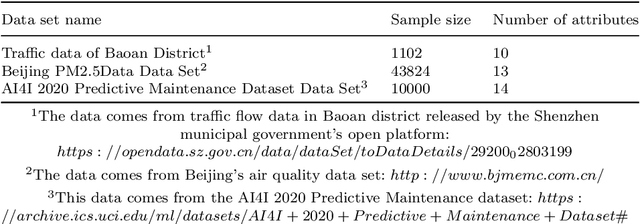
Time-series forecasting plays an important role in many real-world scenarios, such as equipment life cycle forecasting, weather forecasting, and traffic flow forecasting. It can be observed from recent research that a variety of transformer-based models have shown remarkable results in time-series forecasting. However, there are still some issues that limit the ability of transformer-based models on time-series forecasting tasks: (i) learning directly on raw data is susceptible to noise due to its complex and unstable feature representation; (ii) the self-attention mechanisms pay insufficient attention to changing features and temporal dependencies. In order to solve these two problems, we propose a transformer-based differentially reconstructed attention model DRAformer. Specifically, DRAformer has the following innovations: (i) learning against differenced sequences, which preserves clear and stable sequence features by differencing and highlights the changing properties of sequences; (ii) the reconstructed attention: integrated distance attention exhibits sequential distance through a learnable Gaussian kernel, distributed difference attention calculates distribution difference by mapping the difference sequence to the adaptive feature space, and the combination of the two effectively focuses on the sequences with prominent associations; (iii) the reconstructed decoder input, which extracts sequence features by integrating variation information and temporal correlations, thereby obtaining a more comprehensive sequence representation. Extensive experiments on four large-scale datasets demonstrate that DRAformer outperforms state-of-the-art baselines.
Spatio-Temporal Dynamic Graph Relation Learning for Urban Metro Flow Prediction
Apr 06, 2022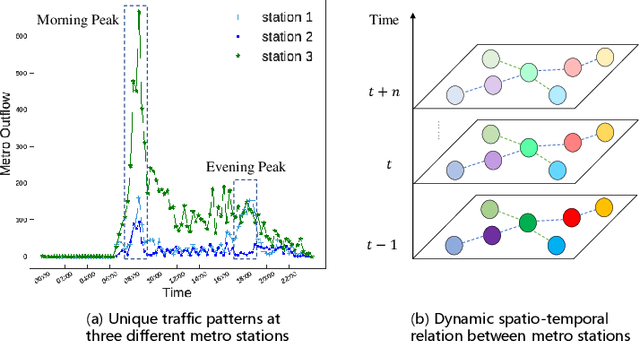

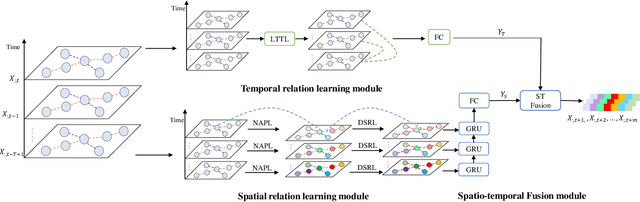

Urban metro flow prediction is of great value for metro operation scheduling, passenger flow management and personal travel planning. However, it faces two main challenges. First, different metro stations, e.g. transfer stations and non-transfer stations, have unique traffic patterns. Second, it is challenging to model complex spatio-temporal dynamic relation of metro stations. To address these challenges, we develop a spatio-temporal dynamic graph relational learning model (STDGRL) to predict urban metro station flow. First, we propose a spatio-temporal node embedding representation module to capture the traffic patterns of different stations. Second, we employ a dynamic graph relationship learning module to learn dynamic spatial relationships between metro stations without a predefined graph adjacency matrix. Finally, we provide a transformer-based long-term relationship prediction module for long-term metro flow prediction. Extensive experiments are conducted based on metro data in Beijing, Shanghai, Chongqing and Hangzhou. Experimental results show the advantages of our method beyond 11 baselines for urban metro flow prediction.
Spatio-Temporal Latent Graph Structure Learning for Traffic Forecasting
Feb 25, 2022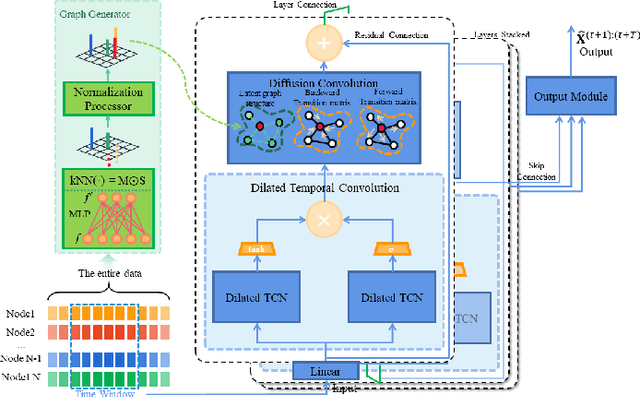
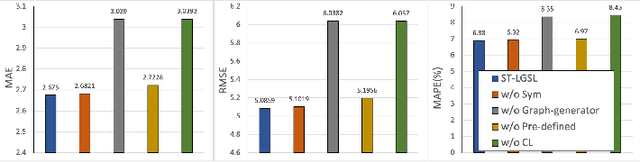
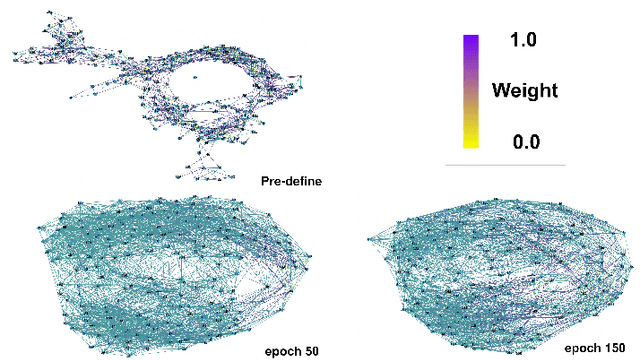

Accurate traffic forecasting, the foundation of intelligent transportation systems (ITS), has never been more significant than nowadays due to the prosperity of the smart cities and urban computing. Recently, Graph Neural Network truly outperforms the traditional methods. Nevertheless, the most conventional GNN based model works well while given a pre-defined graph structure. And the existing methods of defining the graph structures focus purely on spatial dependencies and ignored the temporal correlation. Besides, the semantics of the static pre-defined graph adjacency applied during the whole training progress is always incomplete, thus overlooking the latent topologies that may fine-tune the model. To tackle these challenges, we proposed a new traffic forecasting framework--Spatio-Temporal Latent Graph Structure Learning networks (ST-LGSL). More specifically, the model employed a graph generator based on Multilayer perceptron and K-Nearest Neighbor, which learns the latent graph topological information from the entire data considering both spatial and temporal dynamics. Furthermore, with the initialization of MLP-kNN based on ground-truth adjacency matrix and similarity metric in kNN, ST-LGSL aggregates the topologies focusing on geography and node similarity. Additionally, the generated graphs act as the input of spatio-temporal prediction module combined with the Diffusion Graph Convolutions and Gated Temporal Convolutions Networks. Experimental results on two benchmarking datasets in real world demonstrate that ST-LGSL outperforms various types of state-of-art baselines.
A Differential Attention Fusion Model Based on Transformer for Time Series Forecasting
Feb 23, 2022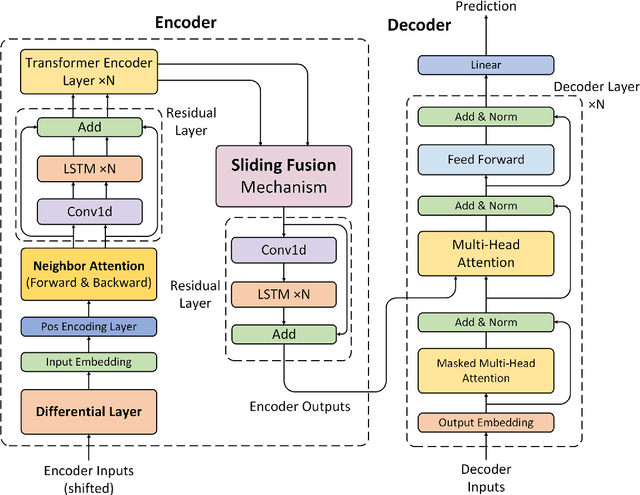
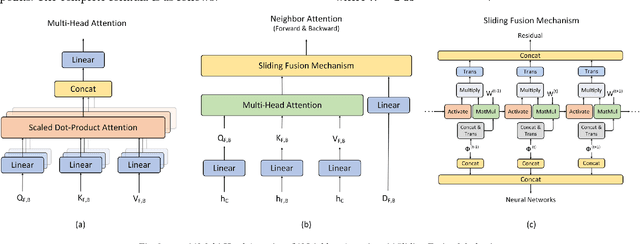
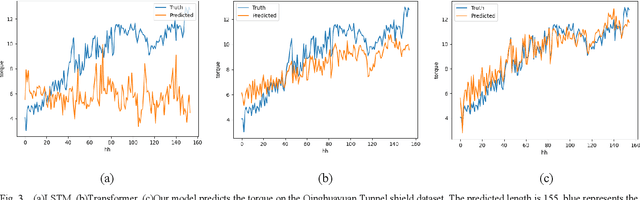
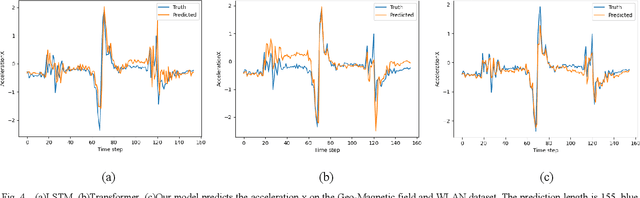
Time series forecasting is widely used in the fields of equipment life cycle forecasting, weather forecasting, traffic flow forecasting, and other fields. Recently, some scholars have tried to apply Transformer to time series forecasting because of its powerful parallel training ability. However, the existing Transformer methods do not pay enough attention to the small time segments that play a decisive role in prediction, making it insensitive to small changes that affect the trend of time series, and it is difficult to effectively learn continuous time-dependent features. To solve this problem, we propose a differential attention fusion model based on Transformer, which designs the differential layer, neighbor attention, sliding fusion mechanism, and residual layer on the basis of classical Transformer architecture. Specifically, the differences of adjacent time points are extracted and focused by difference and neighbor attention. The sliding fusion mechanism fuses various features of each time point so that the data can participate in encoding and decoding without losing important information. The residual layer including convolution and LSTM further learns the dependence between time points and enables our model to carry out deeper training. A large number of experiments on three datasets show that the prediction results produced by our method are favorably comparable to the state-of-the-art.
Fairness and Accuracy in Federated Learning
Dec 18, 2020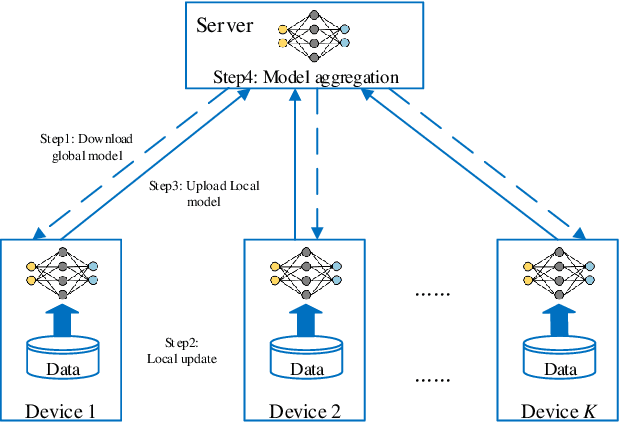
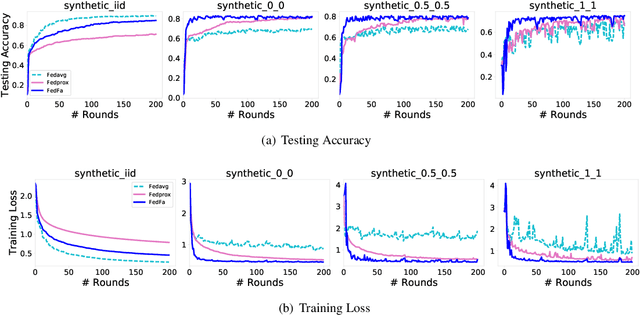
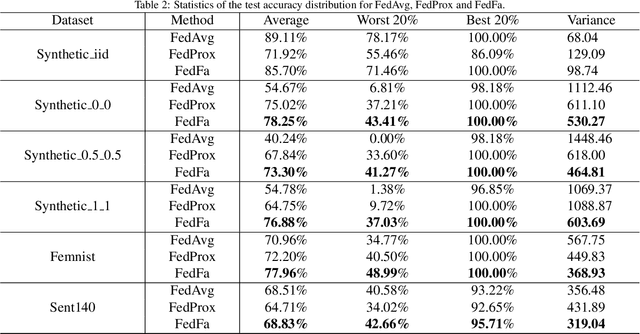
In the federated learning setting, multiple clients jointly train a model under the coordination of the central server, while the training data is kept on the client to ensure privacy. Normally, inconsistent distribution of data across different devices in a federated network and limited communication bandwidth between end devices impose both statistical heterogeneity and expensive communication as major challenges for federated learning. This paper proposes an algorithm to achieve more fairness and accuracy in federated learning (FedFa). It introduces an optimization scheme that employs a double momentum gradient, thereby accelerating the convergence rate of the model. An appropriate weight selection algorithm that combines the information quantity of training accuracy and training frequency to measure the weights is proposed. This procedure assists in addressing the issue of unfairness in federated learning due to preferences for certain clients. Our results show that the proposed FedFa algorithm outperforms the baseline algorithm in terms of accuracy and fairness.
Urban flows prediction from spatial-temporal data using machine learning: A survey
Aug 26, 2019


Urban spatial-temporal flows prediction is of great importance to traffic management, land use, public safety, etc. Urban flows are affected by several complex and dynamic factors, such as patterns of human activities, weather, events and holidays. Datasets evaluated the flows come from various sources in different domains, e.g. mobile phone data, taxi trajectories data, metro/bus swiping data, bike-sharing data and so on. To summarize these methodologies of urban flows prediction, in this paper, we first introduce four main factors affecting urban flows. Second, in order to further analysis urban flows, a preparation process of multi-sources spatial-temporal data related with urban flows is partitioned into three groups. Third, we choose the spatial-temporal dynamic data as a case study for the urban flows prediction task. Fourth, we analyze and compare some well-known and state-of-the-art flows prediction methods in detail, classifying them into five categories: statistics-based, traditional machine learning-based, deep learning-based, reinforcement learning-based and transfer learning-based methods. Finally, we give open challenges of urban flows prediction and an outlook in the future of this field. This paper will facilitate researchers find suitable methods and open datasets for addressing urban spatial-temporal flows forecast problems.
Deep Air Quality Forecasting Using Hybrid Deep Learning Framework
Dec 12, 2018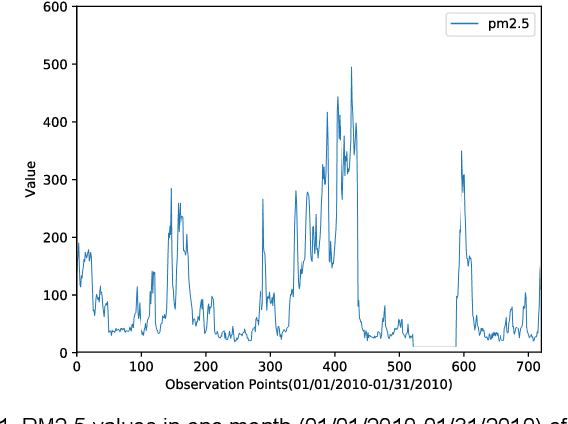
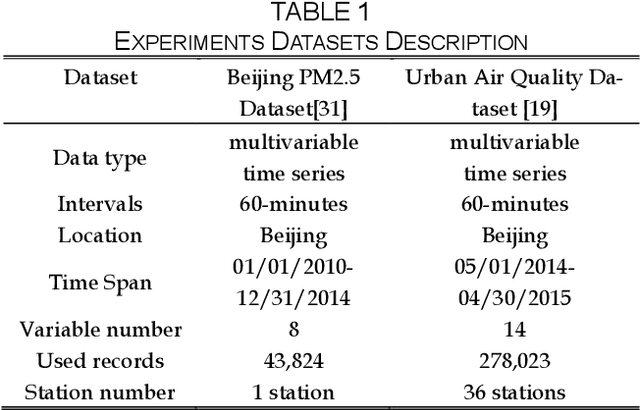
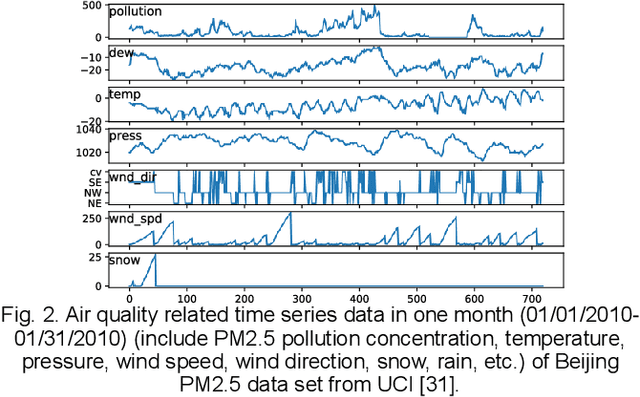
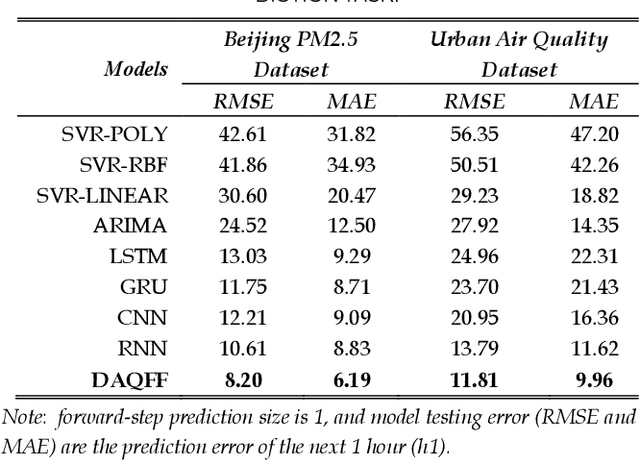
Air quality forecasting has been regarded as the key problem of air pollution early warning and control management. In this paper, we propose a novel deep learning model for air quality (mainly PM2.5) forecasting, which learns the spatial-temporal correlation features and interdependence of multivariate air quality related time series data by hybrid deep learning architecture. Due to the nonlinear and dynamic characteristics of multivariate air quality time series data, the base modules of our model include one-dimensional Convolutional Neural Networks (CNN) and Bi-directional Long Short-term Memory networks (Bi-LSTM). The former is to extract the local trend features and the latter is to learn long temporal dependencies. Then we design a jointly hybrid deep learning framework which based on one-dimensional CNN and Bi-LSTM for shared representation features learning of multivariate air quality related time series data. The experiment results show that our model is capable of dealing with PM2.5 air pollution forecasting with satisfied accuracy.