 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Pre-trained Data Deduplication Model based on Active Learning
Paper and Code
Jul 31, 2023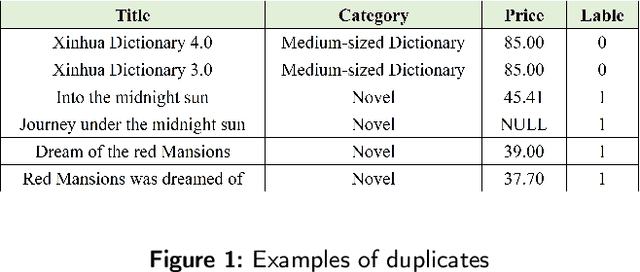

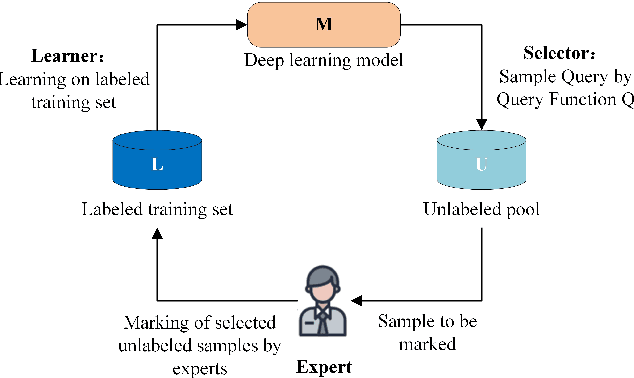

In the era of big data, the issue of data quality has become increasingly prominent. One of the main challenges is the problem of duplicate data, which can arise from repeated entry or the merging of multiple data sources. These "dirty data" problems can significantly limit the effective application of big data. To address the issue of data deduplication, we propose a pre-trained deduplication model based on active learning, which is the first work that utilizes active learning to address the problem of deduplication at the semantic level. The model is built on a pre-trained Transformer and fine-tuned to solve the deduplication problem as a sequence to classification task, which firstly integrate the transformer with active learning into an end-to-end architecture to select the most valuable data for deduplication model training, and also firstly employ the R-Drop method to perform data augmentation on each round of labeled data, which can reduce the cost of manual labeling and improve the model's performance. Experimental results demonstrate that our proposed model outperforms previous state-of-the-art (SOTA) for deduplicated data identification, achieving up to a 28% improvement in Recall score on benchmark datasets.