 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRAformer: Differentially Reconstructed Attention Transformer for Time-Series Forecasting
Jun 11, 2022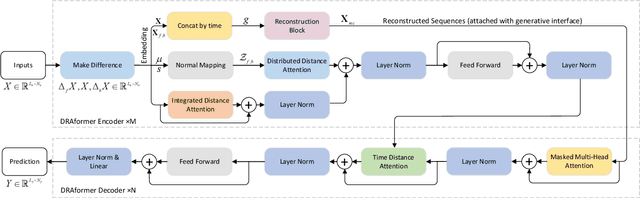
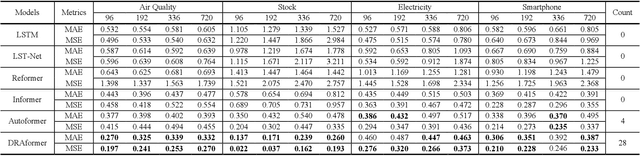
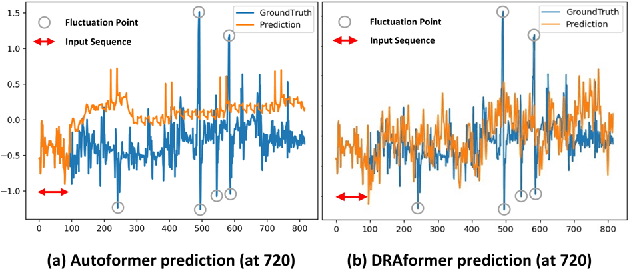

Time-series forecasting plays an important role in many real-world scenarios, such as equipment life cycle forecasting, weather forecasting, and traffic flow forecasting. It can be observed from recent research that a variety of transformer-based models have shown remarkable results in time-series forecasting. However, there are still some issues that limit the ability of transformer-based models on time-series forecasting tasks: (i) learning directly on raw data is susceptible to noise due to its complex and unstable feature representation; (ii) the self-attention mechanisms pay insufficient attention to changing features and temporal dependencies. In order to solve these two problems, we propose a transformer-based differentially reconstructed attention model DRAformer. Specifically, DRAformer has the following innovations: (i) learning against differenced sequences, which preserves clear and stable sequence features by differencing and highlights the changing properties of sequences; (ii) the reconstructed attention: integrated distance attention exhibits sequential distance through a learnable Gaussian kernel, distributed difference attention calculates distribution difference by mapping the difference sequence to the adaptive feature space, and the combination of the two effectively focuses on the sequences with prominent associations; (iii) the reconstructed decoder input, which extracts sequence features by integrating variation information and temporal correlations, thereby obtaining a more comprehensive sequence representation. Extensive experiments on four large-scale datasets demonstrate that DRAformer outperforms state-of-the-art baselines.
A Differential Attention Fusion Model Based on Transformer for Time Series Forecasting
Feb 23, 2022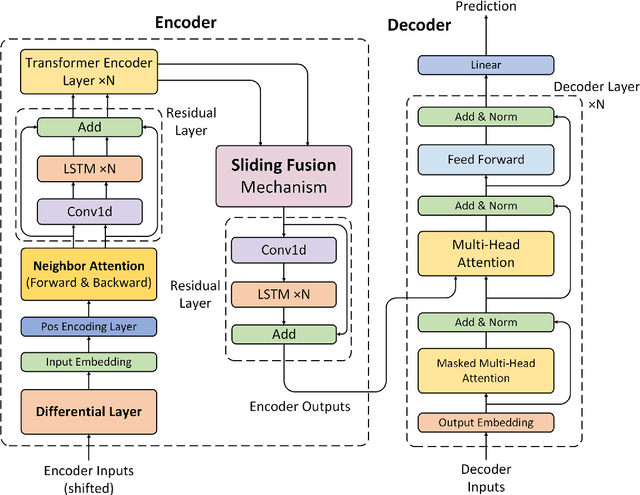
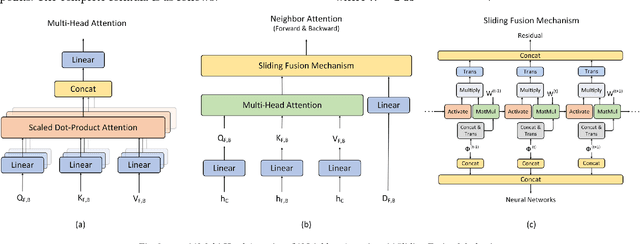
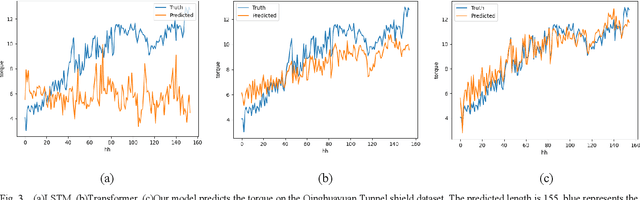
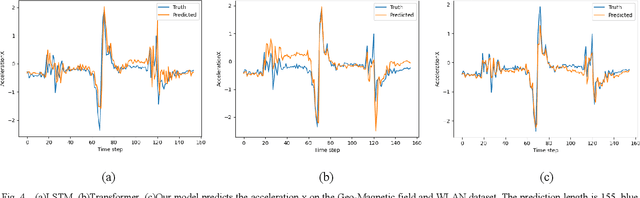
Time series forecasting is widely used in the fields of equipment life cycle forecasting, weather forecasting, traffic flow forecasting, and other fields. Recently, some scholars have tried to apply Transformer to time series forecasting because of its powerful parallel training ability. However, the existing Transformer methods do not pay enough attention to the small time segments that play a decisive role in prediction, making it insensitive to small changes that affect the trend of time series, and it is difficult to effectively learn continuous time-dependent features. To solve this problem, we propose a differential attention fusion model based on Transformer, which designs the differential layer, neighbor attention, sliding fusion mechanism, and residual layer on the basis of classical Transformer architecture. Specifically, the differences of adjacent time points are extracted and focused by difference and neighbor attention. The sliding fusion mechanism fuses various features of each time point so that the data can participate in encoding and decoding without losing important information. The residual layer including convolution and LSTM further learns the dependence between time points and enables our model to carry out deeper training. A large number of experiments on three datasets show that the prediction results produced by our method are favorably comparable to the state-of-the-art.