 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThree-Stream Convolutional Networks for Video-based Person Re-Identification
Paper and Code
Nov 22, 2017


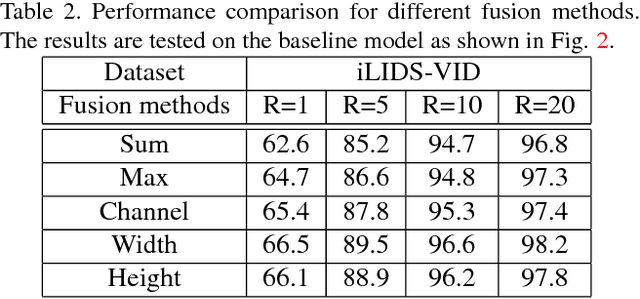
This paper aims to develop a new architecture that can make full use of the feature maps of convolutional networks. To this end, we study a number of methods for video-based person re-identification and make the following findings: 1) Max-pooling only focuses on the maximum value of a receptive field, wasting a lot of information. 2) Networks with different streams even including the one with the worst performance work better than networks with same streams, where each one has the best performance alone. 3) A full connection layer at the end of convolutional networks is not necessary. Based on these studies, we propose a new convolutional architecture termed Three-Stream Convolutional Networks (TSCN). It first uses different streams to learn different aspects of feature maps for attentive spatio-temporal fusion of video, and then merges them together to study some union features. To further utilize the feature maps, two architectures are designed by using the strategies of multi-scale and upsampling. Comparative experiments on iLIDS-VID, PRID-2011 and MARS datasets illustrate that the proposed architectures are significantly better for feature extraction than the state-of-the-art models.