 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistency-guided semi-supervised outlier detection in heterogeneous data using fuzzy rough sets
Dec 22, 2025Outlier detection aims to find samples that behave differently from the majority of the data. Semi-supervised detection methods can utilize the supervision of partial labels, thus reducing false positive rates. However, most of the current semi-supervised methods focus on numerical data and neglect the heterogeneity of data information. In this paper, we propose a consistency-guided outlier detection algorithm (COD) for heterogeneous data with the fuzzy rough set theory in a semi-supervised manner. First, a few labeled outliers are leveraged to construct label-informed fuzzy similarity relations. Next, the consistency of the fuzzy decision system is introduced to evaluate attributes' contributions to knowledge classification. Subsequently, we define the outlier factor based on the fuzzy similarity class and predict outliers by integrating the classification consistency and the outlier factor. The proposed algorithm is extensively evaluated on 15 freshly proposed datasets. Experimental results demonstrate that COD is better than or comparable with the leading outlier detectors. This manuscript is the accepted author version of a paper published by Elsevier. The final published version is available at https://doi.org/10.1016/j.asoc.2024.112070
* Author's Accepted Manuscript
Label-Informed Outlier Detection Based on Granule Density
Dec 21, 2025
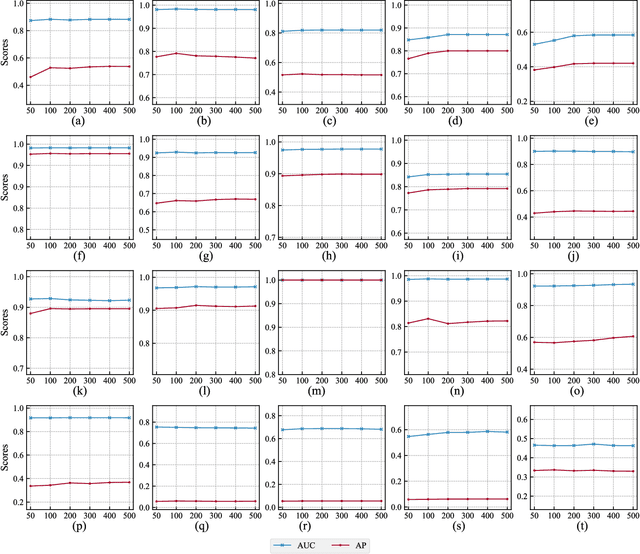


Outlier detection, crucial for identifying unusual patterns with significant implications across numerous applications, has drawn considerable research interest. Existing semi-supervised methods typically treat data as purely numerical and} in a deterministic manner, thereby neglecting the heterogeneity and uncertainty inherent in complex, real-world datasets. This paper introduces a label-informed outlier detection method for heterogeneous data based on Granular Computing and Fuzzy Sets, namely Granule Density-based Outlier Factor (GDOF). Specifically, GDOF first employs label-informed fuzzy granulation to effectively represent various data types and develops granule density for precise density estimation. Subsequently, granule densities from individual attributes are integrated for outlier scoring by assessing attribute relevance with a limited number of labeled outliers. Experimental results on various real-world datasets show that GDOF stands out in detecting outliers in heterogeneous data with a minimal number of labeled outliers. The integration of Fuzzy Sets and Granular Computing in GDOF offers a practical framework for outlier detection in complex and diverse data types. All relevant datasets and source codes are publicly available for further research. This is the author's accepted manuscript of a paper published in IEEE Transactions on Fuzzy Systems. The final version is available at https://doi.org/10.1109/TFUZZ.2024.3514853
* Author's Accepted Manuscript
Unsupervised feature selection via self-paced learning and low-redundant regularization
Dec 14, 2021
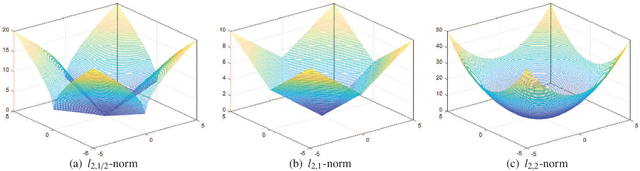
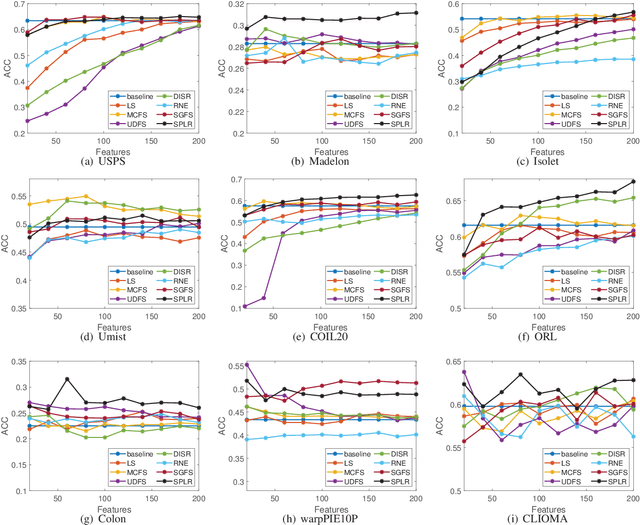
Much more attention has been paid to unsupervised feature selection nowadays due to the emergence of massive unlabeled data. The distribution of samples and the latent effect of training a learning method using samples in more effective order need to be considered so as to improve the robustness of the method. Self-paced learning is an effective method considering the training order of samples. In this study, an unsupervised feature selection is proposed by integrating the framework of self-paced learning and subspace learning. Moreover, the local manifold structure is preserved and the redundancy of features is constrained by two regularization terms. $L_{2,1/2}$-norm is applied to the projection matrix, which aims to retain discriminative features and further alleviate the effect of noise in the data. Then, an iterative method is presented to solve the optimization problem. The convergence of the method is proved theoretically and experimentally. The proposed method is compared with other state of the art algorithms on nine real-world datasets. The experimental results show that the proposed method can improve the performance of clustering methods and outperform other compared algorithms.
Reconstruction of Hidden Representation for Robust Feature Extraction
Oct 23, 2018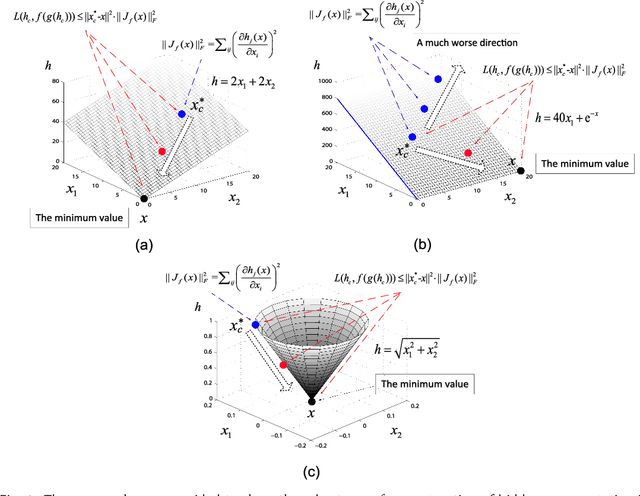
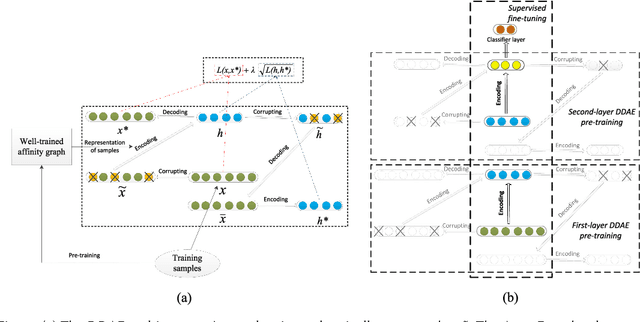
This paper aims to develop a new and robust approach to feature representation. Motivated by the success of Auto-Encoders, we first theoretical summarize the general properties of all algorithms that are based on traditional Auto-Encoders: 1) The reconstruction error of the input can not be lower than a lower bound, which can be viewed as a guiding principle for reconstructing the input. Additionally, when the input is corrupted with noises, the reconstruction error of the corrupted input also can not be lower than a lower bound. 2) The reconstruction of a hidden representation achieving its ideal situation is the necessary condition for the reconstruction of the input to reach the ideal state. 3) Minimizing the Frobenius norm of the Jacobian matrix of the hidden representation has a deficiency and may result in a much worse local optimum value. We believe that minimizing the reconstruction error of the hidden representation is more robust than minimizing the Frobenius norm of the Jacobian matrix of the hidden representation. Based on the above analysis, we propose a new model termed Double Denoising Auto-Encoders (DDAEs), which uses corruption and reconstruction on both the input and the hidden representation. We demonstrate that the proposed model is highly flexible and extensible and has a potentially better capability to learn invariant and robust feature representations. We also show that our model is more robust than Denoising Auto-Encoders (DAEs) for dealing with noises or inessential features. Furthermore, we detail how to train DDAEs with two different pre-training methods by optimizing the objective function in a combined and separate manner, respectively. Comparative experiments illustrate that the proposed model is significantly better for representation learning than the state-of-the-art models.