 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstruction of Hidden Representation for Robust Feature Extraction
Paper and Code
Oct 23, 2018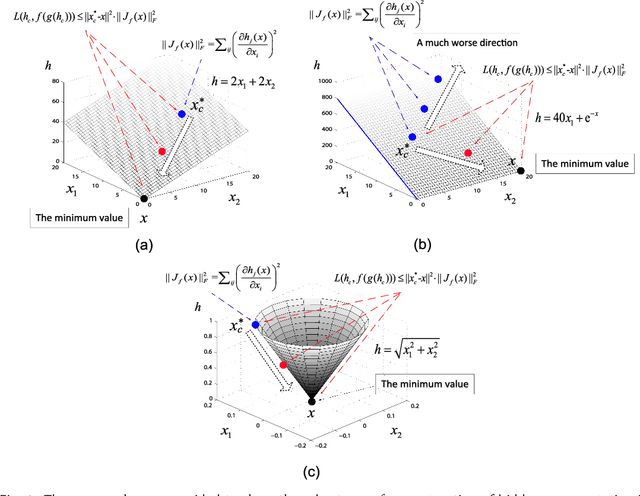
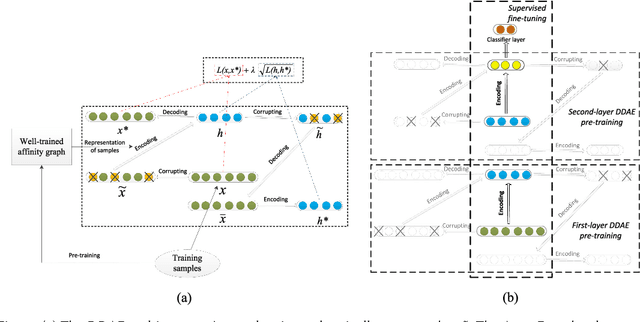
This paper aims to develop a new and robust approach to feature representation. Motivated by the success of Auto-Encoders, we first theoretical summarize the general properties of all algorithms that are based on traditional Auto-Encoders: 1) The reconstruction error of the input can not be lower than a lower bound, which can be viewed as a guiding principle for reconstructing the input. Additionally, when the input is corrupted with noises, the reconstruction error of the corrupted input also can not be lower than a lower bound. 2) The reconstruction of a hidden representation achieving its ideal situation is the necessary condition for the reconstruction of the input to reach the ideal state. 3) Minimizing the Frobenius norm of the Jacobian matrix of the hidden representation has a deficiency and may result in a much worse local optimum value. We believe that minimizing the reconstruction error of the hidden representation is more robust than minimizing the Frobenius norm of the Jacobian matrix of the hidden representation. Based on the above analysis, we propose a new model termed Double Denoising Auto-Encoders (DDAEs), which uses corruption and reconstruction on both the input and the hidden representation. We demonstrate that the proposed model is highly flexible and extensible and has a potentially better capability to learn invariant and robust feature representations. We also show that our model is more robust than Denoising Auto-Encoders (DAEs) for dealing with noises or inessential features. Furthermore, we detail how to train DDAEs with two different pre-training methods by optimizing the objective function in a combined and separate manner, respectively. Comparative experiments illustrate that the proposed model is significantly better for representation learning than the state-of-the-art models.