 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS3T-Former: A Purely Spike-Driven State-Space Topology Transformer for Skeleton Action Recognition
Mar 18, 2026Skeleton-based action recognition is crucial for multimedia applications but heavily relies on power-hungry Artificial Neural Networks (ANNs), limiting their deployment on resource-constrained edge devices. Spiking Neural Networks (SNNs) provide an energy-efficient alternative; however, existing spiking models for skeleton data often compromise the intrinsic sparsity of SNNs by resorting to dense matrix aggregations, heavy multimodal fusion modules, or non-sparse frequency domain transformations. Furthermore, they severely suffer from the short-term amnesia of spiking neurons. In this paper, we propose the Spiking State-Space Topology Transformer (S3T-Former), which, to the best of our knowledge, is the first purely spike-driven Transformer architecture specifically designed for energy-efficient skeleton action recognition. Rather than relying on heavy fusion overhead, we formulate a Multi-Stream Anatomical Spiking Embedding (M-ASE) that acts as a generalized kinematic differential operator, elegantly transforming multimodal skeleton features into heterogeneous, highly sparse event streams. To achieve true topological and temporal sparsity, we introduce Lateral Spiking Topology Routing (LSTR) for on-demand conditional spike propagation, and a Spiking State-Space (S3) Engine to systematically capture long-range temporal dynamics without non-sparse spectral workarounds. Extensive experiments on multiple large-scale datasets demonstrate that S3T-Former achieves highly competitive accuracy while theoretically reducing energy consumption compared to classic ANNs, establishing a new state-of-the-art for energy-efficient neuromorphic action recognition.
Signal-SGN++: Topology-Enhanced Time-Frequency Spiking Graph Network for Skeleton-Based Action Recognition
Dec 22, 2025Graph Convolutional Networks (GCNs) demonstrate strong capability in modeling skeletal topology for action recognition, yet their dense floating-point computations incur high energy costs. Spiking Neural Networks (SNNs), characterized by event-driven and sparse activation, offer energy efficiency but remain limited in capturing coupled temporal-frequency and topological dependencies of human motion. To bridge this gap, this article proposes Signal-SGN++, a topology-aware spiking graph framework that integrates structural adaptivity with time-frequency spiking dynamics. The network employs a backbone composed of 1D Spiking Graph Convolution (1D-SGC) and Frequency Spiking Convolution (FSC) for joint spatiotemporal and spectral feature extraction. Within this backbone, a Topology-Shift Self-Attention (TSSA) mechanism is embedded to adaptively route attention across learned skeletal topologies, enhancing graph-level sensitivity without increasing computational complexity. Moreover, an auxiliary Multi-Scale Wavelet Transform Fusion (MWTF) branch decomposes spiking features into multi-resolution temporal-frequency representations, wherein a Topology-Aware Time-Frequency Fusion (TATF) unit incorporates structural priors to preserve topology-consistent spectral fusion. Comprehensive experiments on large-scale benchmarks validate that Signal-SGN++ achieves superior accuracy-efficiency trade-offs, outperforming existing SNN-based methods and achieving competitive results against state-of-the-art GCNs under substantially reduced energy consumption.
Unsupervised feature selection via self-paced learning and low-redundant regularization
Dec 14, 2021
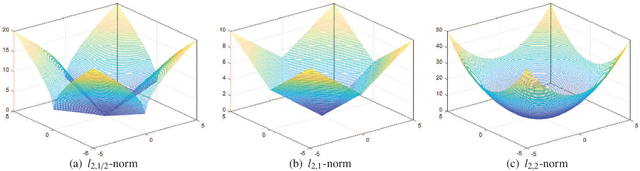
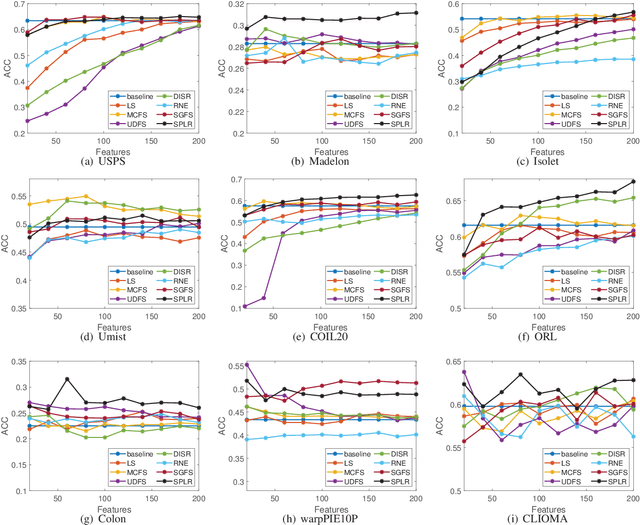
Much more attention has been paid to unsupervised feature selection nowadays due to the emergence of massive unlabeled data. The distribution of samples and the latent effect of training a learning method using samples in more effective order need to be considered so as to improve the robustness of the method. Self-paced learning is an effective method considering the training order of samples. In this study, an unsupervised feature selection is proposed by integrating the framework of self-paced learning and subspace learning. Moreover, the local manifold structure is preserved and the redundancy of features is constrained by two regularization terms. $L_{2,1/2}$-norm is applied to the projection matrix, which aims to retain discriminative features and further alleviate the effect of noise in the data. Then, an iterative method is presented to solve the optimization problem. The convergence of the method is proved theoretically and experimentally. The proposed method is compared with other state of the art algorithms on nine real-world datasets. The experimental results show that the proposed method can improve the performance of clustering methods and outperform other compared algorithms.
SMOF: Squeezing More Out of Filters Yields Hardware-Friendly CNN Pruning
Oct 21, 2021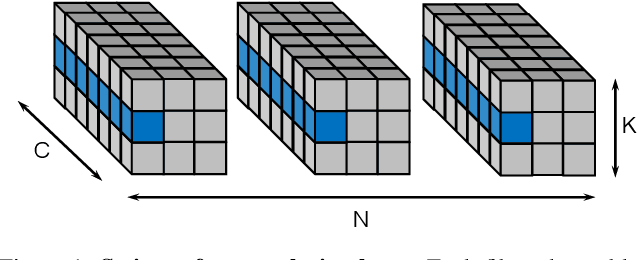
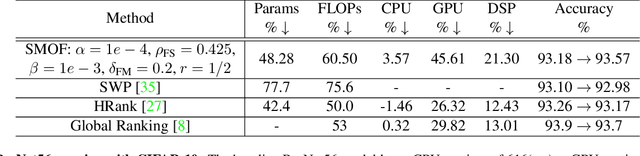
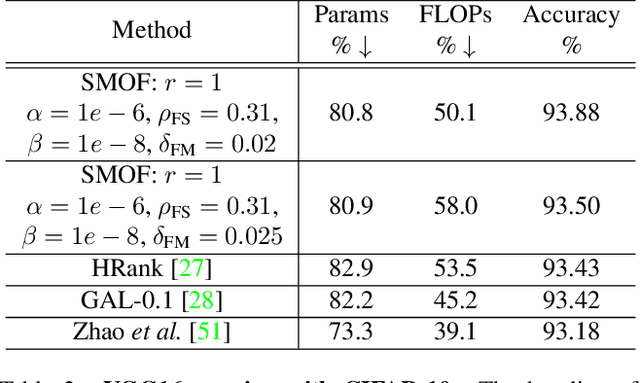
For many years, the family of convolutional neural networks (CNNs) has been a workhorse in deep learning. Recently, many novel CNN structures have been designed to address increasingly challenging tasks. To make them work efficiently on edge devices, researchers have proposed various structured network pruning strategies to reduce their memory and computational cost. However, most of them only focus on reducing the number of filter channels per layer without considering the redundancy within individual filter channels. In this work, we explore pruning from another dimension, the kernel size. We develop a CNN pruning framework called SMOF, which Squeezes More Out of Filters by reducing both kernel size and the number of filter channels. Notably, SMOF is friendly to standard hardware devices without any customized low-level implementations, and the pruning effort by kernel size reduction does not suffer from the fixed-size width constraint in SIMD units of general-purpose processors. The pruned networks can be deployed effortlessly with significant running time reduction. We also support these claims via extensive experiments on various CNN structures and general-purpose processors for mobile devices.