 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Fidelity Relightable Monocular Portrait Animation with Lighting-Controllable Video Diffusion Model
Feb 27, 2025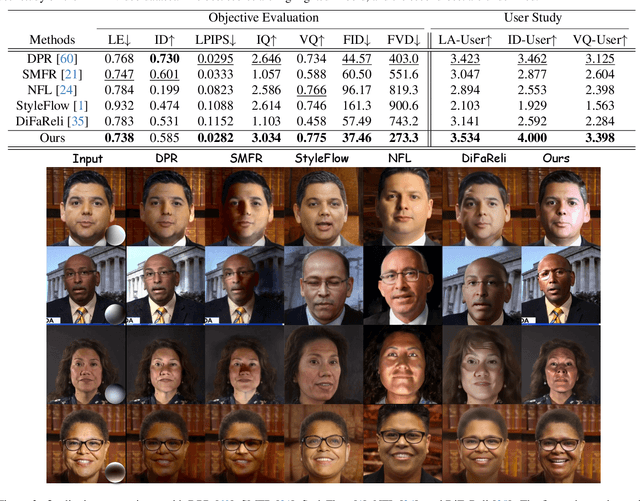
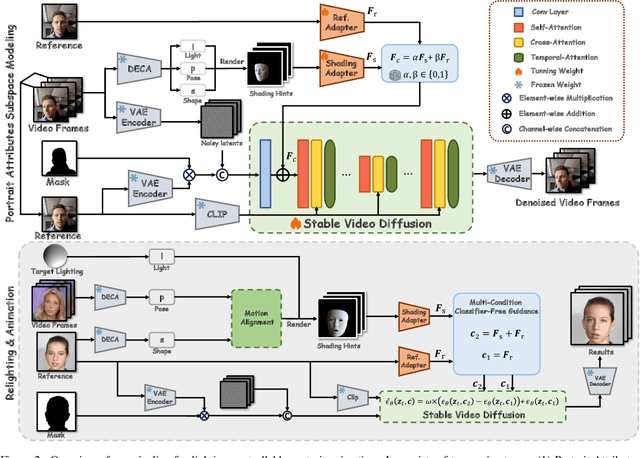
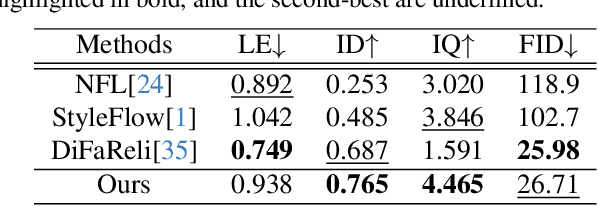
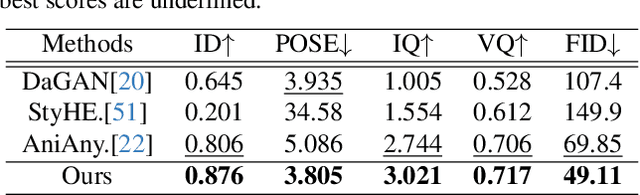
Relightable portrait animation aims to animate a static reference portrait to match the head movements and expressions of a driving video while adapting to user-specified or reference lighting conditions. Existing portrait animation methods fail to achieve relightable portraits because they do not separate and manipulate intrinsic (identity and appearance) and extrinsic (pose and lighting) features. In this paper, we present a Lighting Controllable Video Diffusion model (LCVD) for high-fidelity, relightable portrait animation. We address this limitation by distinguishing these feature types through dedicated subspaces within the feature space of a pre-trained image-to-video diffusion model. Specifically, we employ the 3D mesh, pose, and lighting-rendered shading hints of the portrait to represent the extrinsic attributes, while the reference represents the intrinsic attributes. In the training phase, we employ a reference adapter to map the reference into the intrinsic feature subspace and a shading adapter to map the shading hints into the extrinsic feature subspace. By merging features from these subspaces, the model achieves nuanced control over lighting, pose, and expression in generated animations. Extensive evaluations show that LCVD outperforms state-of-the-art methods in lighting realism, image quality, and video consistency, setting a new benchmark in relightable portrait animation.
Deep Learning-based Image and Video Inpainting: A Survey
Jan 07, 2024Image and video inpainting is a classic problem in computer vision and computer graphics, aiming to fill in the plausible and realistic content in the missing areas of images and videos. With the advance of deep learning, this problem has achieved significant progress recently. The goal of this paper is to comprehensively review the deep learning-based methods for image and video inpainting. Specifically, we sort existing methods into different categories from the perspective of their high-level inpainting pipeline, present different deep learning architectures, including CNN, VAE, GAN, diffusion models, etc., and summarize techniques for module design. We review the training objectives and the common benchmark datasets. We present evaluation metrics for low-level pixel and high-level perceptional similarity, conduct a performance evaluation, and discuss the strengths and weaknesses of representative inpainting methods. We also discuss related real-world applications. Finally, we discuss open challenges and suggest potential future research directions.
FreeControl: Training-Free Spatial Control of Any Text-to-Image Diffusion Model with Any Condition
Dec 12, 2023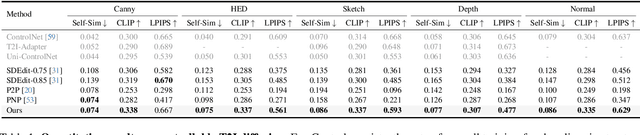
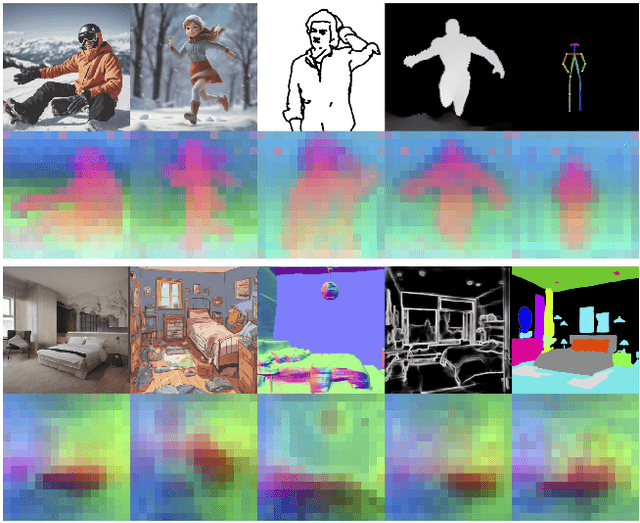
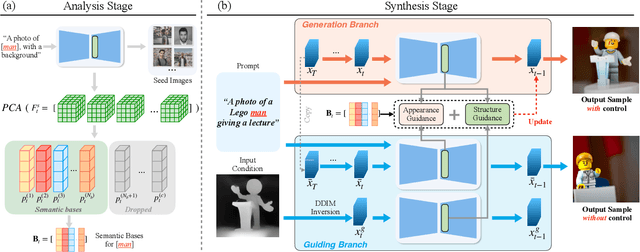

Recent approaches such as ControlNet offer users fine-grained spatial control over text-to-image (T2I) diffusion models. However, auxiliary modules have to be trained for each type of spatial condition, model architecture, and checkpoint, putting them at odds with the diverse intents and preferences a human designer would like to convey to the AI models during the content creation process. In this work, we present FreeControl, a training-free approach for controllable T2I generation that supports multiple conditions, architectures, and checkpoints simultaneously. FreeControl designs structure guidance to facilitate the structure alignment with a guidance image, and appearance guidance to enable the appearance sharing between images generated using the same seed. Extensive qualitative and quantitative experiments demonstrate the superior performance of FreeControl across a variety of pre-trained T2I models. In particular, FreeControl facilitates convenient training-free control over many different architectures and checkpoints, allows the challenging input conditions on which most of the existing training-free methods fail, and achieves competitive synthesis quality with training-based approaches.
Vision Backbone Enhancement via Multi-Stage Cross-Scale Attention
Aug 14, 2023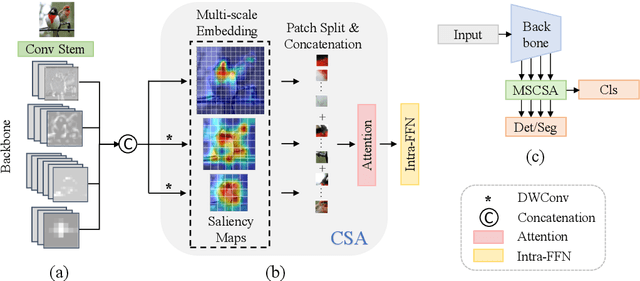



Convolutional neural networks (CNNs) and vision transformers (ViTs) have achieved remarkable success in various vision tasks. However, many architectures do not consider interactions between feature maps from different stages and scales, which may limit their performance. In this work, we propose a simple add-on attention module to overcome these limitations via multi-stage and cross-scale interactions. Specifically, the proposed Multi-Stage Cross-Scale Attention (MSCSA) module takes feature maps from different stages to enable multi-stage interactions and achieves cross-scale interactions by computing self-attention at different scales based on the multi-stage feature maps. Our experiments on several downstream tasks show that MSCSA provides a significant performance boost with modest additional FLOPs and runtime.
SimHaze: game engine simulated data for real-world dehazing
May 25, 2023Deep models have demonstrated recent success in single-image dehazing. Most prior methods consider fully supervised training and learn from paired clean and hazy images, where a hazy image is synthesized based on a clean image and its estimated depth map. This paradigm, however, can produce low-quality hazy images due to inaccurate depth estimation, resulting in poor generalization of the trained models. In this paper, we explore an alternative approach for generating paired clean-hazy images by leveraging computer graphics. Using a modern game engine, our approach renders crisp clean images and their precise depth maps, based on which high-quality hazy images can be synthesized for training dehazing models. To this end, we present SimHaze: a new synthetic haze dataset. More importantly, we show that training with SimHaze alone allows the latest dehazing models to achieve significantly better performance in comparison to previous dehazing datasets. Our dataset and code will be made publicly available.
An Improved Analysis of Policy Gradient and Natural Policy Gradient Methods
Nov 16, 2022
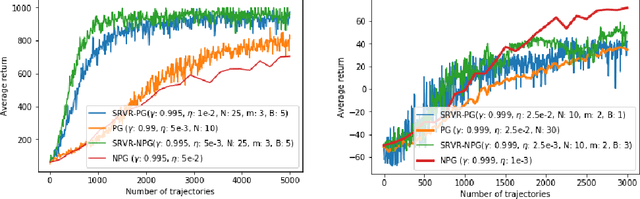
In this paper, we revisit and improve the convergence of policy gradient (PG), natural PG (NPG) methods, and their variance-reduced variants, under general smooth policy parametrizations. More specifically, with the Fisher information matrix of the policy being positive definite: i) we show that a state-of-the-art variance-reduced PG method, which has only been shown to converge to stationary points, converges to the globally optimal value up to some inherent function approximation error due to policy parametrization; ii) we show that NPG enjoys a lower sample complexity; iii) we propose SRVR-NPG, which incorporates variance-reduction into the NPG update. Our improvements follow from an observation that the convergence of (variance-reduced) PG and NPG methods can improve each other: the stationary convergence analysis of PG can be applied to NPG as well, and the global convergence analysis of NPG can help to establish the global convergence of (variance-reduced) PG methods. Our analysis carefully integrates the advantages of these two lines of works. Thanks to this improvement, we have also made variance-reduction for NPG possible, with both global convergence and an efficient finite-sample complexity.
* NeurIPS 2020 (improve the proof of Lemma B.1 and Proposition G.1.)
Hybrid Learning with New Value Function for the Maximum Common Subgraph Problem
Aug 18, 2022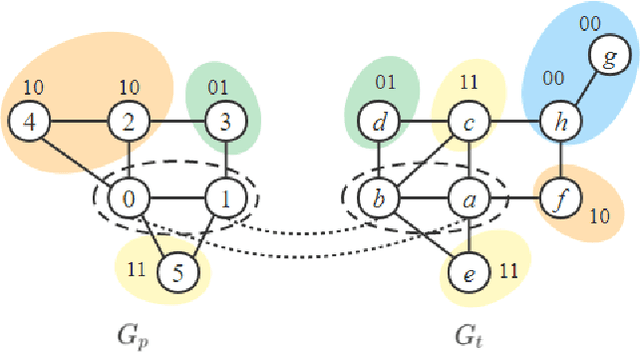
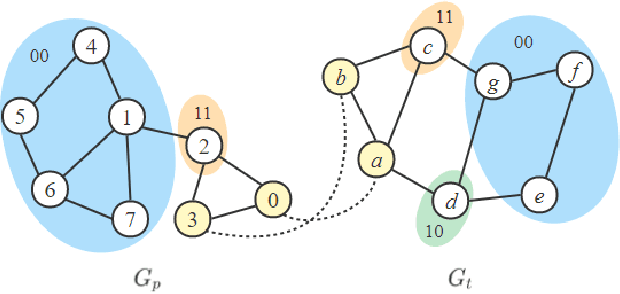
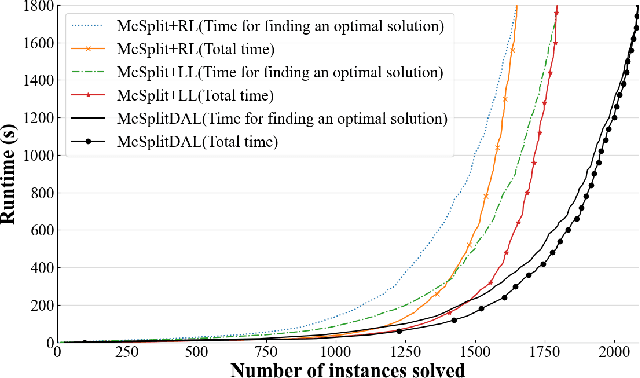
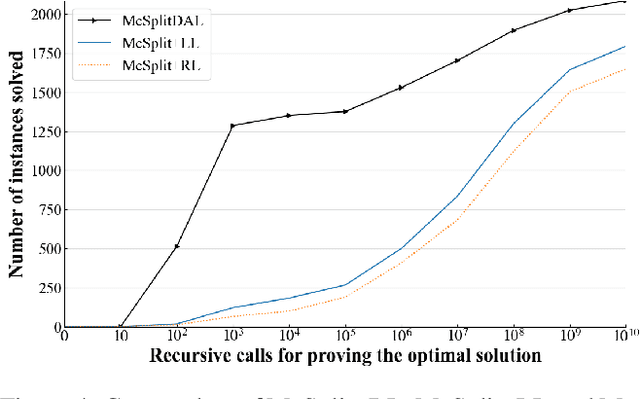
Maximum Common induced Subgraph (MCS) is an important NP-hard problem with wide real-world applications. Branch-and-Bound (BnB) is the basis of a class of efficient algorithms for MCS, consisting in successively selecting vertices to match and pruning when it is discovered that a solution better than the best solution found so far does not exist. The method of selecting the vertices to match is essential for the performance of BnB. In this paper, we propose a new value function and a hybrid selection strategy used in reinforcement learning to define a new vertex selection method, and propose a new BnB algorithm, called McSplitDAL, for MCS. Extensive experiments show that McSplitDAL significantly improves the current best BnB algorithms, McSplit+LL and McSplit+RL. An empirical analysis is also performed to illustrate why the new value function and the hybrid selection strategy are effective.
SMOF: Squeezing More Out of Filters Yields Hardware-Friendly CNN Pruning
Oct 21, 2021
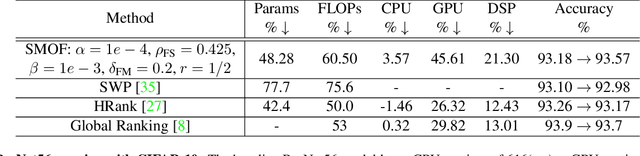
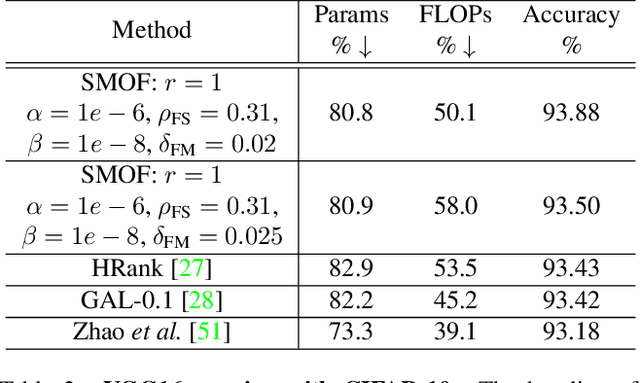
For many years, the family of convolutional neural networks (CNNs) has been a workhorse in deep learning. Recently, many novel CNN structures have been designed to address increasingly challenging tasks. To make them work efficiently on edge devices, researchers have proposed various structured network pruning strategies to reduce their memory and computational cost. However, most of them only focus on reducing the number of filter channels per layer without considering the redundancy within individual filter channels. In this work, we explore pruning from another dimension, the kernel size. We develop a CNN pruning framework called SMOF, which Squeezes More Out of Filters by reducing both kernel size and the number of filter channels. Notably, SMOF is friendly to standard hardware devices without any customized low-level implementations, and the pruning effort by kernel size reduction does not suffer from the fixed-size width constraint in SIMD units of general-purpose processors. The pruned networks can be deployed effortlessly with significant running time reduction. We also support these claims via extensive experiments on various CNN structures and general-purpose processors for mobile devices.