 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Fidelity Relightable Monocular Portrait Animation with Lighting-Controllable Video Diffusion Model
Feb 27, 2025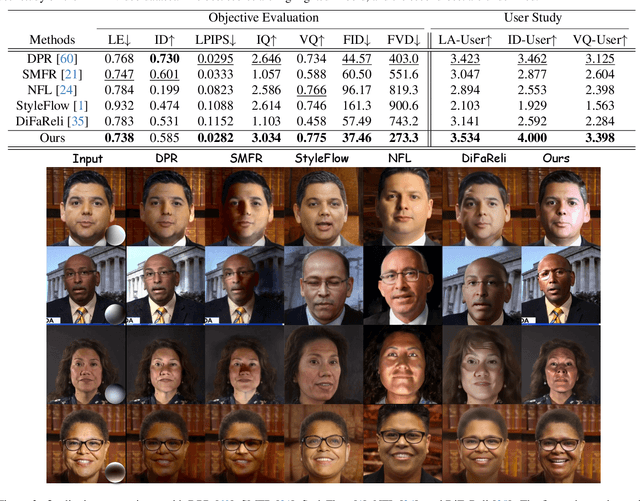
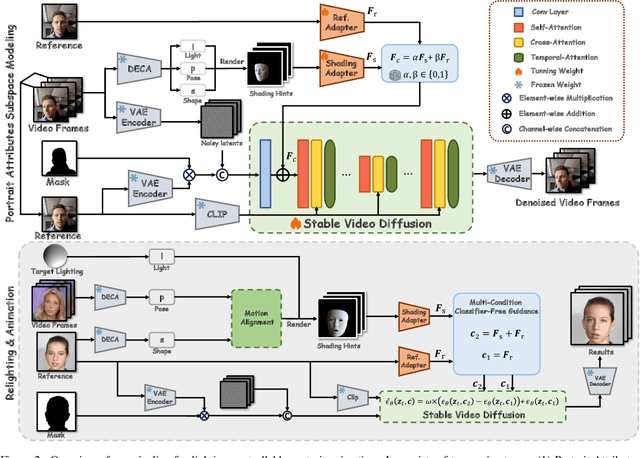
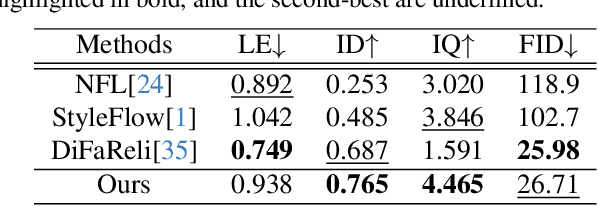
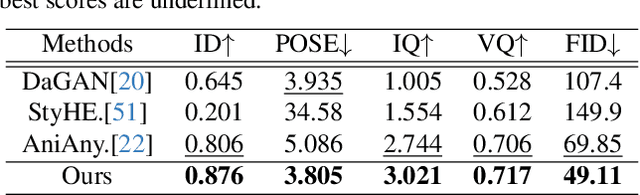
Relightable portrait animation aims to animate a static reference portrait to match the head movements and expressions of a driving video while adapting to user-specified or reference lighting conditions. Existing portrait animation methods fail to achieve relightable portraits because they do not separate and manipulate intrinsic (identity and appearance) and extrinsic (pose and lighting) features. In this paper, we present a Lighting Controllable Video Diffusion model (LCVD) for high-fidelity, relightable portrait animation. We address this limitation by distinguishing these feature types through dedicated subspaces within the feature space of a pre-trained image-to-video diffusion model. Specifically, we employ the 3D mesh, pose, and lighting-rendered shading hints of the portrait to represent the extrinsic attributes, while the reference represents the intrinsic attributes. In the training phase, we employ a reference adapter to map the reference into the intrinsic feature subspace and a shading adapter to map the shading hints into the extrinsic feature subspace. By merging features from these subspaces, the model achieves nuanced control over lighting, pose, and expression in generated animations. Extensive evaluations show that LCVD outperforms state-of-the-art methods in lighting realism, image quality, and video consistency, setting a new benchmark in relightable portrait animation.
CGGAN: A Context Guided Generative Adversarial Network For Single Image Dehazing
May 28, 2020
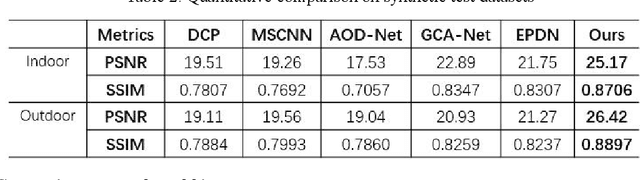
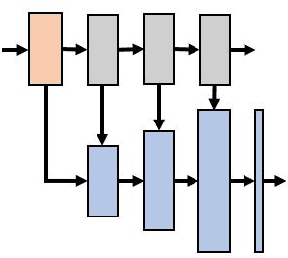
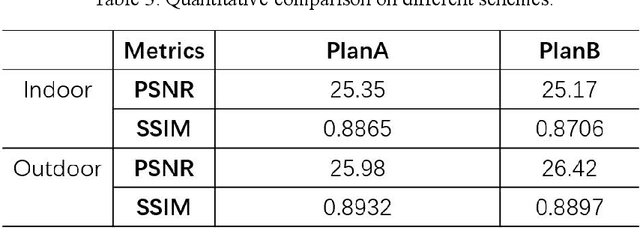
Image haze removal is highly desired for the application of computer vision. This paper proposes a novel Context Guided Generative Adversarial Network (CGGAN) for single image dehazing. Of which, an novel new encoder-decoder is employed as the generator. And it consists of a feature-extraction-net, a context-extractionnet, and a fusion-net in sequence. The feature extraction-net acts as a encoder, and is used for extracting haze features. The context-extraction net is a multi-scale parallel pyramid decoder, and is used for extracting the deep features of the encoder and generating coarse dehazing image. The fusion-net is a decoder, and is used for obtaining the final haze-free image. To obtain more better results, multi-scale information obtained during the decoding process of the context extraction decoder is used for guiding the fusion decoder. By introducing an extra coarse decoder to the original encoder-decoder, the CGGAN can make better use of the deep feature information extracted by the encoder. To ensure our CGGAN work effectively for different haze scenarios, different loss functions are employed for the two decoders. Experiments results show the advantage and the effectiveness of our proposed CGGAN, evidential improvements over existing state-of-the-art methods are obtained.