 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Animatable 2DGS-Avatars with Detail Enhancement from Monocular Videos
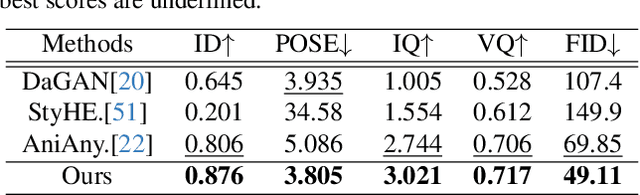
May 01, 2025High-quality, animatable 3D human avatar reconstruction from monocular videos offers significant potential for reducing reliance on complex hardware, making it highly practical for applications in game development, augmented reality, and social media. However, existing methods still face substantial challenges in capturing fine geometric details and maintaining animation stability, particularly under dynamic or complex poses. To address these issues, we propose a novel real-time framework for animatable human avatar reconstruction based on 2D Gaussian Splatting (2DGS). By leveraging 2DGS and global SMPL pose parameters, our framework not only aligns positional and rotational discrepancies but also enables robust and natural pose-driven animation of the reconstructed avatars. Furthermore, we introduce a Rotation Compensation Network (RCN) that learns rotation residuals by integrating local geometric features with global pose parameters. This network significantly improves the handling of non-rigid deformations and ensures smooth, artifact-free pose transitions during animation. Experimental results demonstrate that our method successfully reconstructs realistic and highly animatable human avatars from monocular videos, effectively preserving fine-grained details while ensuring stable and natural pose variation. Our approach surpasses current state-of-the-art methods in both reconstruction quality and animation robustness on public benchmarks.
High-Fidelity Relightable Monocular Portrait Animation with Lighting-Controllable Video Diffusion Model
Feb 27, 2025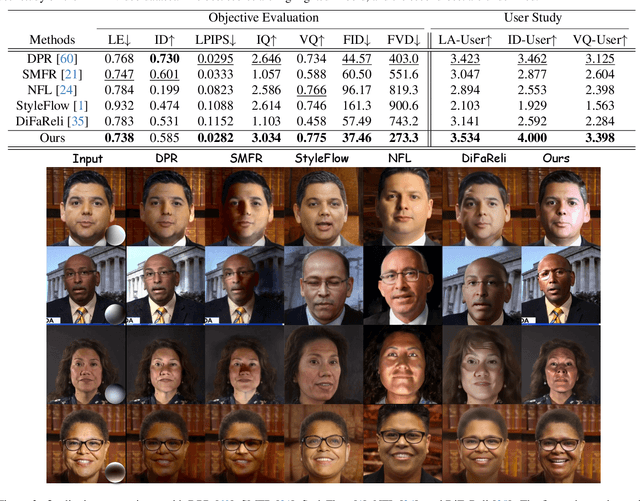
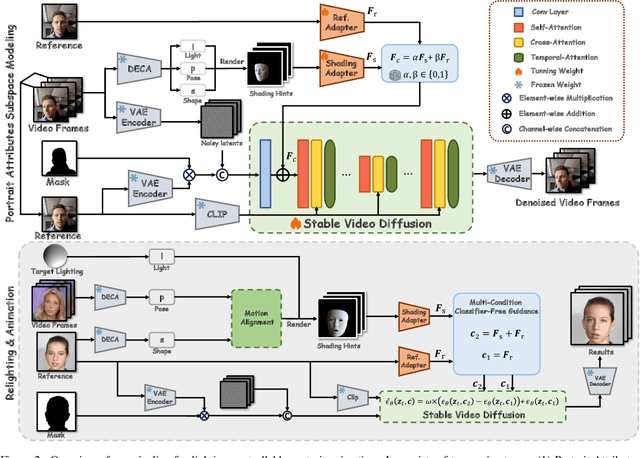
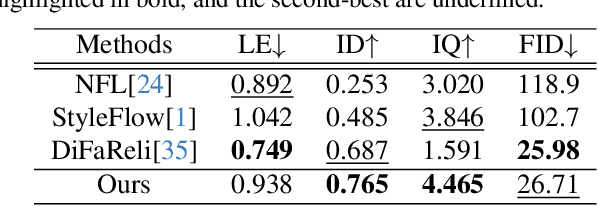
Relightable portrait animation aims to animate a static reference portrait to match the head movements and expressions of a driving video while adapting to user-specified or reference lighting conditions. Existing portrait animation methods fail to achieve relightable portraits because they do not separate and manipulate intrinsic (identity and appearance) and extrinsic (pose and lighting) features. In this paper, we present a Lighting Controllable Video Diffusion model (LCVD) for high-fidelity, relightable portrait animation. We address this limitation by distinguishing these feature types through dedicated subspaces within the feature space of a pre-trained image-to-video diffusion model. Specifically, we employ the 3D mesh, pose, and lighting-rendered shading hints of the portrait to represent the extrinsic attributes, while the reference represents the intrinsic attributes. In the training phase, we employ a reference adapter to map the reference into the intrinsic feature subspace and a shading adapter to map the shading hints into the extrinsic feature subspace. By merging features from these subspaces, the model achieves nuanced control over lighting, pose, and expression in generated animations. Extensive evaluations show that LCVD outperforms state-of-the-art methods in lighting realism, image quality, and video consistency, setting a new benchmark in relightable portrait animation.