 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Explainability and Reliable Decision-Making in Particle Swarm Optimization through Communication Topologies
Apr 17, 2025

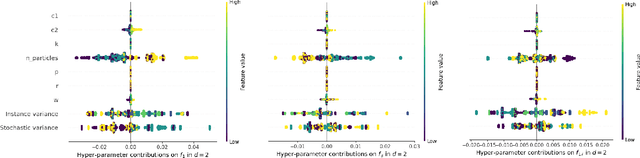

Swarm intelligence effectively optimizes complex systems across fields like engineering and healthcare, yet algorithm solutions often suffer from low reliability due to unclear configurations and hyperparameters. This study analyzes Particle Swarm Optimization (PSO), focusing on how different communication topologies Ring, Star, and Von Neumann affect convergence and search behaviors. Using an adapted IOHxplainer , an explainable benchmarking tool, we investigate how these topologies influence information flow, diversity, and convergence speed, clarifying the balance between exploration and exploitation. Through visualization and statistical analysis, the research enhances interpretability of PSO's decisions and provides practical guidelines for choosing suitable topologies for specific optimization tasks. Ultimately, this contributes to making swarm based optimization more transparent, robust, and trustworthy.
Building Interval Type-2 Fuzzy Membership Function: A Deck of Cards based Co-constructive Approach
Mar 03, 2025



Since its inception, Fuzzy Set has been widely used to handle uncertainty and imprecision in decision-making. However, conventional fuzzy sets, often referred to as type-1 fuzzy sets (T1FSs) have limitations in capturing higher levels of uncertainty, particularly when decision-makers (DMs) express hesitation or ambiguity in membership degree. To address this, Interval Type-2 Fuzzy Sets (IT2FSs) have been introduced by incorporating uncertainty in membership degree allocation, which enhanced flexibility in modelling subjective judgments. Despite their advantages, existing IT2FS construction methods often lack active involvement from DMs and that limits the interpretability and effectiveness of decision models. This study proposes a socio-technical co-constructive approach for developing IT2FS models of linguistic terms by facilitating the active involvement of DMs in preference elicitation and its application in multicriteria decision-making (MCDM) problems. Our methodology is structured in two phases. The first phase involves an interactive process between the DM and the decision analyst, in which a modified version of Deck-of-Cards (DoC) method is proposed to construct T1FS membership functions on a ratio scale. We then extend this method to incorporate ambiguity in subjective judgment and that resulted in an IT2FS model that better captures uncertainty in DM's linguistic assessments. The second phase formalizes the constructed IT2FS model for application in MCDM by defining an appropriate mathematical representation of such information, aggregation rules, and an admissible ordering principle. The proposed framework enhances the reliability and effectiveness of fuzzy decision-making not only by accurately representing DM's personalized semantics of linguistic information.
Creating Synthetic Datasets for Collaborative Filtering Recommender Systems using Generative Adversarial Networks
Mar 02, 2023



Research and education in machine learning needs diverse, representative, and open datasets that contain sufficient samples to handle the necessary training, validation, and testing tasks. Currently, the Recommender Systems area includes a large number of subfields in which accuracy and beyond accuracy quality measures are continuously improved. To feed this research variety, it is necessary and convenient to reinforce the existing datasets with synthetic ones. This paper proposes a Generative Adversarial Network (GAN)-based method to generate collaborative filtering datasets in a parameterized way, by selecting their preferred number of users, items, samples, and stochastic variability. This parameterization cannot be made using regular GANs. Our GAN model is fed with dense, short, and continuous embedding representations of items and users, instead of sparse, large, and discrete vectors, to make an accurate and quick learning, compared to the traditional approach based on large and sparse input vectors. The proposed architecture includes a DeepMF model to extract the dense user and item embeddings, as well as a clustering process to convert from the dense GAN generated samples to the discrete and sparse ones, necessary to create each required synthetic dataset. The results of three different source datasets show adequate distributions and expected quality values and evolutions on the generated datasets compared to the source ones. Synthetic datasets and source codes are available to researchers.
Managing Multi-Granular Linguistic Distribution Assessments in Large-Scale Multi-Attribute Group Decision Making
Nov 18, 2015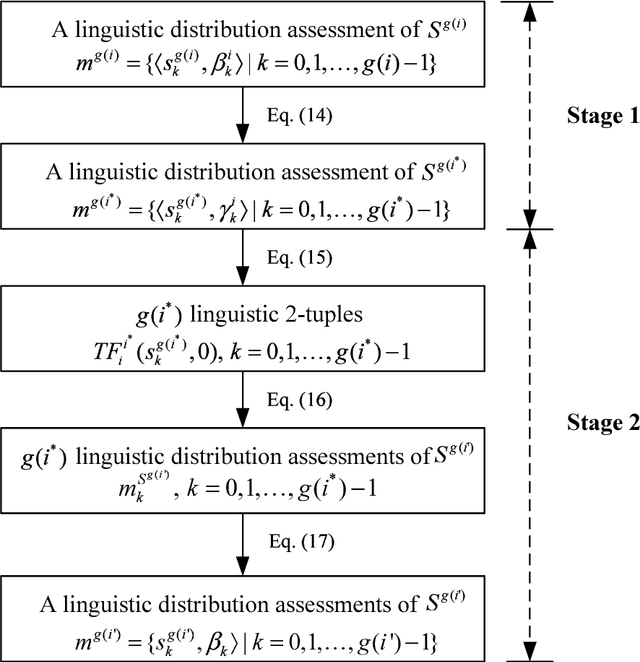
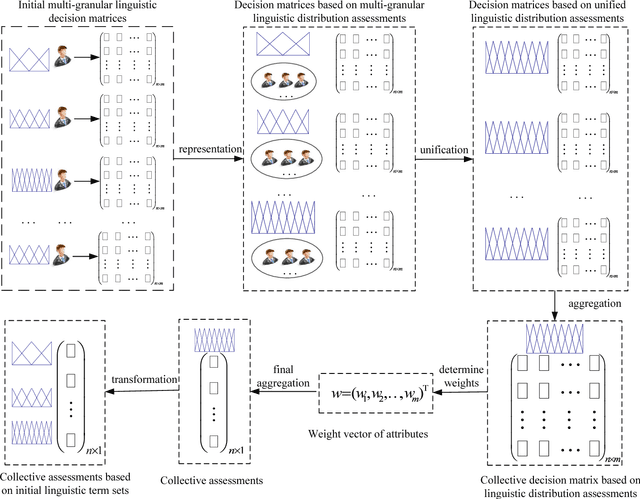


Linguistic large-scale group decision making (LGDM) problems are more and more common nowadays. In such problems a large group of decision makers are involved in the decision process and elicit linguistic information that are usually assessed in different linguistic scales with diverse granularity because of decision makers' distinct knowledge and background. To keep maximum information in initial stages of the linguistic LGDM problems, the use of multi-granular linguistic distribution assessments seems a suitable choice, however to manage such multigranular linguistic distribution assessments, it is necessary the development of a new linguistic computational approach. In this paper it is proposed a novel computational model based on the use of extended linguistic hierarchies, which not only can be used to operate with multi-granular linguistic distribution assessments, but also can provide interpretable linguistic results to decision makers. Based on this new linguistic computational model, an approach to linguistic large-scale multi-attribute group decision making is proposed and applied to a talent selection process in universities.