 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTesting Deep Learning Recommender Systems Models on Synthetic GAN-Generated Datasets
Oct 23, 2024



The published method Generative Adversarial Networks for Recommender Systems (GANRS) allows generating data sets for collaborative filtering recommendation systems. The GANRS source code is available along with a representative set of generated datasets. We have tested the GANRS method by creating multiple synthetic datasets from three different real datasets taken as a source. Experiments include variations in the number of users in the synthetic datasets, as well as a different number of samples. We have also selected six state-of-the-art collaborative filtering deep learning models to test both their comparative performance and the GANRS method. The results show a consistent behavior of the generated datasets compared to the source ones; particularly, in the obtained values and trends of the precision and recall quality measures. The tested deep learning models have also performed as expected on all synthetic datasets, making it possible to compare the results with those obtained from the real source data. Future work is proposed, including different cold start scenarios, unbalanced data, and demographic fairness.
* 10 pages, 7 figures, In press
Neural Collaborative Filtering Classification Model to Obtain Prediction Reliabilities
Oct 22, 2024Neural collaborative filtering is the state of art field in the recommender systems area; it provides some models that obtain accurate predictions and recommendations. These models are regression-based, and they just return rating predictions. This paper proposes the use of a classification-based approach, returning both rating predictions and their reliabilities. The extra information (prediction reliabilities) can be used in a variety of relevant collaborative filtering areas such as detection of shilling attacks, recommendations explanation or navigational tools to show users and items dependences. Additionally, recommendation reliabilities can be gracefully provided to users: "probably you will like this film", "almost certainly you will like this song", etc. This paper provides the proposed neural architecture; it also tests that the quality of its recommendation results is as good as the state of art baselines. Remarkably, individual rating predictions are improved by using the proposed architecture compared to baselines. Experiments have been performed making use of four popular public datasets, showing generalizable quality results. Overall, the proposed architecture improves individual rating predictions quality, maintains recommendation results and opens the doors to a set of relevant collaborative filtering fields.
* 9 pages, 7 figures
Creating Synthetic Datasets for Collaborative Filtering Recommender Systems using Generative Adversarial Networks
Mar 02, 2023



Research and education in machine learning needs diverse, representative, and open datasets that contain sufficient samples to handle the necessary training, validation, and testing tasks. Currently, the Recommender Systems area includes a large number of subfields in which accuracy and beyond accuracy quality measures are continuously improved. To feed this research variety, it is necessary and convenient to reinforce the existing datasets with synthetic ones. This paper proposes a Generative Adversarial Network (GAN)-based method to generate collaborative filtering datasets in a parameterized way, by selecting their preferred number of users, items, samples, and stochastic variability. This parameterization cannot be made using regular GANs. Our GAN model is fed with dense, short, and continuous embedding representations of items and users, instead of sparse, large, and discrete vectors, to make an accurate and quick learning, compared to the traditional approach based on large and sparse input vectors. The proposed architecture includes a DeepMF model to extract the dense user and item embeddings, as well as a clustering process to convert from the dense GAN generated samples to the discrete and sparse ones, necessary to create each required synthetic dataset. The results of three different source datasets show adequate distributions and expected quality values and evolutions on the generated datasets compared to the source ones. Synthetic datasets and source codes are available to researchers.
Deep Variational Models for Collaborative Filtering-based Recommender Systems
Jul 27, 2021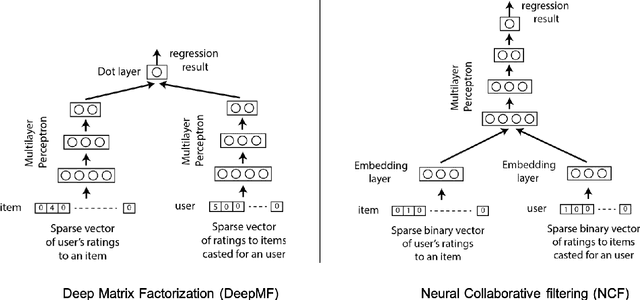
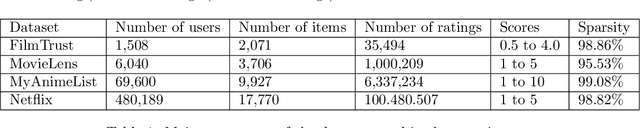
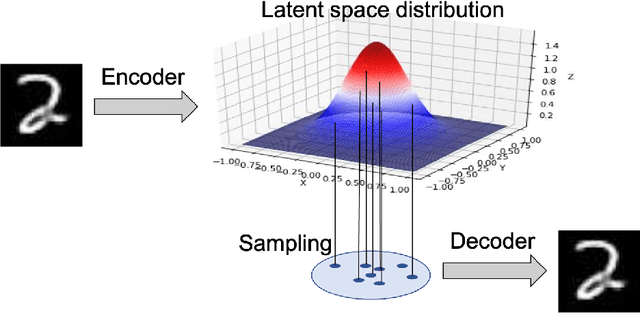
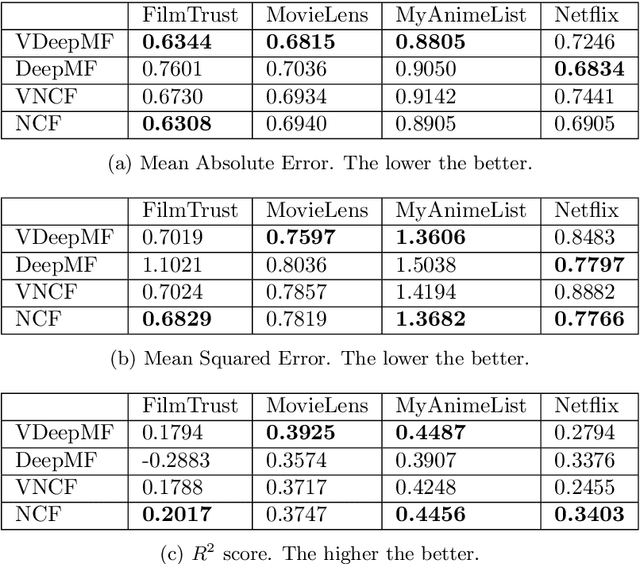
Deep learning provides accurate collaborative filtering models to improve recommender system results. Deep matrix factorization and their related collaborative neural networks are the state-of-art in the field; nevertheless, both models lack the necessary stochasticity to create the robust, continuous, and structured latent spaces that variational autoencoders exhibit. On the other hand, data augmentation through variational autoencoder does not provide accurate results in the collaborative filtering field due to the high sparsity of recommender systems. Our proposed models apply the variational concept to inject stochasticity in the latent space of the deep architecture, introducing the variational technique in the neural collaborative filtering field. This method does not depend on the particular model used to generate the latent representation. In this way, this approach can be applied as a plugin to any current and future specific models. The proposed models have been tested using four representative open datasets, three different quality measures, and state-of-art baselines. The results show the superiority of the proposed approach in scenarios where the variational enrichment exceeds the injected noise effect. Additionally, a framework is provided to enable the reproducibility of the conducted experiments.