 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Collaborative Filtering Classification Model to Obtain Prediction Reliabilities
Oct 22, 2024Neural collaborative filtering is the state of art field in the recommender systems area; it provides some models that obtain accurate predictions and recommendations. These models are regression-based, and they just return rating predictions. This paper proposes the use of a classification-based approach, returning both rating predictions and their reliabilities. The extra information (prediction reliabilities) can be used in a variety of relevant collaborative filtering areas such as detection of shilling attacks, recommendations explanation or navigational tools to show users and items dependences. Additionally, recommendation reliabilities can be gracefully provided to users: "probably you will like this film", "almost certainly you will like this song", etc. This paper provides the proposed neural architecture; it also tests that the quality of its recommendation results is as good as the state of art baselines. Remarkably, individual rating predictions are improved by using the proposed architecture compared to baselines. Experiments have been performed making use of four popular public datasets, showing generalizable quality results. Overall, the proposed architecture improves individual rating predictions quality, maintains recommendation results and opens the doors to a set of relevant collaborative filtering fields.
* 9 pages, 7 figures
Incorporating Recklessness to Collaborative Filtering based Recommender Systems
Aug 03, 2023
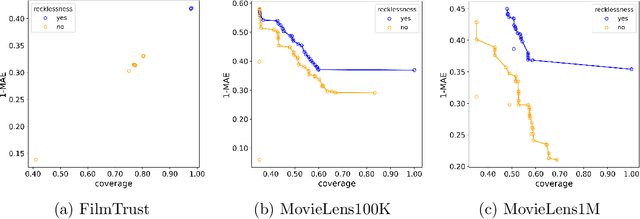
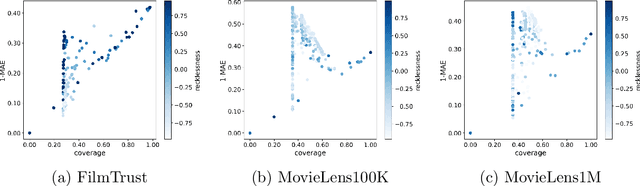
Recommender systems that include some reliability measure of their predictions tend to be more conservative in forecasting, due to their constraint to preserve reliability. This leads to a significant drop in the coverage and novelty that these systems can provide. In this paper, we propose the inclusion of a new term in the learning process of matrix factorization-based recommender systems, called recklessness, which enables the control of the risk level desired when making decisions about the reliability of a prediction. Experimental results demonstrate that recklessness not only allows for risk regulation but also improves the quantity and quality of predictions provided by the recommender system.
An evaluation framework for dimensionality reduction through sectional curvature
Mar 17, 2023Unsupervised machine learning lacks ground truth by definition. This poses a major difficulty when designing metrics to evaluate the performance of such algorithms. In sharp contrast with supervised learning, for which plenty of quality metrics have been studied in the literature, in the field of dimensionality reduction only a few over-simplistic metrics has been proposed. In this work, we aim to introduce the first highly non-trivial dimensionality reduction performance metric. This metric is based on the sectional curvature behaviour arising from Riemannian geometry. To test its feasibility, this metric has been used to evaluate the performance of the most commonly used dimension reduction algorithms in the state of the art. Furthermore, to make the evaluation of the algorithms robust and representative, using curvature properties of planar curves, a new parameterized problem instance generator has been constructed in the form of a function generator. Experimental results are consistent with what could be expected based on the design and characteristics of the evaluated algorithms and the features of the data instances used to feed the method.
Dynamics of Fourier Modes in Torus Generative Adversarial Networks
Sep 05, 2022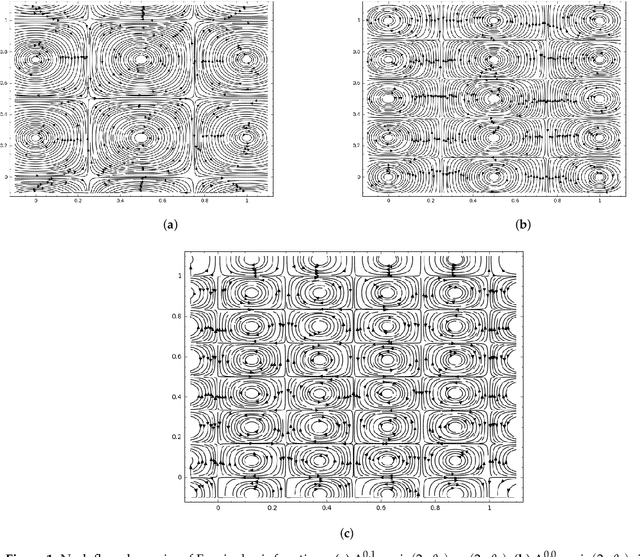
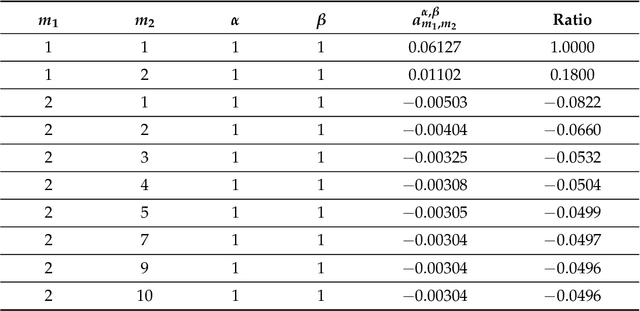
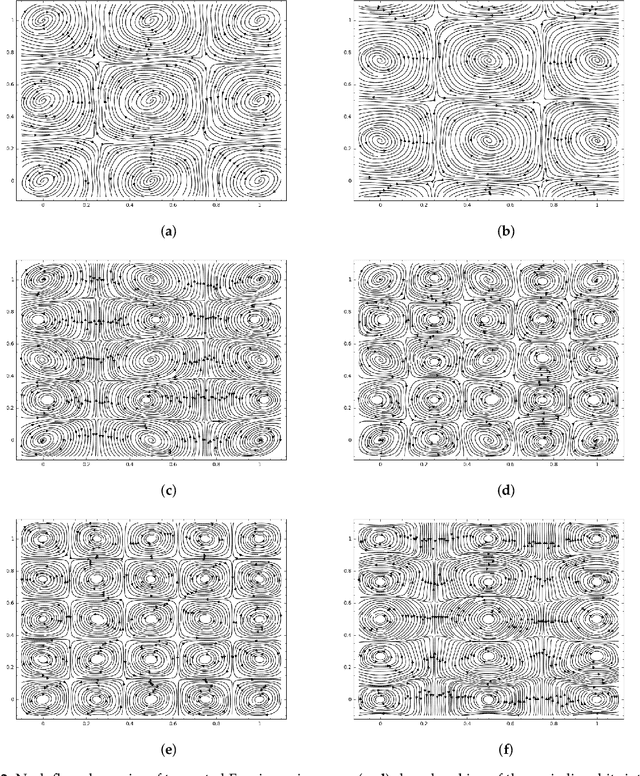
Generative Adversarial Networks (GANs) are powerful Machine Learning models capable of generating fully synthetic samples of a desired phenomenon with a high resolution. Despite their success, the training process of a GAN is highly unstable and typically it is necessary to implement several accessory heuristics to the networks to reach an acceptable convergence of the model. In this paper, we introduce a novel method to analyze the convergence and stability in the training of Generative Adversarial Networks. For this purpose, we propose to decompose the objective function of the adversary min-max game defining a periodic GAN into its Fourier series. By studying the dynamics of the truncated Fourier series for the continuous Alternating Gradient Descend algorithm, we are able to approximate the real flow and to identify the main features of the convergence of the GAN. This approach is confirmed empirically by studying the training flow in a $2$-parametric GAN aiming to generate an unknown exponential distribution. As byproduct, we show that convergent orbits in GANs are small perturbations of periodic orbits so the Nash equillibria are spiral attractors. This theoretically justifies the slow and unstable training observed in GANs.
Data Augmentation techniques in time series domain: A survey and taxonomy
Jun 25, 2022
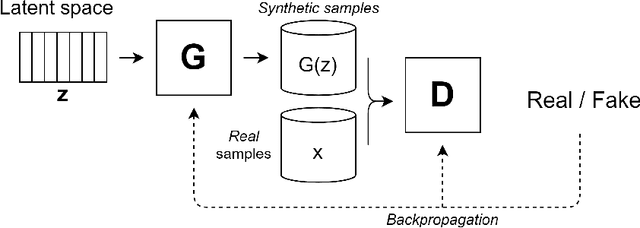
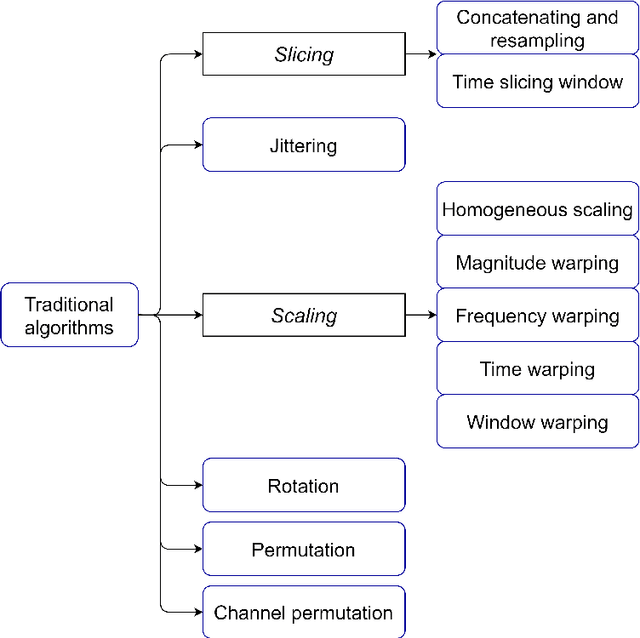
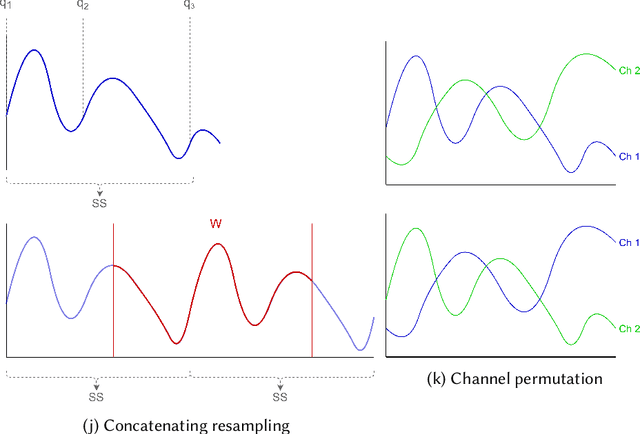
With the latest advances in deep learning generative models, it has not taken long to take advantage of their remarkable performance in the area of time series. Deep neural networks used to work with time series depend heavily on the breadth and consistency of the datasets used in training. These types of characteristic are not usually abundant in the real world, where they are usually limited and often with privacy constraints that must be guaranteed. Therefore, an effective way is to increase the number of data using \gls{da} techniques, either by adding noise or permutations and by generating new synthetic data. It is systematically review the current state-of-the-art in the area to provide an overview of all available algorithms and proposes a taxonomy of the most relevant researches. The efficiency of the different variants will be evaluated; as a vital part of the process, the different metrics to evaluate the performance and the main problems concerning each model will be analysed. The ultimate goal of this study is to provide a summary of the evolution and performance of areas that produce better results to guide future researchers in this field.
Improving the quality of generative models through Smirnov transformation
Oct 29, 2021
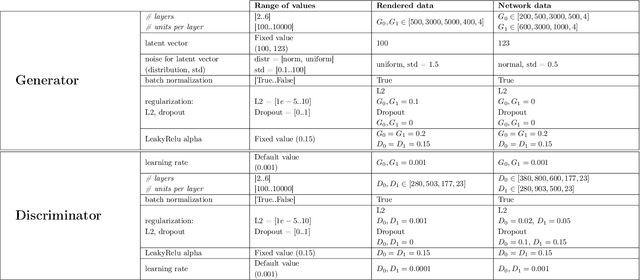
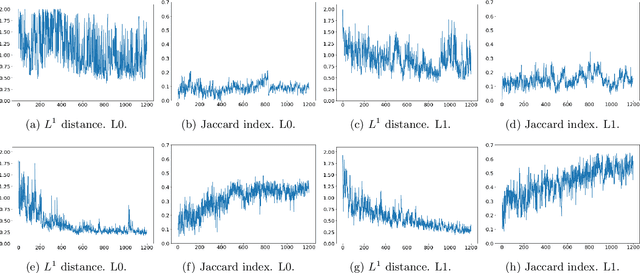
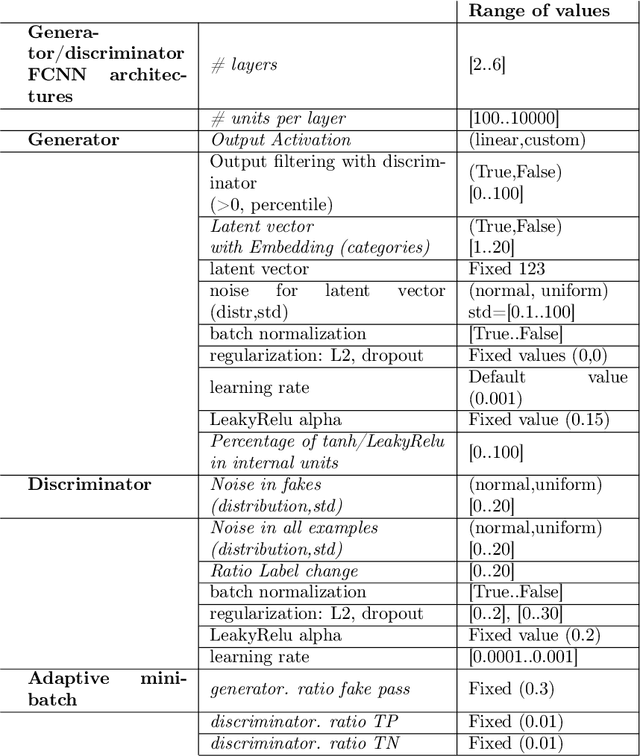
Solving the convergence issues of Generative Adversarial Networks (GANs) is one of the most outstanding problems in generative models. In this work, we propose a novel activation function to be used as output of the generator agent. This activation function is based on the Smirnov probabilistic transformation and it is specifically designed to improve the quality of the generated data. In sharp contrast with previous works, our activation function provides a more general approach that deals not only with the replication of categorical variables but with any type of data distribution (continuous or discrete). Moreover, our activation function is derivable and therefore, it can be seamlessly integrated in the backpropagation computations during the GAN training processes. To validate this approach, we evaluate our proposal against two different data sets: a) an artificially rendered data set containing a mixture of discrete and continuous variables, and b) a real data set of flow-based network traffic data containing both normal connections and cryptomining attacks. To evaluate the fidelity of the generated data, we analyze both their results in terms of quality measures of statistical nature and also regarding the use of these synthetic data to feed a nested machine learning-based classifier. The experimental results evince a clear outperformance of the GAN network tuned with this new activation function with respect to both a na\"ive mean-based generator and a standard GAN. The quality of the data is so high that the generated data can fully substitute real data for training the nested classifier without a fall in the obtained accuracy. This result encourages the use of GANs to produce high-quality synthetic data that are applicable in scenarios in which data privacy must be guaranteed.
Synthetic flow-based cryptomining attack generation through Generative Adversarial Networks
Jul 30, 2021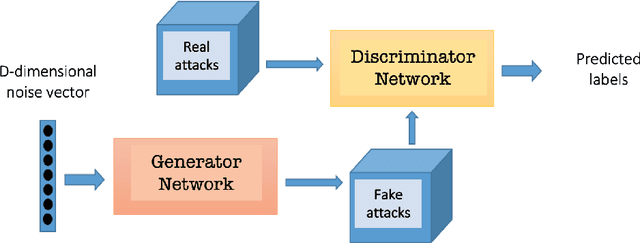
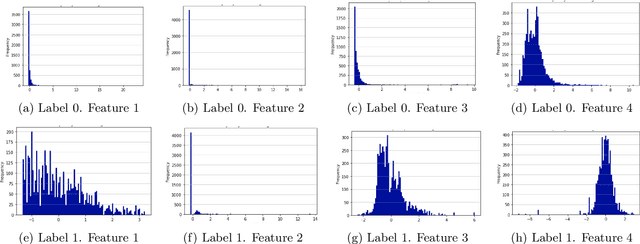
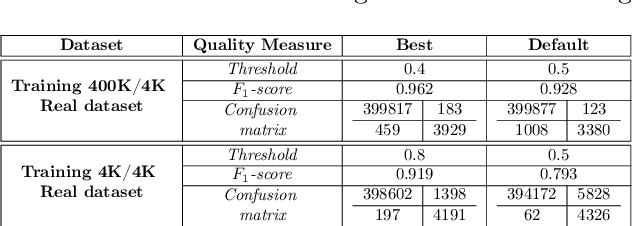
Due to the growing rise of cyber attacks in the Internet, flow-based data sets are crucial to increase the performance of the Machine Learning (ML) components that run in network-based intrusion detection systems (IDS). To overcome the existing network traffic data shortage in attack analysis, recent works propose Generative Adversarial Networks (GANs) for synthetic flow-based network traffic generation. Data privacy is appearing more and more as a strong requirement when processing such network data, which suggests to find solutions where synthetic data can fully replace real data. Because of the ill-convergence of the GAN training, none of the existing solutions can generate high-quality fully synthetic data that can totally substitute real data in the training of IDS ML components. Therefore, they mix real with synthetic data, which acts only as data augmentation components, leading to privacy breaches as real data is used. In sharp contrast, in this work we propose a novel deterministic way to measure the quality of the synthetic data produced by a GAN both with respect to the real data and to its performance when used for ML tasks. As a byproduct, we present a heuristic that uses these metrics for selecting the best performing generator during GAN training, leading to a stopping criterion. An additional heuristic is proposed to select the best performing GANs when different types of synthetic data are to be used in the same ML task. We demonstrate the adequacy of our proposal by generating synthetic cryptomining attack traffic and normal traffic flow-based data using an enhanced version of a Wasserstein GAN. We show that the generated synthetic network traffic can completely replace real data when training a ML-based cryptomining detector, obtaining similar performance and avoiding privacy violations, since real data is not used in the training of the ML-based detector.
Deep Variational Models for Collaborative Filtering-based Recommender Systems
Jul 27, 2021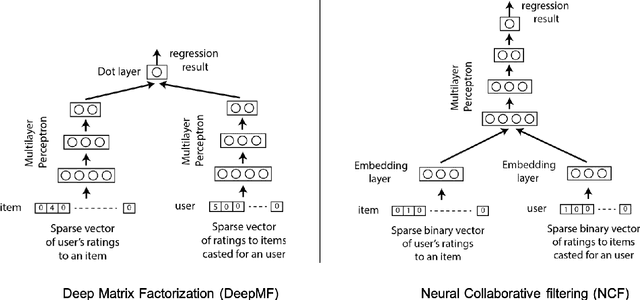
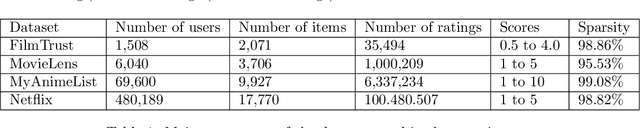
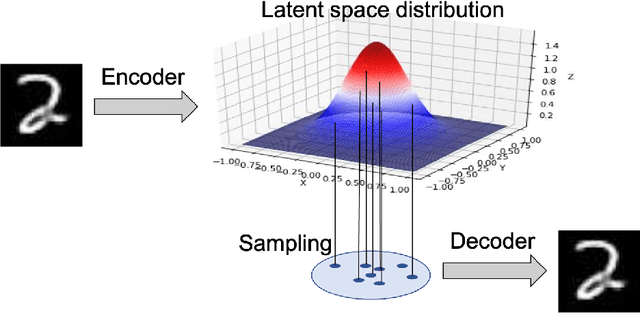
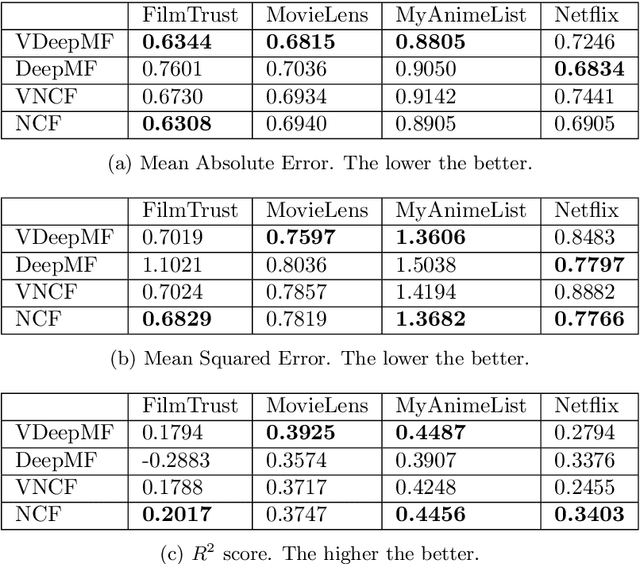
Deep learning provides accurate collaborative filtering models to improve recommender system results. Deep matrix factorization and their related collaborative neural networks are the state-of-art in the field; nevertheless, both models lack the necessary stochasticity to create the robust, continuous, and structured latent spaces that variational autoencoders exhibit. On the other hand, data augmentation through variational autoencoder does not provide accurate results in the collaborative filtering field due to the high sparsity of recommender systems. Our proposed models apply the variational concept to inject stochasticity in the latent space of the deep architecture, introducing the variational technique in the neural collaborative filtering field. This method does not depend on the particular model used to generate the latent representation. In this way, this approach can be applied as a plugin to any current and future specific models. The proposed models have been tested using four representative open datasets, three different quality measures, and state-of-art baselines. The results show the superiority of the proposed approach in scenarios where the variational enrichment exceeds the injected noise effect. Additionally, a framework is provided to enable the reproducibility of the conducted experiments.
Machine learning for risk assessment in gender-based crime
Jun 22, 2021
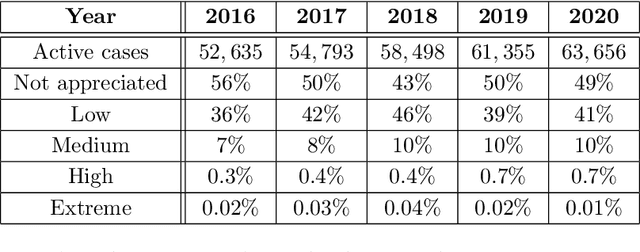
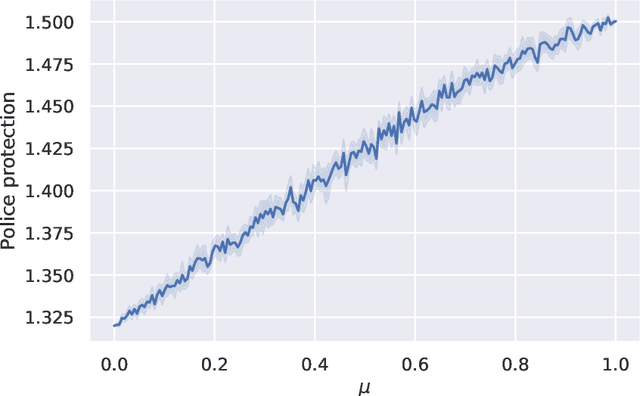
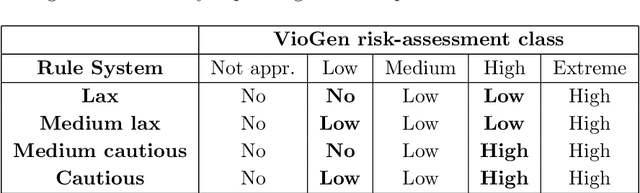
Gender-based crime is one of the most concerning scourges of contemporary society. Governments worldwide have invested lots of economic and human resources to radically eliminate this threat. Despite these efforts, providing accurate predictions of the risk that a victim of gender violence has of being attacked again is still a very hard open problem. The development of new methods for issuing accurate, fair and quick predictions would allow police forces to select the most appropriate measures to prevent recidivism. In this work, we propose to apply Machine Learning (ML) techniques to create models that accurately predict the recidivism risk of a gender-violence offender. The relevance of the contribution of this work is threefold: (i) the proposed ML method outperforms the preexisting risk assessment algorithm based on classical statistical techniques, (ii) the study has been conducted through an official specific-purpose database with more than 40,000 reports of gender violence, and (iii) two new quality measures are proposed for assessing the effective police protection that a model supplies and the overload in the invested resources that it generates. Additionally, we propose a hybrid model that combines the statistical prediction methods with the ML method, permitting authorities to implement a smooth transition from the preexisting model to the ML-based model. This hybrid nature enables a decision-making process to optimally balance between the efficiency of the police system and aggressiveness of the protection measures taken.
Deep Learning feature selection to unhide demographic recommender systems factors
Jun 17, 2020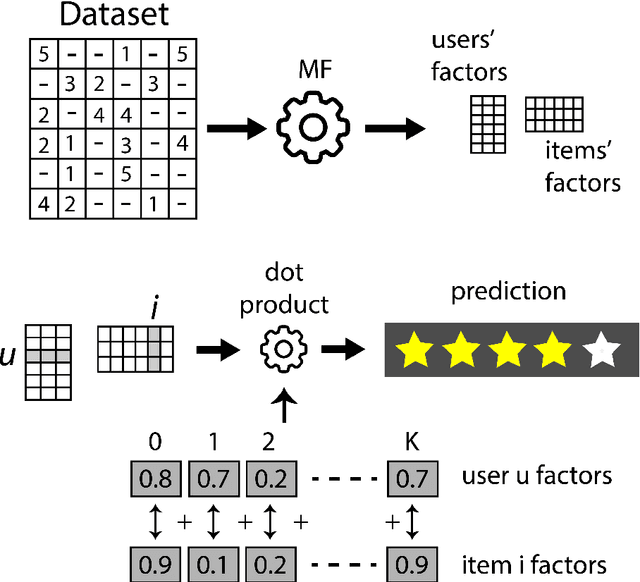
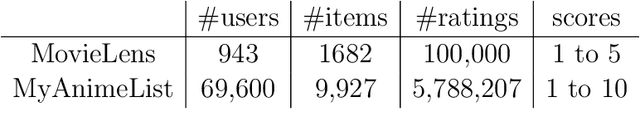

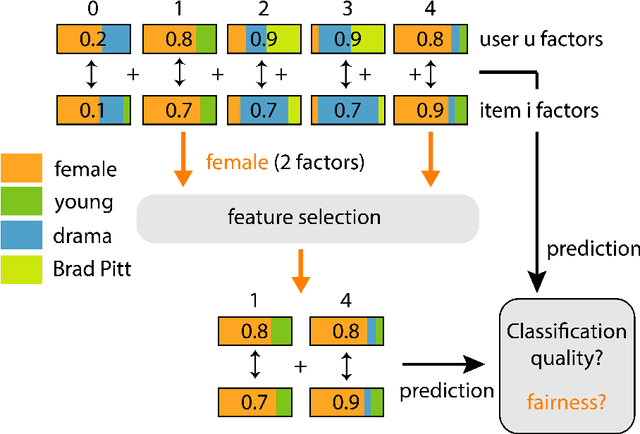
Extracting demographic features from hidden factors is an innovative concept that provides multiple and relevant applications. The matrix factorization model generates factors which do not incorporate semantic knowledge. This paper provides a deep learning-based method: DeepUnHide, able to extract demographic information from the users and items factors in collaborative filtering recommender systems. The core of the proposed method is the gradient-based localization used in the image processing literature to highlight the representative areas of each classification class. Validation experiments make use of two public datasets and current baselines. Results show the superiority of DeepUnHide to make feature selection and demographic classification, compared to the state of art of feature selection methods. Relevant and direct applications include recommendations explanation, fairness in collaborative filtering and recommendation to groups of users.