 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamics of Fourier Modes in Torus Generative Adversarial Networks
Sep 05, 2022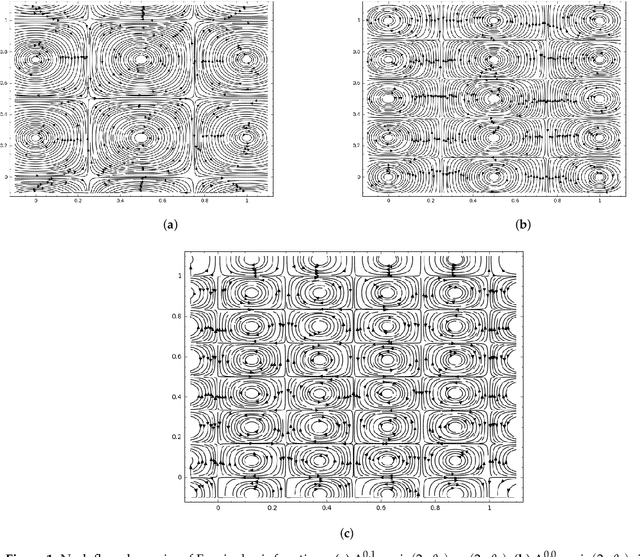
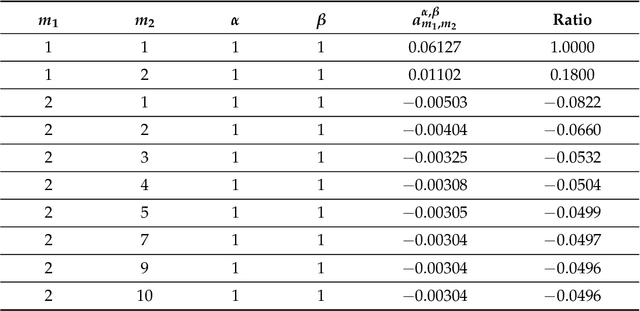
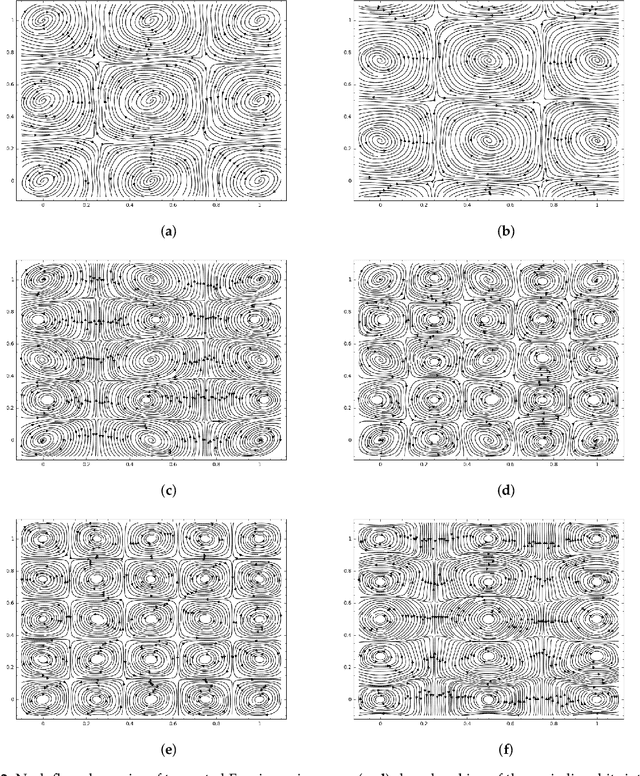
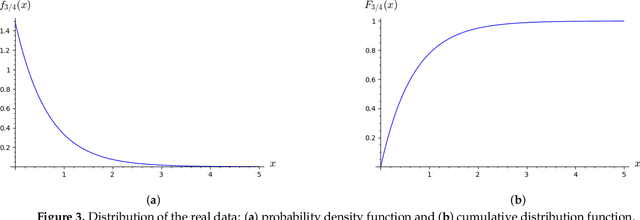
Generative Adversarial Networks (GANs) are powerful Machine Learning models capable of generating fully synthetic samples of a desired phenomenon with a high resolution. Despite their success, the training process of a GAN is highly unstable and typically it is necessary to implement several accessory heuristics to the networks to reach an acceptable convergence of the model. In this paper, we introduce a novel method to analyze the convergence and stability in the training of Generative Adversarial Networks. For this purpose, we propose to decompose the objective function of the adversary min-max game defining a periodic GAN into its Fourier series. By studying the dynamics of the truncated Fourier series for the continuous Alternating Gradient Descend algorithm, we are able to approximate the real flow and to identify the main features of the convergence of the GAN. This approach is confirmed empirically by studying the training flow in a $2$-parametric GAN aiming to generate an unknown exponential distribution. As byproduct, we show that convergent orbits in GANs are small perturbations of periodic orbits so the Nash equillibria are spiral attractors. This theoretically justifies the slow and unstable training observed in GANs.
Data Augmentation techniques in time series domain: A survey and taxonomy
Jun 25, 2022
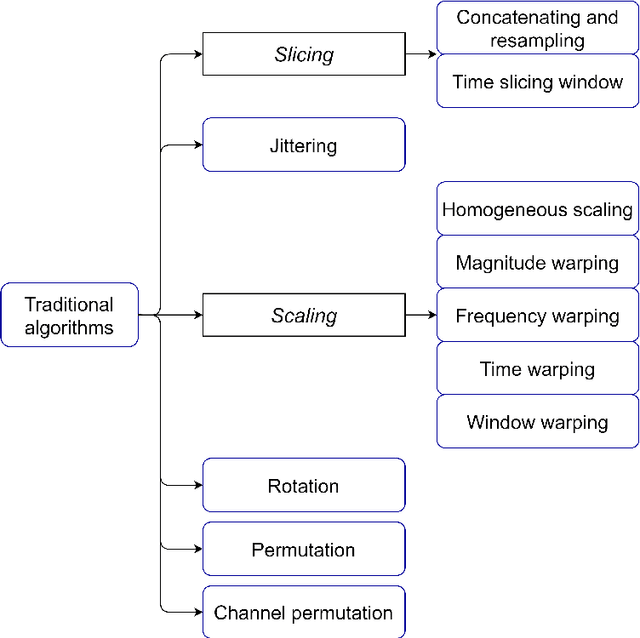
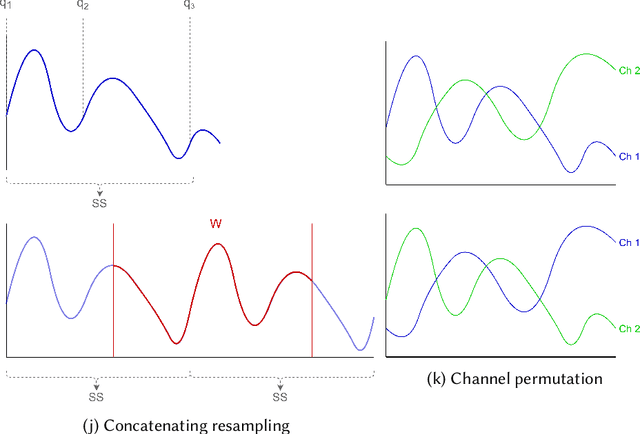
With the latest advances in deep learning generative models, it has not taken long to take advantage of their remarkable performance in the area of time series. Deep neural networks used to work with time series depend heavily on the breadth and consistency of the datasets used in training. These types of characteristic are not usually abundant in the real world, where they are usually limited and often with privacy constraints that must be guaranteed. Therefore, an effective way is to increase the number of data using \gls{da} techniques, either by adding noise or permutations and by generating new synthetic data. It is systematically review the current state-of-the-art in the area to provide an overview of all available algorithms and proposes a taxonomy of the most relevant researches. The efficiency of the different variants will be evaluated; as a vital part of the process, the different metrics to evaluate the performance and the main problems concerning each model will be analysed. The ultimate goal of this study is to provide a summary of the evolution and performance of areas that produce better results to guide future researchers in this field.
Improving the quality of generative models through Smirnov transformation
Oct 29, 2021
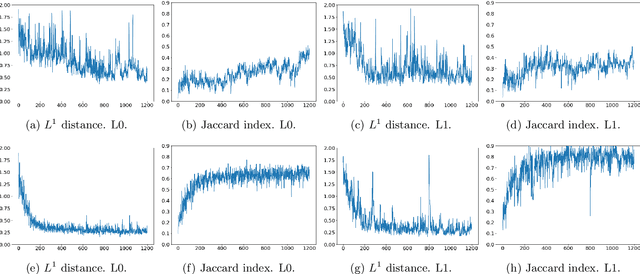
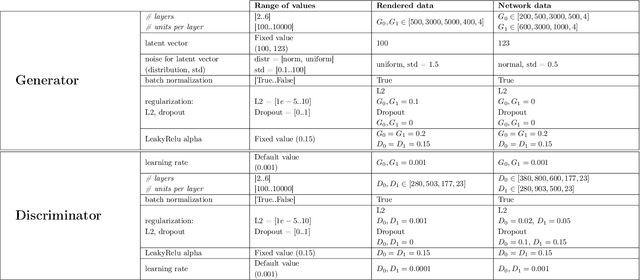
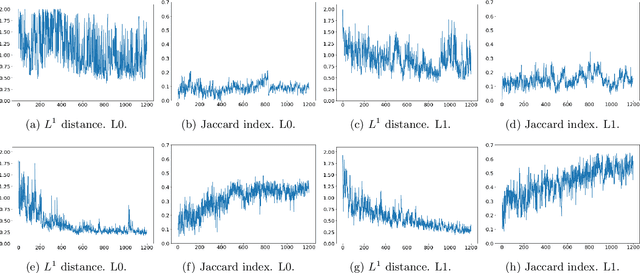
Solving the convergence issues of Generative Adversarial Networks (GANs) is one of the most outstanding problems in generative models. In this work, we propose a novel activation function to be used as output of the generator agent. This activation function is based on the Smirnov probabilistic transformation and it is specifically designed to improve the quality of the generated data. In sharp contrast with previous works, our activation function provides a more general approach that deals not only with the replication of categorical variables but with any type of data distribution (continuous or discrete). Moreover, our activation function is derivable and therefore, it can be seamlessly integrated in the backpropagation computations during the GAN training processes. To validate this approach, we evaluate our proposal against two different data sets: a) an artificially rendered data set containing a mixture of discrete and continuous variables, and b) a real data set of flow-based network traffic data containing both normal connections and cryptomining attacks. To evaluate the fidelity of the generated data, we analyze both their results in terms of quality measures of statistical nature and also regarding the use of these synthetic data to feed a nested machine learning-based classifier. The experimental results evince a clear outperformance of the GAN network tuned with this new activation function with respect to both a na\"ive mean-based generator and a standard GAN. The quality of the data is so high that the generated data can fully substitute real data for training the nested classifier without a fall in the obtained accuracy. This result encourages the use of GANs to produce high-quality synthetic data that are applicable in scenarios in which data privacy must be guaranteed.
Synthetic flow-based cryptomining attack generation through Generative Adversarial Networks
Jul 30, 2021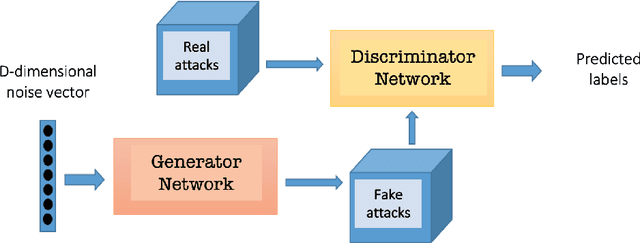
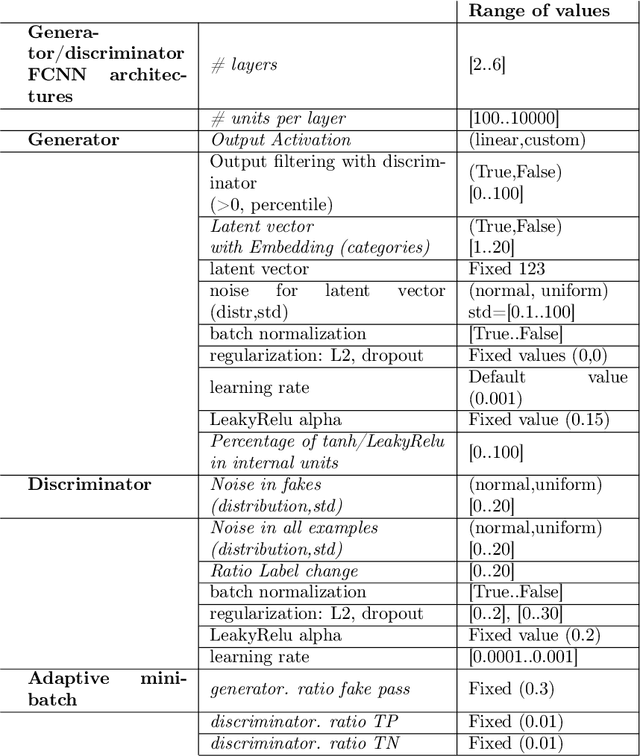
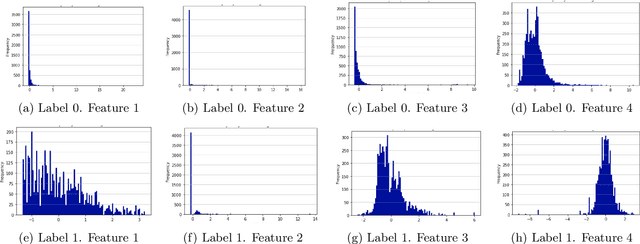
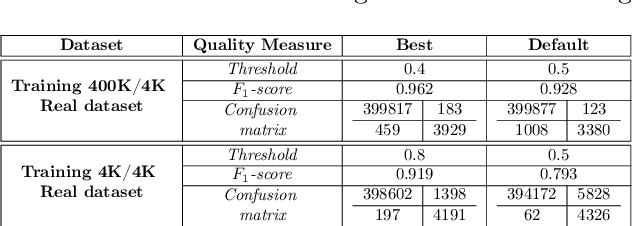
Due to the growing rise of cyber attacks in the Internet, flow-based data sets are crucial to increase the performance of the Machine Learning (ML) components that run in network-based intrusion detection systems (IDS). To overcome the existing network traffic data shortage in attack analysis, recent works propose Generative Adversarial Networks (GANs) for synthetic flow-based network traffic generation. Data privacy is appearing more and more as a strong requirement when processing such network data, which suggests to find solutions where synthetic data can fully replace real data. Because of the ill-convergence of the GAN training, none of the existing solutions can generate high-quality fully synthetic data that can totally substitute real data in the training of IDS ML components. Therefore, they mix real with synthetic data, which acts only as data augmentation components, leading to privacy breaches as real data is used. In sharp contrast, in this work we propose a novel deterministic way to measure the quality of the synthetic data produced by a GAN both with respect to the real data and to its performance when used for ML tasks. As a byproduct, we present a heuristic that uses these metrics for selecting the best performing generator during GAN training, leading to a stopping criterion. An additional heuristic is proposed to select the best performing GANs when different types of synthetic data are to be used in the same ML task. We demonstrate the adequacy of our proposal by generating synthetic cryptomining attack traffic and normal traffic flow-based data using an enhanced version of a Wasserstein GAN. We show that the generated synthetic network traffic can completely replace real data when training a ML-based cryptomining detector, obtaining similar performance and avoiding privacy violations, since real data is not used in the training of the ML-based detector.
Regularized Greedy Column Subset Selection
Apr 12, 2018
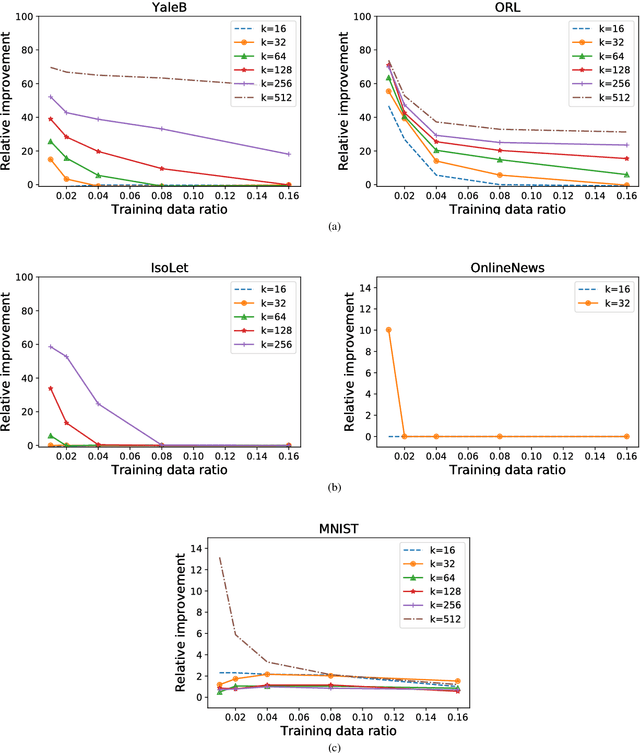

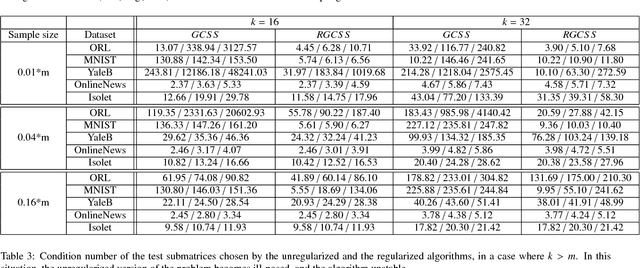
The Column Subset Selection Problem provides a natural framework for unsupervised feature selection. Despite being a hard combinatorial optimization problem, there exist efficient algorithms that provide good approximations. The drawback of the problem formulation is that it incorporates no form of regularization, and is therefore very sensitive to noise when presented with scarce data. In this paper we propose a regularized formulation of this problem, and derive a correct greedy algorithm that is similar in efficiency to existing greedy methods for the unregularized problem. We study its adequacy for feature selection and propose suitable formulations. Additionally, we derive a lower bound for the error of the proposed problems. Through various numerical experiments on real and synthetic data, we demonstrate the significantly increased robustness and stability of our method, as well as the improved conditioning of its output, all while remaining efficient for practical use.
Using Machine Learning to Detect Noisy Neighbors in 5G Networks
Oct 24, 2016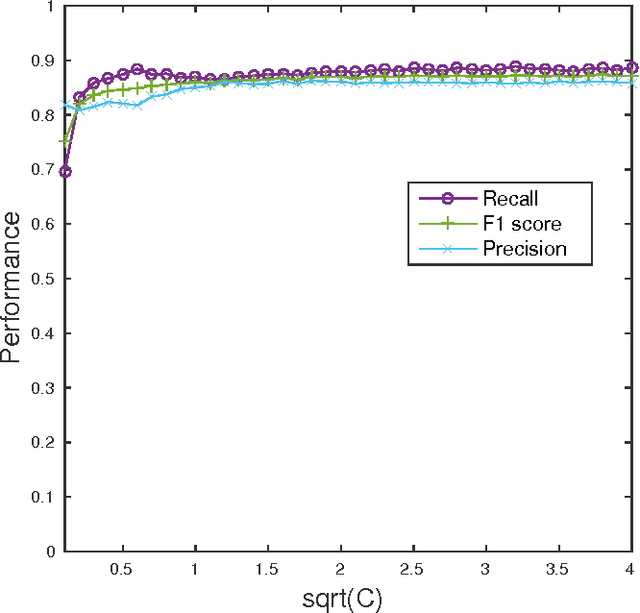
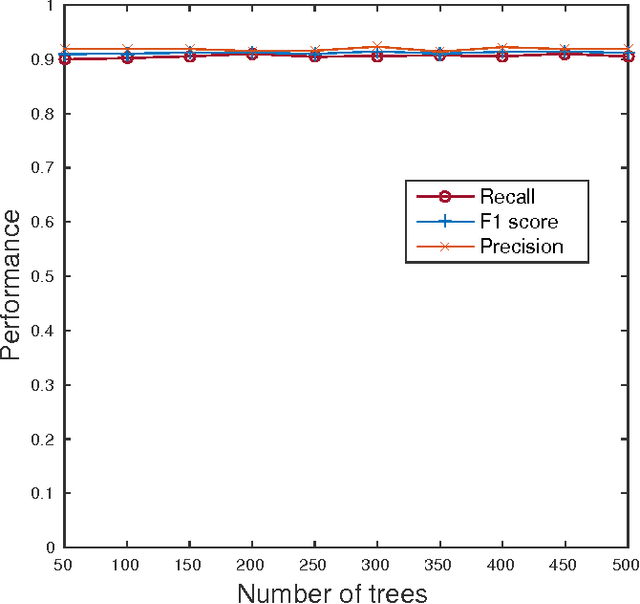


5G networks are expected to be more dynamic and chaotic in their structure than current networks. With the advent of Network Function Virtualization (NFV), Network Functions (NF) will no longer be tightly coupled with the hardware they are running on, which poses new challenges in network management. Noisy neighbor is a term commonly used to describe situations in NFV infrastructure where an application experiences degradation in performance due to the fact that some of the resources it needs are occupied by other applications in the same cloud node. These situations cannot be easily identified using straightforward approaches, which calls for the use of sophisticated methods for NFV infrastructure management. In this paper we demonstrate how Machine Learning (ML) techniques can be used to identify such events. Through experiments using data collected at real NFV infrastructure, we show that standard models for automated classification can detect the noisy neighbor phenomenon with an accuracy of more than 90% in a simple scenario.