 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCarbonTag: A browser-based method for approximating energy consumption of online ads
Oct 25, 2022



Energy is today the most critical environmental challenge. The amount of carbon emissions contributing to climate change is significantly influenced by both the production and consumption of energy. Measuring and reducing the energy consumption of services is a crucial step toward reducing adverse environmental effects caused by carbon emissions. Millions of websites rely on online advertisements to generate revenue, with most websites earning most or all of their revenues from ads. As a result, hundreds of billions of online ads are delivered daily to internet users to be rendered in their browsers. Both the delivery and rendering of each ad consume energy. This study investigates how much energy online ads use and offers a way for predicting it as part of rendering the ad. To the best of the authors' knowledge, this is the first study to calculate the energy usage of single advertisements. Our research further introduces different levels of consumption by which online ads can be classified based on energy efficiency. This classification will allow advertisers to add energy efficiency metrics and optimize campaigns towards consuming less possible.
Synthetic flow-based cryptomining attack generation through Generative Adversarial Networks
Jul 30, 2021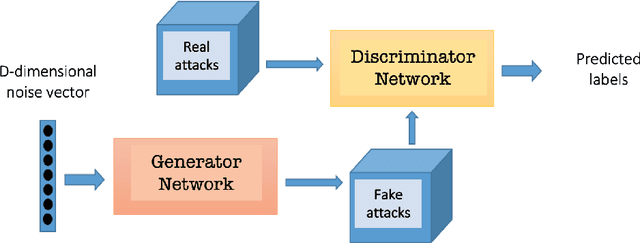
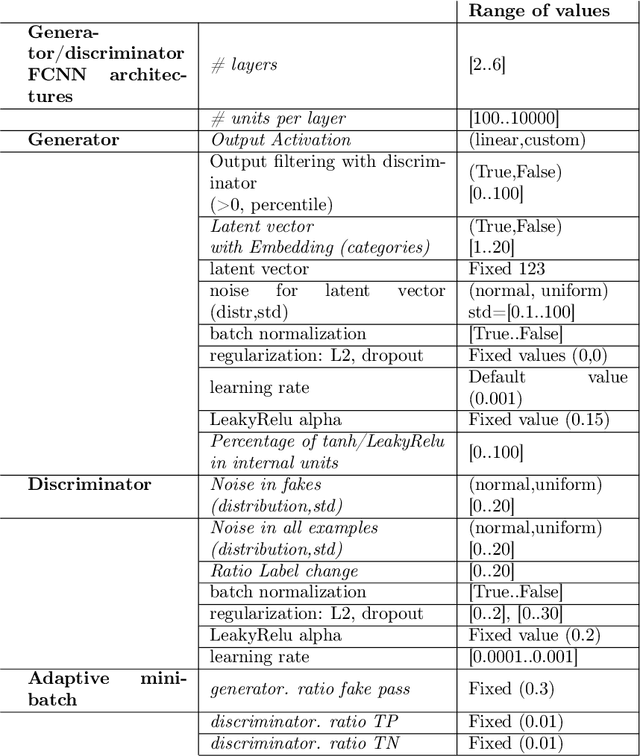
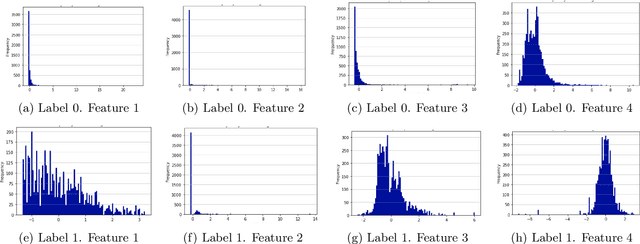
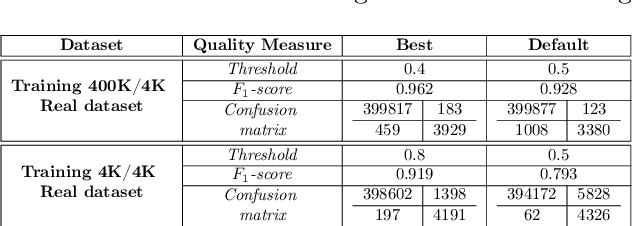
Due to the growing rise of cyber attacks in the Internet, flow-based data sets are crucial to increase the performance of the Machine Learning (ML) components that run in network-based intrusion detection systems (IDS). To overcome the existing network traffic data shortage in attack analysis, recent works propose Generative Adversarial Networks (GANs) for synthetic flow-based network traffic generation. Data privacy is appearing more and more as a strong requirement when processing such network data, which suggests to find solutions where synthetic data can fully replace real data. Because of the ill-convergence of the GAN training, none of the existing solutions can generate high-quality fully synthetic data that can totally substitute real data in the training of IDS ML components. Therefore, they mix real with synthetic data, which acts only as data augmentation components, leading to privacy breaches as real data is used. In sharp contrast, in this work we propose a novel deterministic way to measure the quality of the synthetic data produced by a GAN both with respect to the real data and to its performance when used for ML tasks. As a byproduct, we present a heuristic that uses these metrics for selecting the best performing generator during GAN training, leading to a stopping criterion. An additional heuristic is proposed to select the best performing GANs when different types of synthetic data are to be used in the same ML task. We demonstrate the adequacy of our proposal by generating synthetic cryptomining attack traffic and normal traffic flow-based data using an enhanced version of a Wasserstein GAN. We show that the generated synthetic network traffic can completely replace real data when training a ML-based cryptomining detector, obtaining similar performance and avoiding privacy violations, since real data is not used in the training of the ML-based detector.