 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFirst, do no harm: Breaking suicidogenic echo chambers in media recommendation
May 24, 2026Recommender systems generally optimises user engagement, but this approach is dangerous in mental health contexts. When vulnerable users show signs of suicidal ideation, standard algorithms often trap them in echo chambers of harmful content, worsening their psychological state. In response, we introduce RankAid, a re-ranking method that prioritises clinical safety alongside predictive relevance. It works as an add-on layer to existing models: it penalises risky items and boosts therapeutic content depending on the user's current level of vulnerability. We evaluated this approach using the MovieLens 1M dataset, where items were semantically annotated for clinical risk and therapeutic value using large language models. Our simulations show that our algorithm successfully blocks the recommendation of harmful content during crisis peaks, actively reshaping the feed to support emotional de-escalation. Furthermore, this safety intervention only causes a controlled, acceptable drop in standard accuracy metrics like NDCG. By using asymmetric hyperparameters, RankAid also gives system administrators the flexibility to tune the severity of the intervention based on specific clinical guidelines.
Automated ICD Classification of Psychiatric Diagnoses: From Classical NLP to Large Language Models
May 20, 2026Mental health has become a global priority, leading to a massive administrative burden in the coding of clinical diagnoses. This study proposes the automation of psychiatric diagnostic analysis by mapping free-text descriptions to the International Classification of Diseases (ICD) using Natural Language Processing (NLP) and Machine Learning (ML) techniques. Utilizing a specialized dataset of 145,513 Spanish psychiatric descriptions, various text representation paradigms were evaluated, ranging from classical frequency-based models (BoW, TF-IDF) to state-of-the-art Large Language Models (LLMs) such as e5\_large, BioLORD, and Llama-3-8B. Results indicate that transformer-based embeddings consistently outperform traditional methods by capturing implicit semantic cues and nuanced medical terminology. The e5\_large model, through end-to-end fine-tuning, achieved the highest performance with a $F1_{micro}$ score of 0.866. This research demonstrates that adapting LLMs to specific clinical nomenclature is essential for overcoming the challenges of ``long-tail'' label distributions and the inherent ambiguity of psychiatric discourse.
Efficient n-body simulations using physics informed graph neural networks
Apr 01, 2025This paper presents a novel approach for accelerating n-body simulations by integrating a physics-informed graph neural networks (GNN) with traditional numerical methods. Our method implements a leapfrog-based simulation engine to generate datasets from diverse astrophysical scenarios which are then transformed into graph representations. A custom-designed GNN is trained to predict particle accelerations with high precision. Experiments, conducted on 60 training and 6 testing simulations spanning from 3 to 500 bodies over 1000 time steps, demonstrate that the proposed model achieves extremely low prediction errors-loss values while maintaining robust long-term stability, with accumulated errors in position, velocity, and acceleration remaining insignificant. Furthermore, our method yields a modest speedup of approximately 17% over conventional simulation techniques. These results indicate that the integration of deep learning with traditional physical simulation methods offers a promising pathway to significantly enhance computational efficiency without compromising accuracy.
Deep Neural Aggregation for Recommending Items to Group of Users
Jul 18, 2023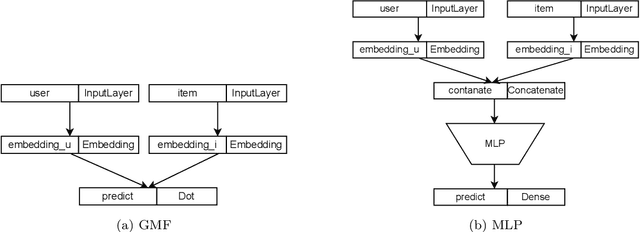


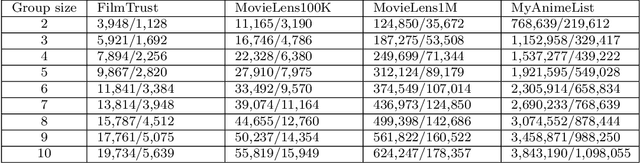
Modern society devotes a significant amount of time to digital interaction. Many of our daily actions are carried out through digital means. This has led to the emergence of numerous Artificial Intelligence tools that assist us in various aspects of our lives. One key tool for the digital society is Recommender Systems, intelligent systems that learn from our past actions to propose new ones that align with our interests. Some of these systems have specialized in learning from the behavior of user groups to make recommendations to a group of individuals who want to perform a joint task. In this article, we analyze the current state of Group Recommender Systems and propose two new models that use emerging Deep Learning architectures. Experimental results demonstrate the improvement achieved by employing the proposed models compared to the state-of-the-art models using four different datasets. The source code of the models, as well as that of all the experiments conducted, is available in a public repository.
An evaluation framework for dimensionality reduction through sectional curvature
Mar 17, 2023Unsupervised machine learning lacks ground truth by definition. This poses a major difficulty when designing metrics to evaluate the performance of such algorithms. In sharp contrast with supervised learning, for which plenty of quality metrics have been studied in the literature, in the field of dimensionality reduction only a few over-simplistic metrics has been proposed. In this work, we aim to introduce the first highly non-trivial dimensionality reduction performance metric. This metric is based on the sectional curvature behaviour arising from Riemannian geometry. To test its feasibility, this metric has been used to evaluate the performance of the most commonly used dimension reduction algorithms in the state of the art. Furthermore, to make the evaluation of the algorithms robust and representative, using curvature properties of planar curves, a new parameterized problem instance generator has been constructed in the form of a function generator. Experimental results are consistent with what could be expected based on the design and characteristics of the evaluated algorithms and the features of the data instances used to feed the method.
Neural Group Recommendation Based on a Probabilistic Semantic Aggregation
Mar 13, 2023Recommendation to groups of users is a challenging subfield of recommendation systems. Its key concept is how and where to make the aggregation of each set of user information into an individual entity, such as a ranked recommendation list, a virtual user, or a multi-hot input vector encoding. This paper proposes an innovative strategy where aggregation is made in the multi-hot vector that feeds the neural network model. The aggregation provides a probabilistic semantic, and the resulting input vectors feed a model that is able to conveniently generalize the group recommendation from the individual predictions. Furthermore, using the proposed architecture, group recommendations can be obtained by simply feedforwarding the pre-trained model with individual ratings; that is, without the need to obtain datasets containing group of user information, and without the need of running two separate trainings (individual and group). This approach also avoids maintaining two different models to support both individual and group learning. Experiments have tested the proposed architecture using three representative collaborative filtering datasets and a series of baselines; results show suitable accuracy improvements compared to the state-of-the-art.
Deep Learning feature selection to unhide demographic recommender systems factors
Jun 17, 2020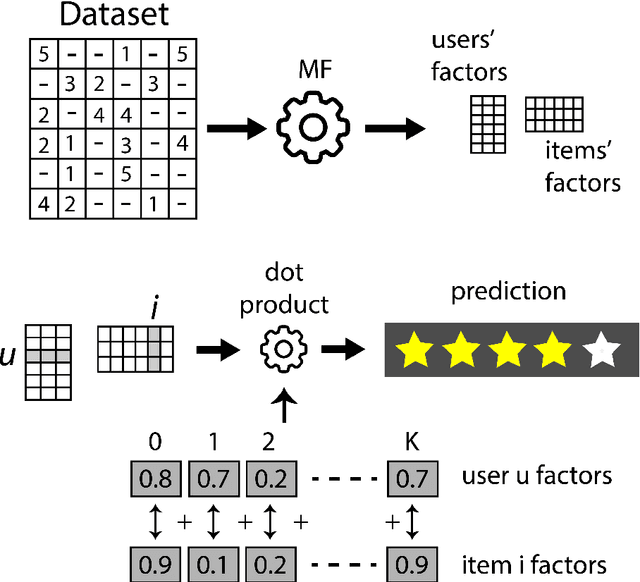
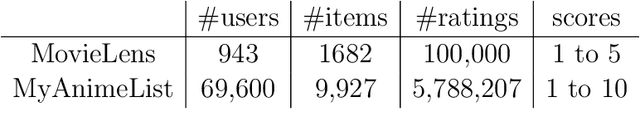

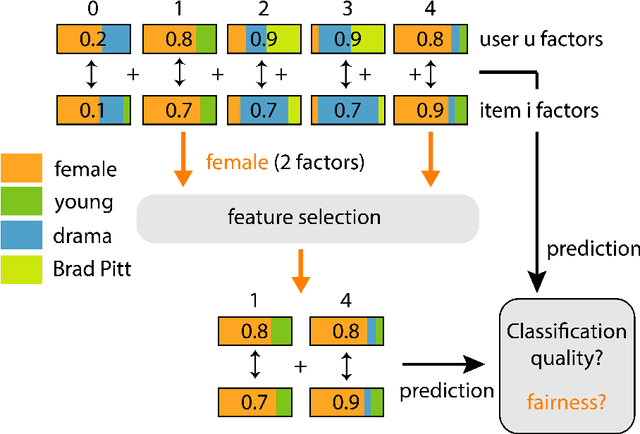
Extracting demographic features from hidden factors is an innovative concept that provides multiple and relevant applications. The matrix factorization model generates factors which do not incorporate semantic knowledge. This paper provides a deep learning-based method: DeepUnHide, able to extract demographic information from the users and items factors in collaborative filtering recommender systems. The core of the proposed method is the gradient-based localization used in the image processing literature to highlight the representative areas of each classification class. Validation experiments make use of two public datasets and current baselines. Results show the superiority of DeepUnHide to make feature selection and demographic classification, compared to the state of art of feature selection methods. Relevant and direct applications include recommendations explanation, fairness in collaborative filtering and recommendation to groups of users.
DeepFair: Deep Learning for Improving Fairness in Recommender Systems
Jun 09, 2020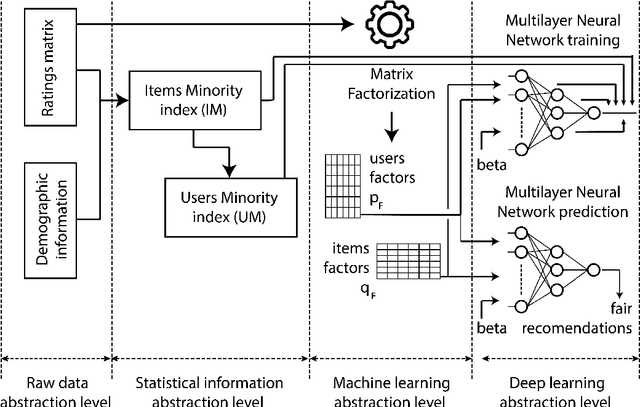
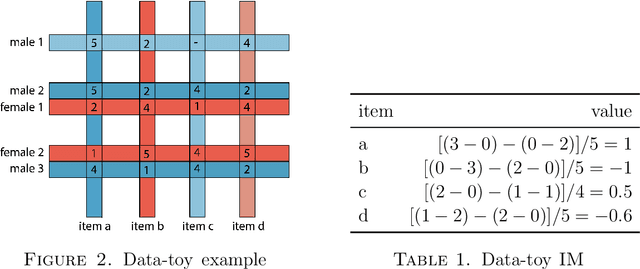
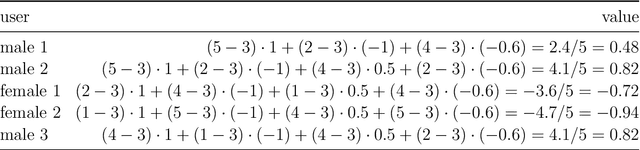
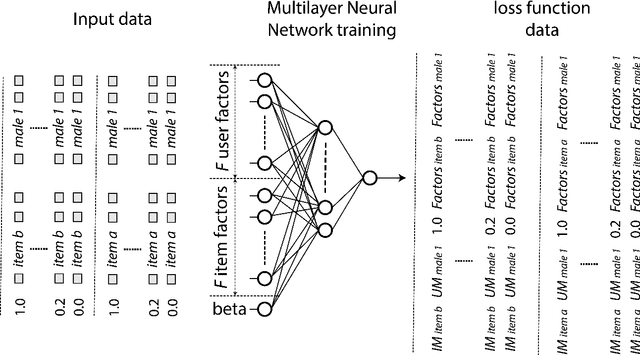
The lack of bias management in Recommender Systems leads to minority groups receiving unfair recommendations. Moreover, the trade-off between equity and precision makes it difficult to obtain recommendations that meet both criteria. Here we propose a Deep Learning based Collaborative Filtering algorithm that provides recommendations with an optimum balance between fairness and accuracy without knowing demographic information about the users. Experimental results show that it is possible to make fair recommendations without losing a significant proportion of accuracy.
Providing reliability in Recommender Systems through Bernoulli Matrix Factorization
Jun 05, 2020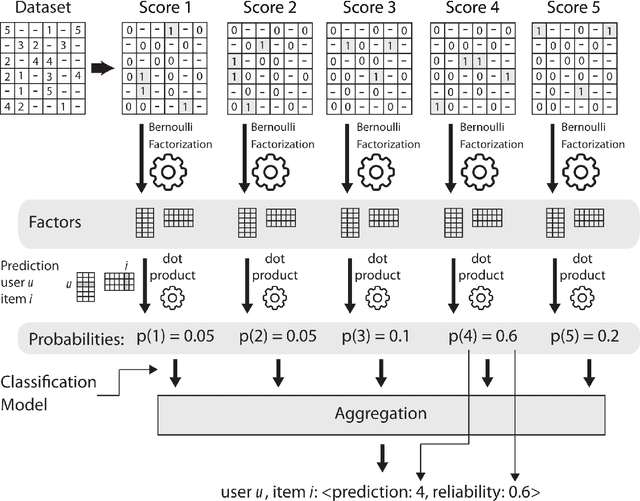
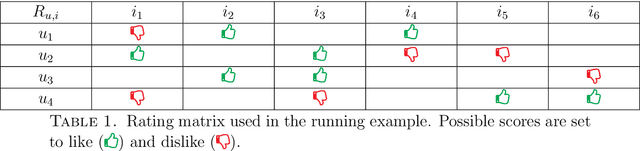

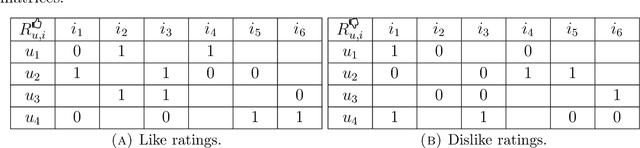
Recommender Systems are giving increasing importance to the beyond accuracy quality measures, and reliability is one of the most important in the Collaborative Filtering context. This paper proposes Bernoulli Matrix Factorization (BeMF), a matrix factorization model to provide both prediction values and reliability ones. This is a very innovative approach from several perspectives: a) it acts on the model-based Collaborative Filtering, rather than in the memory-based one, b) it does not use external methods or extended architectures for providing reliability such as the existing solutions, c) it is based on a classification-based model, instead of the usual regression-based ones, and d) the matrix factorization formalism is supported by the Bernoulli distribution, to exploit the binary nature of the designed classification model. As expected, results show that the more reliable a prediction is, the less liable to be wrong: recommendation quality has been improved by selecting the most reliable predictions. State-of-the-Art quality measures for reliability have been tested, showing improved results compared to the baseline methods and models.