 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Privacy in Decentralized Min-Max Optimization: A Differentially Private Approach
Aug 10, 2025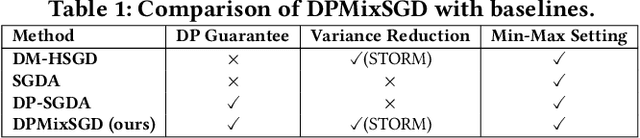

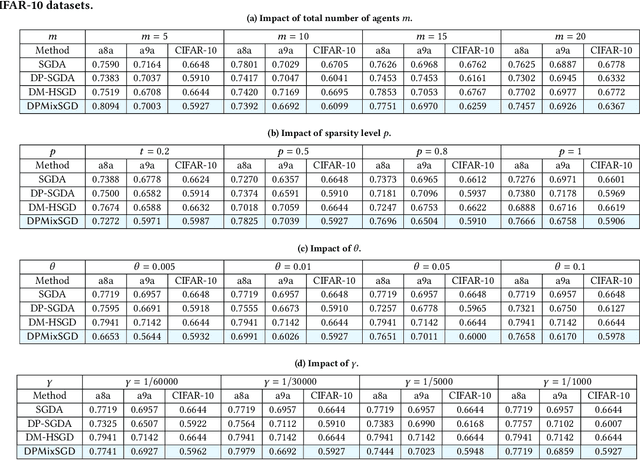

Decentralized min-max optimization allows multi-agent systems to collaboratively solve global min-max optimization problems by facilitating the exchange of model updates among neighboring agents, eliminating the need for a central server. However, sharing model updates in such systems carry a risk of exposing sensitive data to inference attacks, raising significant privacy concerns. To mitigate these privacy risks, differential privacy (DP) has become a widely adopted technique for safeguarding individual data. Despite its advantages, implementing DP in decentralized min-max optimization poses challenges, as the added noise can hinder convergence, particularly in non-convex scenarios with complex agent interactions in min-max optimization problems. In this work, we propose an algorithm called DPMixSGD (Differential Private Minmax Hybrid Stochastic Gradient Descent), a novel privacy-preserving algorithm specifically designed for non-convex decentralized min-max optimization. Our method builds on the state-of-the-art STORM-based algorithm, one of the fastest decentralized min-max solutions. We rigorously prove that the noise added to local gradients does not significantly compromise convergence performance, and we provide theoretical bounds to ensure privacy guarantees. To validate our theoretical findings, we conduct extensive experiments across various tasks and models, demonstrating the effectiveness of our approach.
Detecting Wildfire Flame and Smoke through Edge Computing using Transfer Learning Enhanced Deep Learning Models
Jan 15, 2025Autonomous unmanned aerial vehicles (UAVs) integrated with edge computing capabilities empower real-time data processing directly on the device, dramatically reducing latency in critical scenarios such as wildfire detection. This study underscores Transfer Learning's (TL) significance in boosting the performance of object detectors for identifying wildfire smoke and flames, especially when trained on limited datasets, and investigates the impact TL has on edge computing metrics. With the latter focusing how TL-enhanced You Only Look Once (YOLO) models perform in terms of inference time, power usage, and energy consumption when using edge computing devices. This study utilizes the Aerial Fire and Smoke Essential (AFSE) dataset as the target, with the Flame and Smoke Detection Dataset (FASDD) and the Microsoft Common Objects in Context (COCO) dataset serving as source datasets. We explore a two-stage cascaded TL method, utilizing D-Fire or FASDD as initial stage target datasets and AFSE as the subsequent stage. Through fine-tuning, TL significantly enhances detection precision, achieving up to 79.2% mean Average Precision (mAP@0.5), reduces training time, and increases model generalizability across the AFSE dataset. However, cascaded TL yielded no notable improvements and TL alone did not benefit the edge computing metrics evaluated. Lastly, this work found that YOLOv5n remains a powerful model when lacking hardware acceleration, finding that YOLOv5n can process images nearly twice as fast as its newer counterpart, YOLO11n. Overall, the results affirm TL's role in augmenting the accuracy of object detectors while also illustrating that additional enhancements are needed to improve edge computing performance.
Mental Health Diagnosis in the Digital Age: Harnessing Sentiment Analysis on Social Media Platforms upon Ultra-Sparse Feature Content
Nov 09, 2023Amid growing global mental health concerns, particularly among vulnerable groups, natural language processing offers a tremendous potential for early detection and intervention of people's mental disorders via analyzing their postings and discussions on social media platforms. However, ultra-sparse training data, often due to vast vocabularies and low-frequency words, hinders the analysis accuracy. Multi-labeling and Co-occurrences of symptoms may also blur the boundaries in distinguishing similar/co-related disorders. To address these issues, we propose a novel semantic feature preprocessing technique with a three-folded structure: 1) mitigating the feature sparsity with a weak classifier, 2) adaptive feature dimension with modulus loops, and 3) deep-mining and extending features among the contexts. With enhanced semantic features, we train a machine learning model to predict and classify mental disorders. We utilize the Reddit Mental Health Dataset 2022 to examine conditions such as Anxiety, Borderline Personality Disorder (BPD), and Bipolar-Disorder (BD) and present solutions to the data sparsity challenge, highlighted by 99.81% non-zero elements. After applying our preprocessing technique, the feature sparsity decreases to 85.4%. Overall, our methods, when compared to seven benchmark models, demonstrate significant performance improvements: 8.0% in accuracy, 0.069 in precision, 0.093 in recall, 0.102 in F1 score, and 0.059 in AUC. This research provides foundational insights for mental health prediction and monitoring, providing innovative solutions to navigate challenges associated with ultra-sparse data feature and intricate multi-label classification in the domain of mental health analysis.