 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Monocular Human Depth Estimation and Segmentation on Embedded Systems
Paper and Code
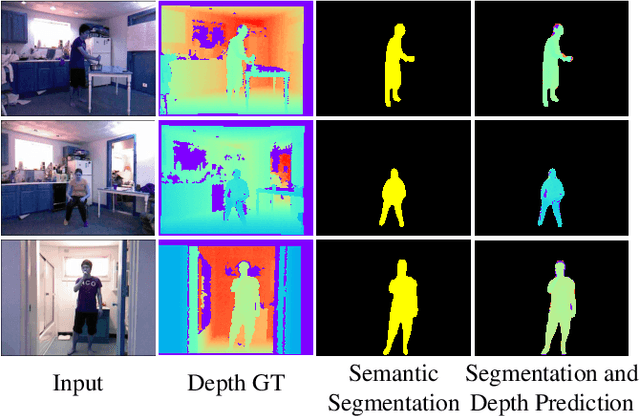
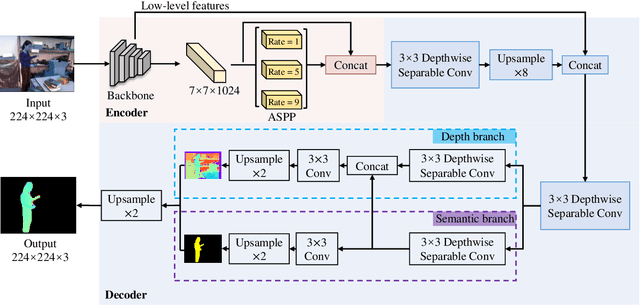
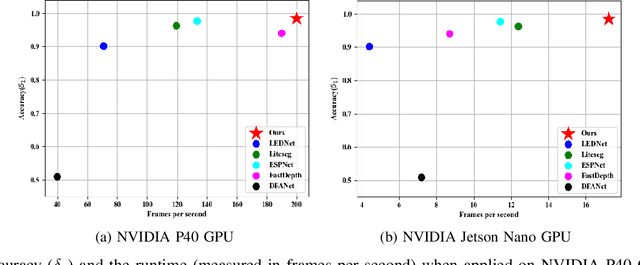
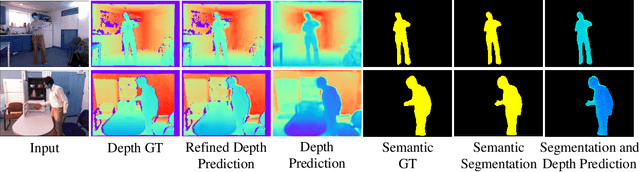
Estimating a scene's depth to achieve collision avoidance against moving pedestrians is a crucial and fundamental problem in the robotic field. This paper proposes a novel, low complexity network architecture for fast and accurate human depth estimation and segmentation in indoor environments, aiming to applications for resource-constrained platforms (including battery-powered aerial, micro-aerial, and ground vehicles) with a monocular camera being the primary perception module. Following the encoder-decoder structure, the proposed framework consists of two branches, one for depth prediction and another for semantic segmentation. Moreover, network structure optimization is employed to improve its forward inference speed. Exhaustive experiments on three self-generated datasets prove our pipeline's capability to execute in real-time, achieving higher frame rates than contemporary state-of-the-art frameworks (114.6 frames per second on an NVIDIA Jetson Nano GPU with TensorRT) while maintaining comparable accuracy.