 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Continuous Depth Representation via Geometric Spatial Aggregator
Dec 07, 2022

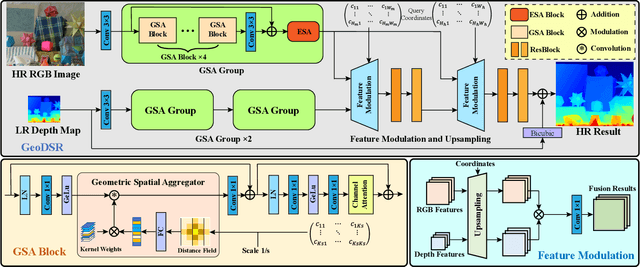

Depth map super-resolution (DSR) has been a fundamental task for 3D computer vision. While arbitrary scale DSR is a more realistic setting in this scenario, previous approaches predominantly suffer from the issue of inefficient real-numbered scale upsampling. To explicitly address this issue, we propose a novel continuous depth representation for DSR. The heart of this representation is our proposed Geometric Spatial Aggregator (GSA), which exploits a distance field modulated by arbitrarily upsampled target gridding, through which the geometric information is explicitly introduced into feature aggregation and target generation. Furthermore, bricking with GSA, we present a transformer-style backbone named GeoDSR, which possesses a principled way to construct the functional mapping between local coordinates and the high-resolution output results, empowering our model with the advantage of arbitrary shape transformation ready to help diverse zooming demand. Extensive experimental results on standard depth map benchmarks, e.g., NYU v2, have demonstrated that the proposed framework achieves significant restoration gain in arbitrary scale depth map super-resolution compared with the prior art. Our codes are available at https://github.com/nana01219/GeoDSR.
Im2Oil: Stroke-Based Oil Painting Rendering with Linearly Controllable Fineness Via Adaptive Sampling
Sep 27, 2022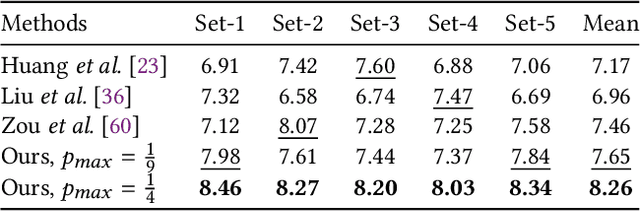



This paper proposes a novel stroke-based rendering (SBR) method that translates images into vivid oil paintings. Previous SBR techniques usually formulate the oil painting problem as pixel-wise approximation. Different from this technique route, we treat oil painting creation as an adaptive sampling problem. Firstly, we compute a probability density map based on the texture complexity of the input image. Then we use the Voronoi algorithm to sample a set of pixels as the stroke anchors. Next, we search and generate an individual oil stroke at each anchor. Finally, we place all the strokes on the canvas to obtain the oil painting. By adjusting the hyper-parameter maximum sampling probability, we can control the oil painting fineness in a linear manner. Comparison with existing state-of-the-art oil painting techniques shows that our results have higher fidelity and more realistic textures. A user opinion test demonstrates that people behave more preference toward our oil paintings than the results of other methods. More interesting results and the code are in https://github.com/TZYSJTU/Im2Oil.
Data Streaming and Traffic Gathering in Mesh-based NoC for Deep Neural Network Acceleration
Aug 01, 2021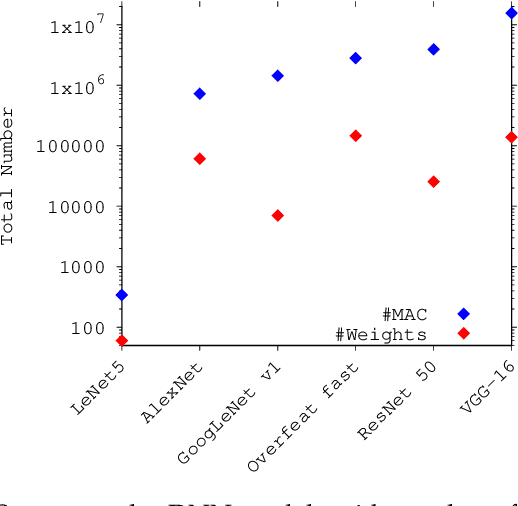
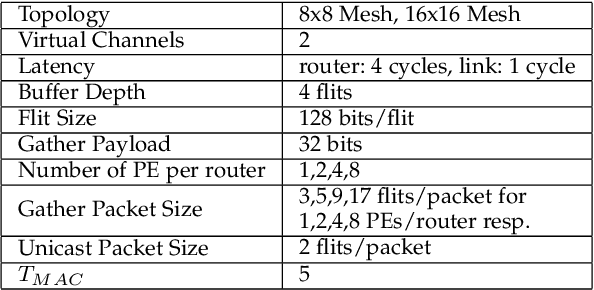
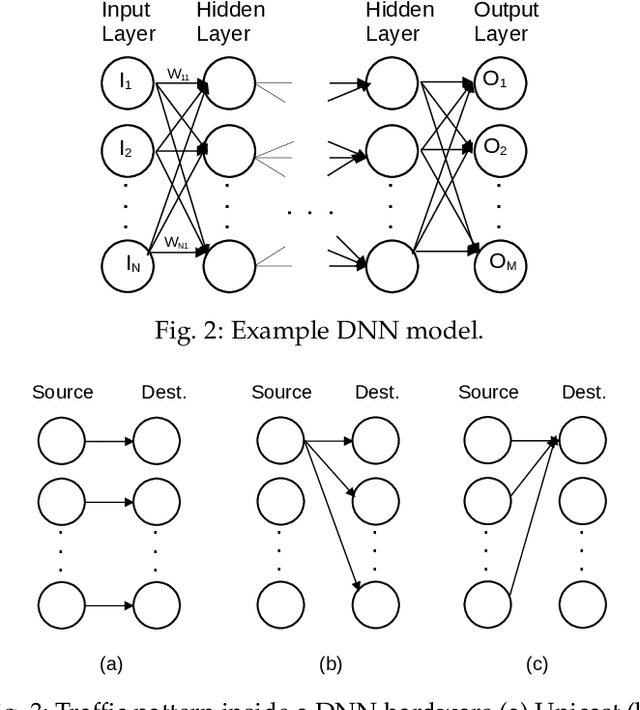
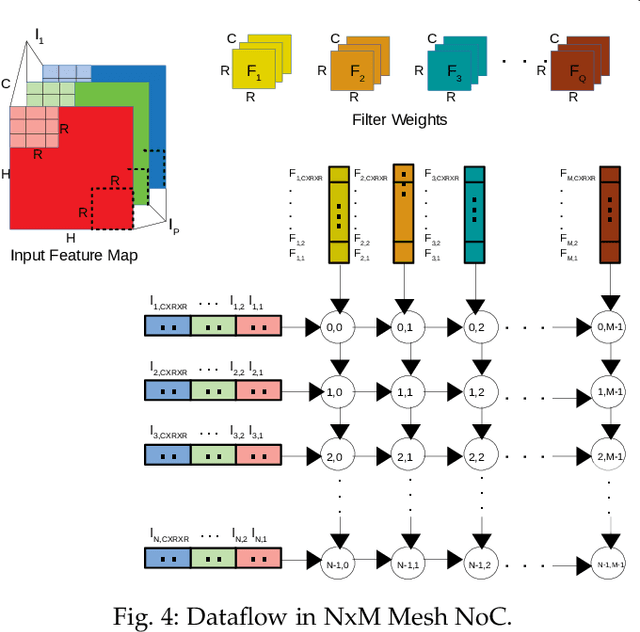
The increasing popularity of deep neural network (DNN) applications demands high computing power and efficient hardware accelerator architecture. DNN accelerators use a large number of processing elements (PEs) and on-chip memory for storing weights and other parameters. As the communication backbone of a DNN accelerator, networks-on-chip (NoC) play an important role in supporting various dataflow patterns and enabling processing with communication parallelism in a DNN accelerator. However, the widely used mesh-based NoC architectures inherently cannot support the efficient one-to-many and many-to-one traffic largely existing in DNN workloads. In this paper, we propose a modified mesh architecture with a one-way/two-way streaming bus to speedup one-to-many (multicast) traffic, and the use of gather packets to support many-to-one (gather) traffic. The analysis of the runtime latency of a convolutional layer shows that the two-way streaming architecture achieves better improvement than the one-way streaming architecture for an Output Stationary (OS) dataflow architecture. The simulation results demonstrate that the gather packets can help to reduce the runtime latency up to 1.8 times and network power consumption up to 1.7 times, compared with the repetitive unicast method on modified mesh architectures supporting two-way streaming.
Improving the Performance of a NoC-based CNN Accelerator with Gather Support
Aug 01, 2021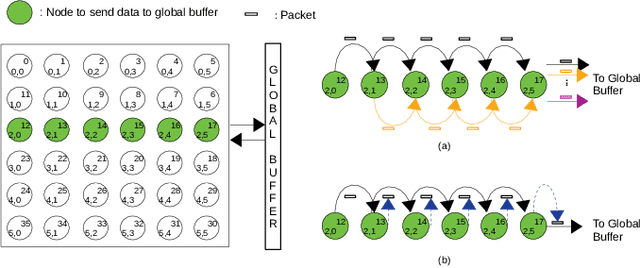
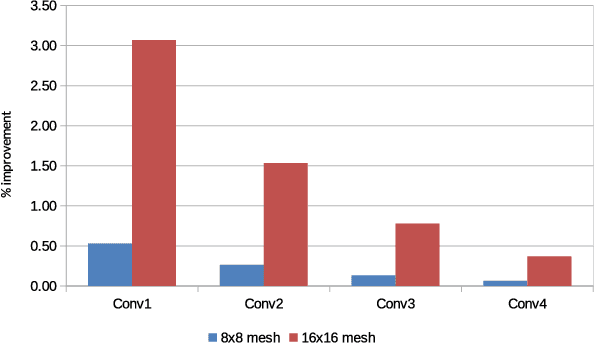
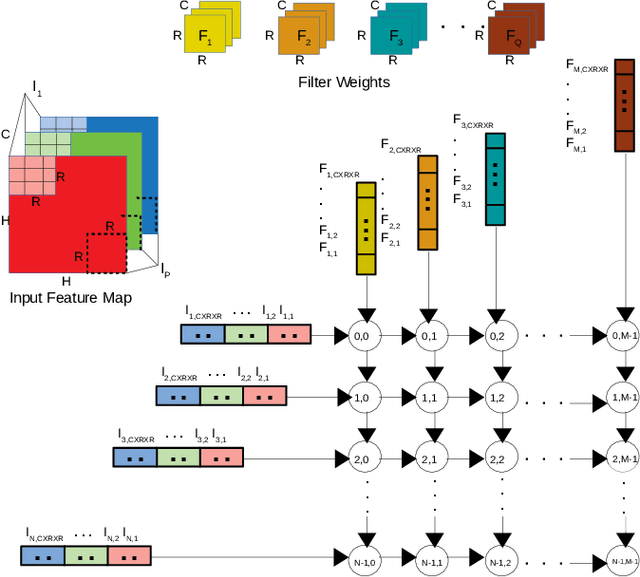
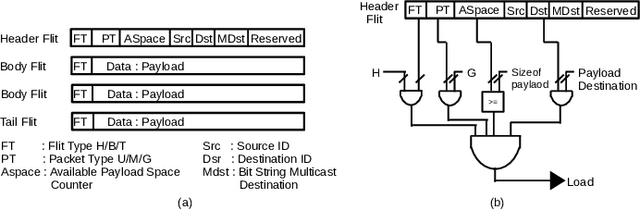
The increasing application of deep learning technology drives the need for an efficient parallel computing architecture for Convolutional Neural Networks (CNNs). A significant challenge faced when designing a many-core CNN accelerator is to handle the data movement between the processing elements. The CNN workload introduces many-to-one traffic in addition to one-to-one and one-to-many traffic. As the de-facto standard for on-chip communication, Network-on-Chip (NoC) can support various unicast and multicast traffic. For many-to-one traffic, repetitive unicast is employed which is not an efficient way. In this paper, we propose to use the gather packet on mesh-based NoCs employing output stationary systolic array in support of many-to-one traffic. The gather packet will collect the data from the intermediate nodes eventually leading to the destination efficiently. This method is evaluated using the traffic traces generated from the convolution layer of AlexNet and VGG-16 with improvement in the latency and power than the repetitive unicast method.
Sketch Generation with Drawing Process Guided by Vector Flow and Grayscale
Dec 16, 2020
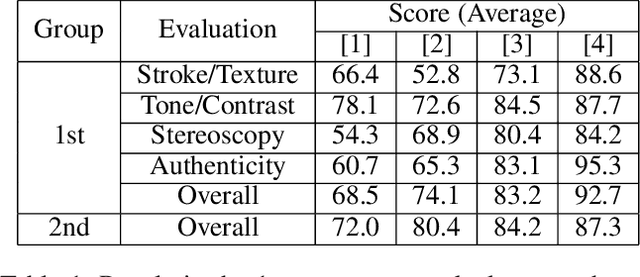
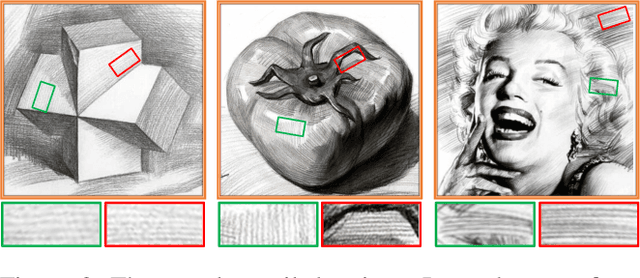

We propose a novel image-to-pencil translation method that could not only generate high-quality pencil sketches but also offer the drawing process. Existing pencil sketch algorithms are based on texture rendering rather than the direct imitation of strokes, making them unable to show the drawing process but only a final result. To address this challenge, we first establish a pencil stroke imitation mechanism. Next, we develop a framework with three branches to guide stroke drawing: the first branch guides the direction of the strokes, the second branch determines the shade of the strokes, and the third branch enhances the details further. Under this framework's guidance, we can produce a pencil sketch by drawing one stroke every time. Our method is fully interpretable. Comparison with existing pencil drawing algorithms shows that our method is superior to others in terms of texture quality, style, and user evaluation.
DATE: Defense Against TEmperature Side-Channel Attacks in DVFS Enabled MPSoCs
Jul 02, 2020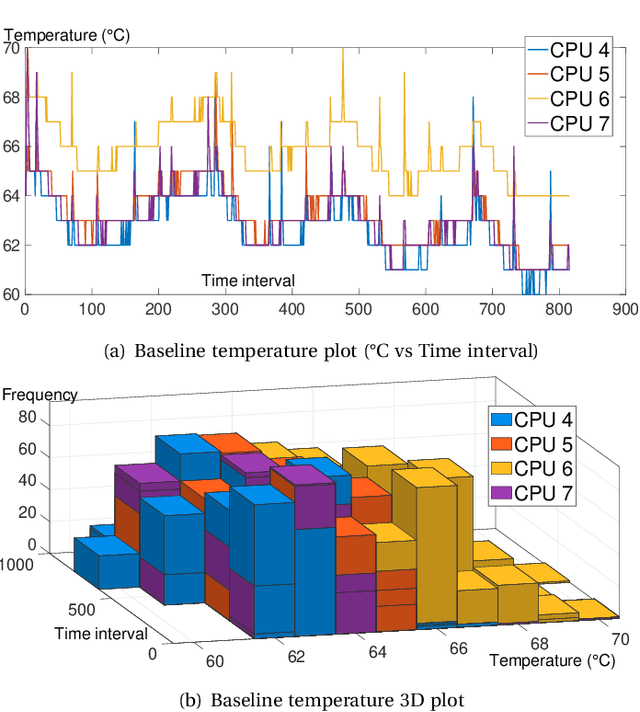


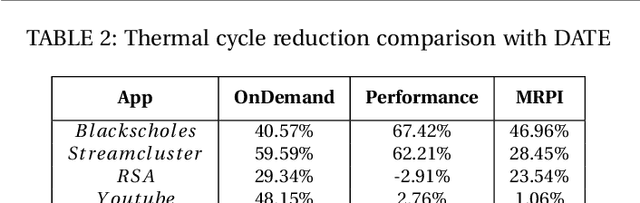
Given the constant rise in utilizing embedded devices in daily life, side channels remain a challenge to information flow control and security in such systems. One such important security flaw could be exploited through temperature side-channel attacks, where heat dissipation and propagation from the processing elements are observed over time in order to deduce security flaws. In our proposed methodology, DATE: Defense Against TEmperature side-channel attacks, we propose a novel approach of reducing spatial and temporal thermal gradient, which makes the system more secure against temperature side-channel attacks, and at the same time increases the reliability of the device in terms of lifespan. In this paper, we have also introduced a new metric, Thermal-Security-in-Multi-Processors (TSMP), which is capable of quantifying the security against temperature side-channel attacks on computing systems, and DATE is evaluated to be 139.24% more secure at the most for certain applications than the state-of-the-art, while reducing thermal cycle by 67.42% at the most.