 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing Microscopic Objects in Fluorescence Live Imaging by Video-to-video Translation Based on A Spatial-temporal Generative Adversarial Network
Feb 22, 2025


In spite of being a valuable tool to simultaneously visualize multiple types of subcellular structures using spectrally distinct fluorescent labels, a standard fluoresce microscope is only able to identify a few microscopic objects; such a limit is largely imposed by the number of fluorescent labels available to the sample. In order to simultaneously visualize more objects, in this paper, we propose to use video-to-video translation that mimics the development process of microscopic objects. In essence, we use a microscopy video-to-video translation framework namely Spatial-temporal Generative Adversarial Network (STGAN) to reveal the spatial and temporal relationships between the microscopic objects, after which a microscopy video of one object can be translated to another object in a different domain. The experimental results confirm that the proposed STGAN is effective in microscopy video-to-video translation that mitigates the spectral conflicts caused by the limited fluorescent labels, allowing multiple microscopic objects be simultaneously visualized.
Multi-Object Portion Tracking in 4D Fluorescence Microscopy Imagery with Deep Feature Maps
Nov 26, 2019


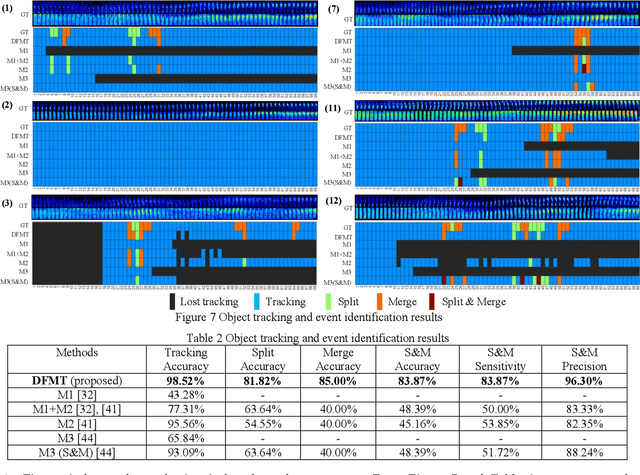
3D fluorescence microscopy of living organisms has increasingly become an essential and powerful tool in biomedical research and diagnosis. An exploding amount of imaging data has been collected, whereas efficient and effective computational tools to extract information from them are still lagging behind. This is largely due to the challenges in analyzing biological data. Interesting biological structures are not only small, but are often morphologically irregular and highly dynamic. Although tracking cells in live organisms has been studied for years, existing tracking methods for cells are not effective in tracking subcellular structures, such as protein complexes, which feature in continuous morphological changes including split and merge, in addition to fast migration and complex motion. In this paper, we first define the problem of multi-object portion tracking to model the protein object tracking process. A multi-object tracking method with portion matching is proposed based on 3D segmentation results. The proposed method distills deep feature maps from deep networks, then recognizes and matches object portions using an extended search. Experimental results confirm that the proposed method achieves 2.96% higher on consistent tracking accuracy and 35.48% higher on event identification accuracy than the state-of-art methods.