 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVP-AP: Self-supervised Automatic View Positioning in 3D cardiac CT via Atlas Prompting
Apr 08, 2025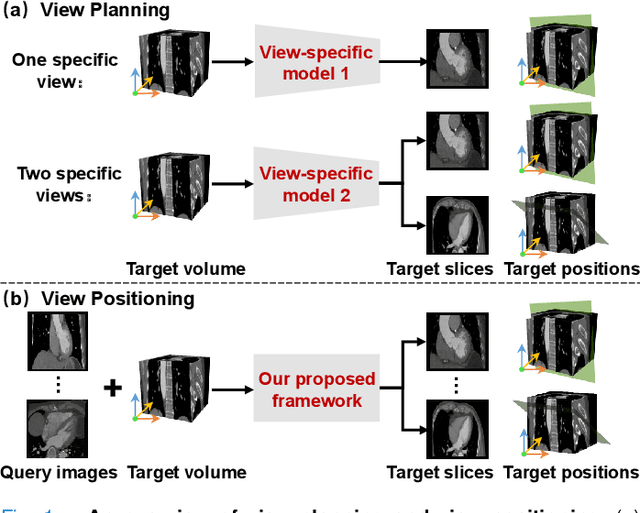
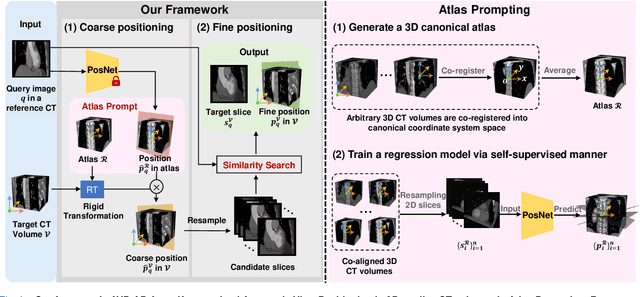
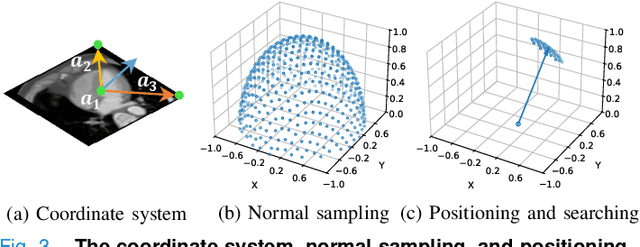
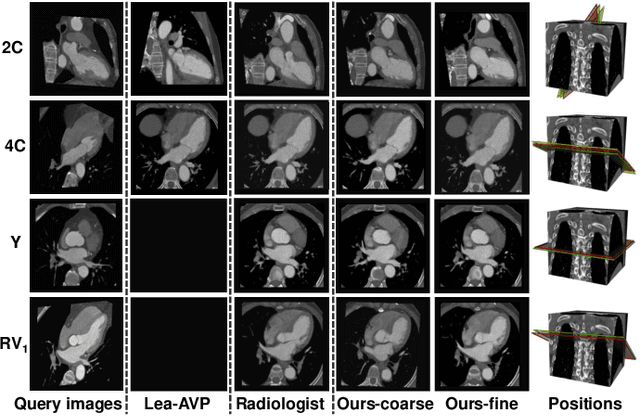
Automatic view positioning is crucial for cardiac computed tomography (CT) examinations, including disease diagnosis and surgical planning. However, it is highly challenging due to individual variability and large 3D search space. Existing work needs labor-intensive and time-consuming manual annotations to train view-specific models, which are limited to predicting only a fixed set of planes. However, in real clinical scenarios, the challenge of positioning semantic 2D slices with any orientation into varying coordinate space in arbitrary 3D volume remains unsolved. We thus introduce a novel framework, AVP-AP, the first to use Atlas Prompting for self-supervised Automatic View Positioning in the 3D CT volume. Specifically, this paper first proposes an atlas prompting method, which generates a 3D canonical atlas and trains a network to map slices into their corresponding positions in the atlas space via a self-supervised manner. Then, guided by atlas prompts corresponding to the given query images in a reference CT, we identify the coarse positions of slices in the target CT volume using rigid transformation between the 3D atlas and target CT volume, effectively reducing the search space. Finally, we refine the coarse positions by maximizing the similarity between the predicted slices and the query images in the feature space of a given foundation model. Our framework is flexible and efficient compared to other methods, outperforming other methods by 19.8% average structural similarity (SSIM) in arbitrary view positioning and achieving 9% SSIM in two-chamber view compared to four radiologists. Meanwhile, experiments on a public dataset validate our framework's generalizability.
* 12 pages, 8 figures, published to TMI
Test-Time Backdoor Attacks on Multimodal Large Language Models
Feb 13, 2024Backdoor attacks are commonly executed by contaminating training data, such that a trigger can activate predetermined harmful effects during the test phase. In this work, we present AnyDoor, a test-time backdoor attack against multimodal large language models (MLLMs), which involves injecting the backdoor into the textual modality using adversarial test images (sharing the same universal perturbation), without requiring access to or modification of the training data. AnyDoor employs similar techniques used in universal adversarial attacks, but distinguishes itself by its ability to decouple the timing of setup and activation of harmful effects. In our experiments, we validate the effectiveness of AnyDoor against popular MLLMs such as LLaVA-1.5, MiniGPT-4, InstructBLIP, and BLIP-2, as well as provide comprehensive ablation studies. Notably, because the backdoor is injected by a universal perturbation, AnyDoor can dynamically change its backdoor trigger prompts/harmful effects, exposing a new challenge for defending against backdoor attacks. Our project page is available at https://sail-sg.github.io/AnyDoor/.
Set-level Guidance Attack: Boosting Adversarial Transferability of Vision-Language Pre-training Models
Jul 26, 2023Vision-language pre-training (VLP) models have shown vulnerability to adversarial examples in multimodal tasks. Furthermore, malicious adversaries can be deliberately transferred to attack other black-box models. However, existing work has mainly focused on investigating white-box attacks. In this paper, we present the first study to investigate the adversarial transferability of recent VLP models. We observe that existing methods exhibit much lower transferability, compared to the strong attack performance in white-box settings. The transferability degradation is partly caused by the under-utilization of cross-modal interactions. Particularly, unlike unimodal learning, VLP models rely heavily on cross-modal interactions and the multimodal alignments are many-to-many, e.g., an image can be described in various natural languages. To this end, we propose a highly transferable Set-level Guidance Attack (SGA) that thoroughly leverages modality interactions and incorporates alignment-preserving augmentation with cross-modal guidance. Experimental results demonstrate that SGA could generate adversarial examples that can strongly transfer across different VLP models on multiple downstream vision-language tasks. On image-text retrieval, SGA significantly enhances the attack success rate for transfer attacks from ALBEF to TCL by a large margin (at least 9.78% and up to 30.21%), compared to the state-of-the-art.
Detect All Abuse! Toward Universal Abusive Language Detection Models
Oct 09, 2020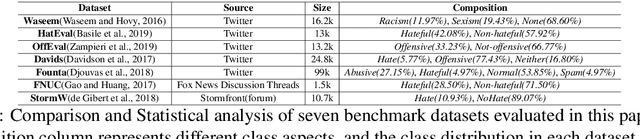
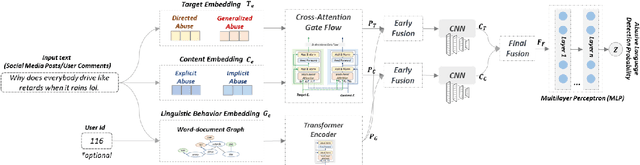

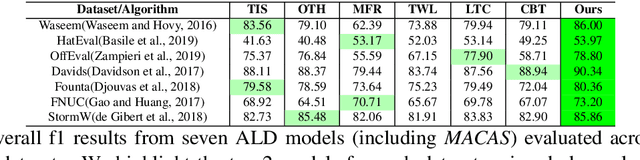
Online abusive language detection (ALD) has become a societal issue of increasing importance in recent years. Several previous works in online ALD focused on solving a single abusive language problem in a single domain, like Twitter, and have not been successfully transferable to the general ALD task or domain. In this paper, we introduce a new generic ALD framework, MACAS, which is capable of addressing several types of ALD tasks across different domains. Our generic framework covers multi-aspect abusive language embeddings that represent the target and content aspects of abusive language and applies a textual graph embedding that analyses the user's linguistic behaviour. Then, we propose and use the cross-attention gate flow mechanism to embrace multiple aspects of abusive language. Quantitative and qualitative evaluation results show that our ALD algorithm rivals or exceeds the six state-of-the-art ALD algorithms across seven ALD datasets covering multiple aspects of abusive language and different online community domains.