 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVP-AP: Self-supervised Automatic View Positioning in 3D cardiac CT via Atlas Prompting
Paper and Code
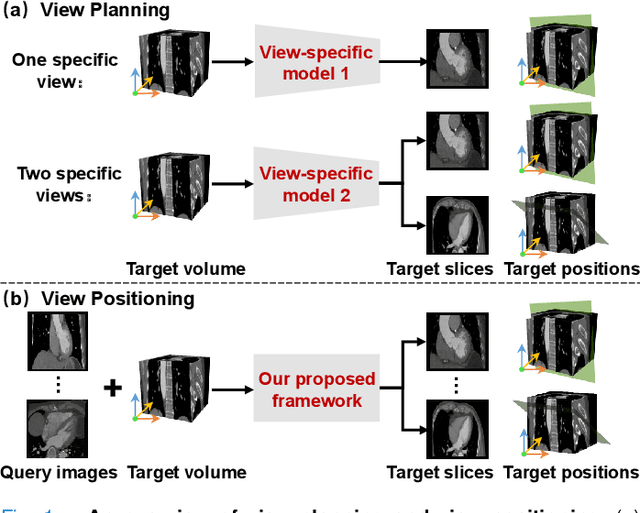
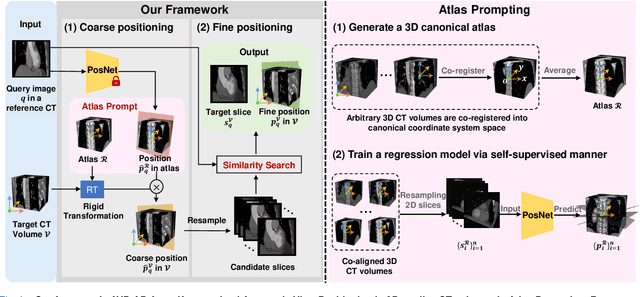
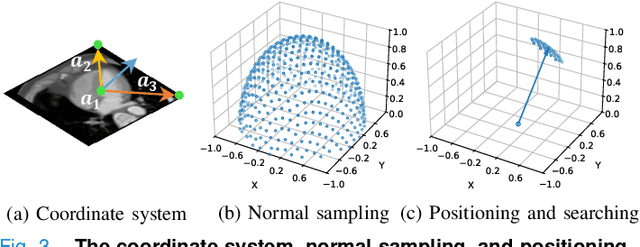
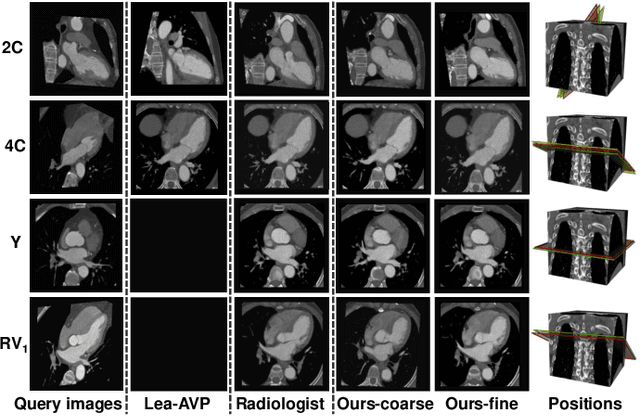
Automatic view positioning is crucial for cardiac computed tomography (CT) examinations, including disease diagnosis and surgical planning. However, it is highly challenging due to individual variability and large 3D search space. Existing work needs labor-intensive and time-consuming manual annotations to train view-specific models, which are limited to predicting only a fixed set of planes. However, in real clinical scenarios, the challenge of positioning semantic 2D slices with any orientation into varying coordinate space in arbitrary 3D volume remains unsolved. We thus introduce a novel framework, AVP-AP, the first to use Atlas Prompting for self-supervised Automatic View Positioning in the 3D CT volume. Specifically, this paper first proposes an atlas prompting method, which generates a 3D canonical atlas and trains a network to map slices into their corresponding positions in the atlas space via a self-supervised manner. Then, guided by atlas prompts corresponding to the given query images in a reference CT, we identify the coarse positions of slices in the target CT volume using rigid transformation between the 3D atlas and target CT volume, effectively reducing the search space. Finally, we refine the coarse positions by maximizing the similarity between the predicted slices and the query images in the feature space of a given foundation model. Our framework is flexible and efficient compared to other methods, outperforming other methods by 19.8% average structural similarity (SSIM) in arbitrary view positioning and achieving 9% SSIM in two-chamber view compared to four radiologists. Meanwhile, experiments on a public dataset validate our framework's generalizability.