 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeO-Researcher: An Open Ended Deep Research Model via Multi-Agent Distillation and Agentic RL
Jan 07, 2026The performance gap between closed-source and open-source large language models (LLMs) is largely attributed to disparities in access to high-quality training data. To bridge this gap, we introduce a novel framework for the automated synthesis of sophisticated, research-grade instructional data. Our approach centers on a multi-agent workflow where collaborative AI agents simulate complex tool-integrated reasoning to generate diverse and high-fidelity data end-to-end. Leveraging this synthesized data, we develop a two-stage training strategy that integrates supervised fine-tuning with a novel reinforcement learning method, designed to maximize model alignment and capability. Extensive experiments demonstrate that our framework empowers open-source models across multiple scales, enabling them to achieve new state-of-the-art performance on the major deep research benchmark. This work provides a scalable and effective pathway for advancing open-source LLMs without relying on proprietary data or models.
TaskCraft: Automated Generation of Agentic Tasks
Jun 11, 2025Agentic tasks, which require multi-step problem solving with autonomy, tool use, and adaptive reasoning, are becoming increasingly central to the advancement of NLP and AI. However, existing instruction data lacks tool interaction, and current agentic benchmarks rely on costly human annotation, limiting their scalability. We introduce \textsc{TaskCraft}, an automated workflow for generating difficulty-scalable, multi-tool, and verifiable agentic tasks with execution trajectories. TaskCraft expands atomic tasks using depth-based and width-based extensions to create structurally and hierarchically complex challenges. Empirical results show that these tasks improve prompt optimization in the generation workflow and enhance supervised fine-tuning of agentic foundation models. We present a large-scale synthetic dataset of approximately 36,000 tasks with varying difficulty to support future research on agent tuning and evaluation.
Temporal Action Localization with Enhanced Instant Discriminability
Sep 11, 2023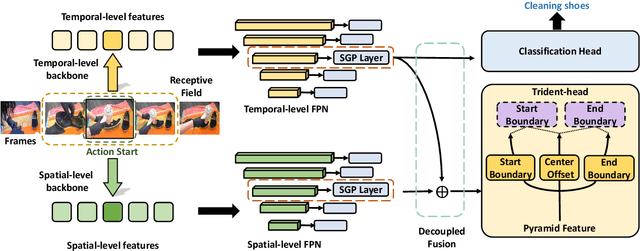
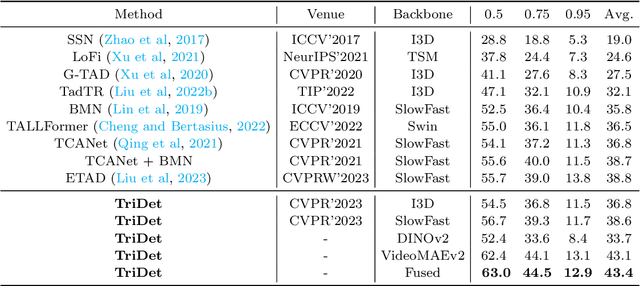
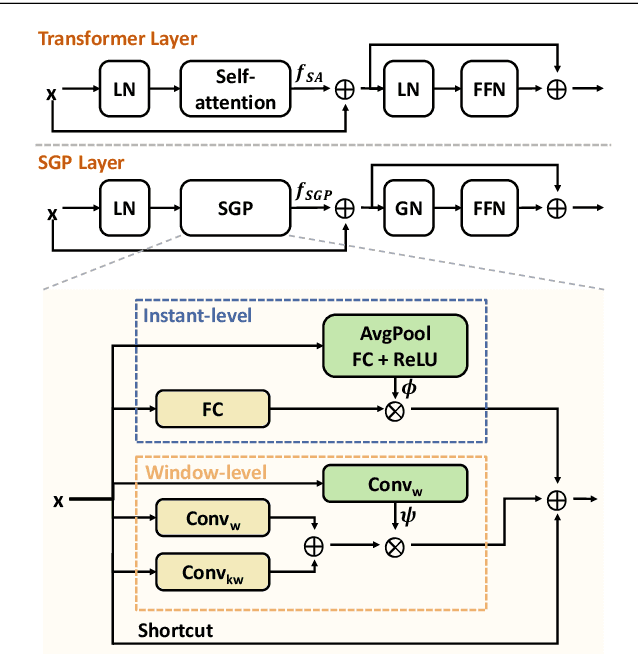
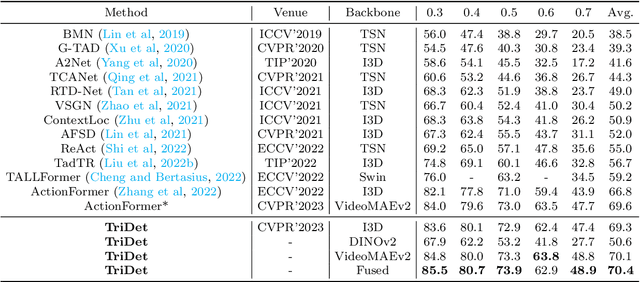
Temporal action detection (TAD) aims to detect all action boundaries and their corresponding categories in an untrimmed video. The unclear boundaries of actions in videos often result in imprecise predictions of action boundaries by existing methods. To resolve this issue, we propose a one-stage framework named TriDet. First, we propose a Trident-head to model the action boundary via an estimated relative probability distribution around the boundary. Then, we analyze the rank-loss problem (i.e. instant discriminability deterioration) in transformer-based methods and propose an efficient scalable-granularity perception (SGP) layer to mitigate this issue. To further push the limit of instant discriminability in the video backbone, we leverage the strong representation capability of pretrained large models and investigate their performance on TAD. Last, considering the adequate spatial-temporal context for classification, we design a decoupled feature pyramid network with separate feature pyramids to incorporate rich spatial context from the large model for localization. Experimental results demonstrate the robustness of TriDet and its state-of-the-art performance on multiple TAD datasets, including hierarchical (multilabel) TAD datasets.
TriDet: Temporal Action Detection with Relative Boundary Modeling
Mar 16, 2023In this paper, we present a one-stage framework TriDet for temporal action detection. Existing methods often suffer from imprecise boundary predictions due to the ambiguous action boundaries in videos. To alleviate this problem, we propose a novel Trident-head to model the action boundary via an estimated relative probability distribution around the boundary. In the feature pyramid of TriDet, we propose an efficient Scalable-Granularity Perception (SGP) layer to mitigate the rank loss problem of self-attention that takes place in the video features and aggregate information across different temporal granularities. Benefiting from the Trident-head and the SGP-based feature pyramid, TriDet achieves state-of-the-art performance on three challenging benchmarks: THUMOS14, HACS and EPIC-KITCHEN 100, with lower computational costs, compared to previous methods. For example, TriDet hits an average mAP of $69.3\%$ on THUMOS14, outperforming the previous best by $2.5\%$, but with only $74.6\%$ of its latency. The code is released to https://github.com/sssste/TriDet.
Benefits of Permutation-Equivariance in Auction Mechanisms
Oct 11, 2022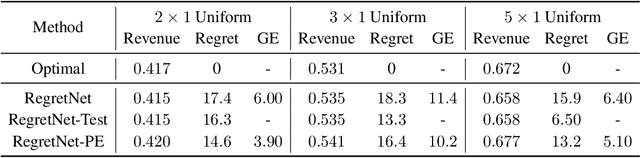
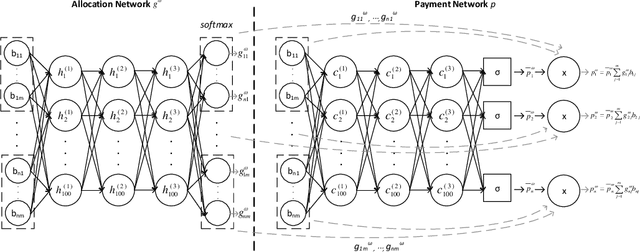
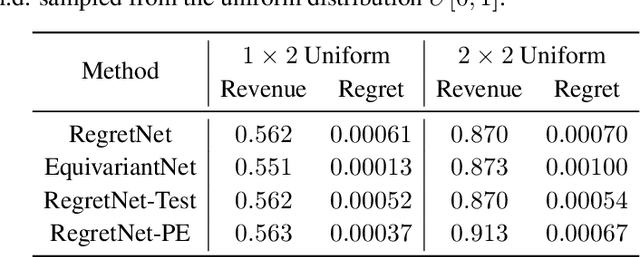
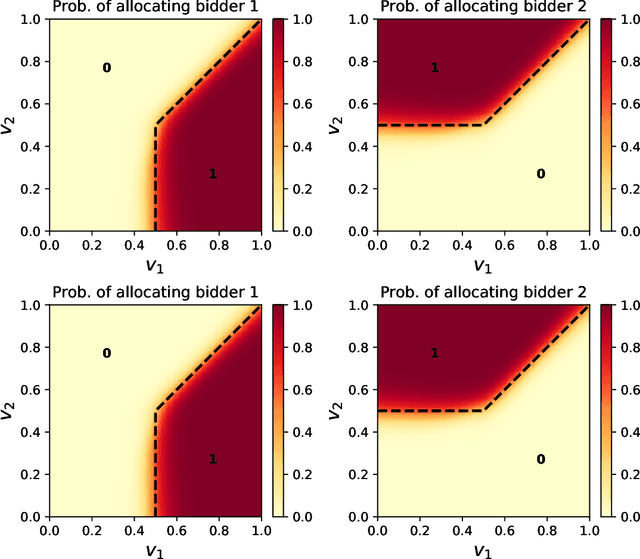
Designing an incentive-compatible auction mechanism that maximizes the auctioneer's revenue while minimizes the bidders' ex-post regret is an important yet intricate problem in economics. Remarkable progress has been achieved through learning the optimal auction mechanism by neural networks. In this paper, we consider the popular additive valuation and symmetric valuation setting; i.e., the valuation for a set of items is defined as the sum of all items' valuations in the set, and the valuation distribution is invariant when the bidders and/or the items are permutated. We prove that permutation-equivariant neural networks have significant advantages: the permutation-equivariance decreases the expected ex-post regret, improves the model generalizability, while maintains the expected revenue invariant. This implies that the permutation-equivariance helps approach the theoretically optimal dominant strategy incentive compatible condition, and reduces the required sample complexity for desired generalization. Extensive experiments fully support our theory. To our best knowledge, this is the first work towards understanding the benefits of permutation-equivariance in auction mechanisms.
ReAct: Temporal Action Detection with Relational Queries
Jul 14, 2022



This work aims at advancing temporal action detection (TAD) using an encoder-decoder framework with action queries, similar to DETR, which has shown great success in object detection. However, the framework suffers from several problems if directly applied to TAD: the insufficient exploration of inter-query relation in the decoder, the inadequate classification training due to a limited number of training samples, and the unreliable classification scores at inference. To this end, we first propose a relational attention mechanism in the decoder, which guides the attention among queries based on their relations. Moreover, we propose two losses to facilitate and stabilize the training of action classification. Lastly, we propose to predict the localization quality of each action query at inference in order to distinguish high-quality queries. The proposed method, named ReAct, achieves the state-of-the-art performance on THUMOS14, with much lower computational costs than previous methods. Besides, extensive ablation studies are conducted to verify the effectiveness of each proposed component. The code is available at https://github.com/sssste/React.