 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRL Excursions during Pre-Training: Re-examining Policy Optimization for LLM training
Jun 02, 2026The standard LLM training pipeline applies reinforcement learning (RL) only after pre-training and supervised fine-tuning (SFT). We question this status quo by training a LLM from scratch and applying RL, SFT, and SFT followed by RL directly to intermediate pre-training checkpoints. We find that RL is effective very early, and often matches the full SFT$\to$RL pipeline early as well. Through experiments on harder problems, we find that targeted pre-training data composition is a strong lever for RL effectiveness, even more so than model scale. Beyond reasoning accuracy, applying RL directly to base checkpoints expands the model's distribution; the sharpening effect reported in recent work arises only when RL follows SFT. The general capabilities of the model remain essentially unchanged by RL, while they degrade following SFT. Finally, we merge RL and SFT objectives by parallel averaging, which outperforms across all other training methods discussed, across metrics, while preserving general capabilities. Together, these results suggest that LLM training might benefit from an expanded use of RL.
Do We Really Need External Tools to Mitigate Hallucinations? SIRA: Shared-Prefix Internal Reconstruction of Attribution
May 14, 2026Large vision-language models (LVLMs) often hallucinate when language priors dominate weak or ambiguous visual evidence. Existing contrastive decoding methods mitigate this problem by comparing predictions from the original image with those from externally perturbed visual inputs, but such references can introduce off-manifold artifacts and require costly extra forward passes. We propose SIRA, a training-free internal contrastive decoding framework that constructs a counterfactual reference inside the same LVLM by exploiting the staged information flow of multimodal transformers. Instead of removing visual information from the input, SIRA first lets image and text tokens interact through a shared prefix, forming an aligned multimodal state that preserves prompt interpretation, decoding history, positional structure, and early visual grounding. It then forks a counterfactual branch in later transformer layers, where attention to image-token positions is masked. This branch retains the shared multimodal context but lacks continued access to fine-grained visual evidence, yielding a language-prior-dominated internal reference for token-level contrast. During decoding, SIRA suppresses tokens that remain strong without late visual access and favors predictions whose advantage depends on the full visual pathway. Experiments on POPE, CHAIR, and AMBER with Qwen2.5-VL and LLaVA-v1.5 show that SIRA consistently reduces hallucinations while preserving descriptive coverage and incurring lower overhead than two-pass contrastive decoding. SIRA requires no training, external verifier, or perturbed input, and applies to open-weight LVLMs with white-box inference access.
Incentivizing Temporal-Awareness in Egocentric Video Understanding Models
Mar 28, 2026Multimodal large language models (MLLMs) have recently shown strong performance in visual understanding, yet they often lack temporal awareness, particularly in egocentric settings where reasoning depends on the correct ordering and evolution of events. This deficiency stems in part from training objectives that fail to explicitly reward temporal reasoning and instead rely on frame-level spatial shortcuts. To address this limitation, we propose Temporal Global Policy Optimization (TGPO), a reinforcement learning with verifiable rewards (RLVR) algorithm designed to incentivize temporal awareness in MLLMs. TGPO contrasts model outputs generated from temporally ordered versus shuffled video frames to derive calibrated, globally normalized reward signals that explicitly favor temporally coherent reasoning. Integrated with GRPO and GSPO, TGPO supports cold-start RL training and effectively suppresses spatial shortcut behaviors learned by existing MLLMs. Experiments across five egocentric video benchmarks demonstrate that TGPO consistently improves temporal grounding and causal coherence, outperforming prior RL-based video reasoning approaches. Our results suggest that TGPO offers a simple and scalable pathway toward temporally robust MLLMs for egocentric video understanding.
Drawback of Enforcing Equivariance and its Compensation via the Lens of Expressive Power
Dec 10, 2025Equivariant neural networks encode symmetry as an inductive bias and have achieved strong empirical performance in wide domains. However, their expressive power remains not well understood. Focusing on 2-layer ReLU networks, this paper investigates the impact of equivariance constraints on the expressivity of equivariant and layer-wise equivariant networks. By examining the boundary hyperplanes and the channel vectors of ReLU networks, we construct an example showing that equivariance constraints could strictly limit expressive power. However, we demonstrate that this drawback can be compensated via enlarging the model size. Furthermore, we show that despite a larger model size, the resulting architecture could still correspond to a hypothesis space with lower complexity, implying superior generalizability for equivariant networks.
BootOOD: Self-Supervised Out-of-Distribution Detection via Synthetic Sample Exposure under Neural Collapse
Nov 17, 2025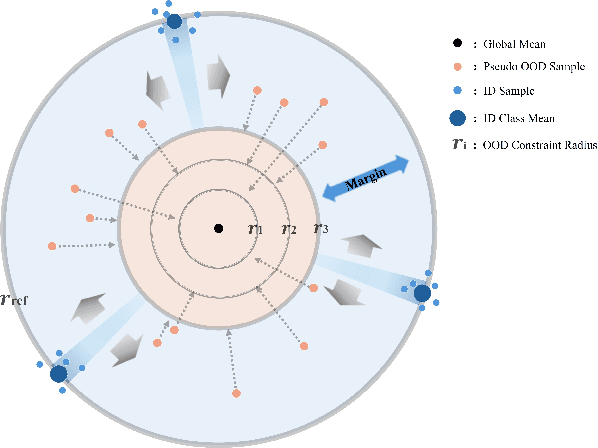
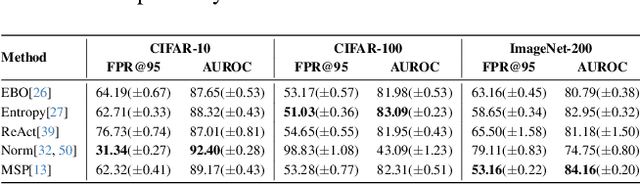
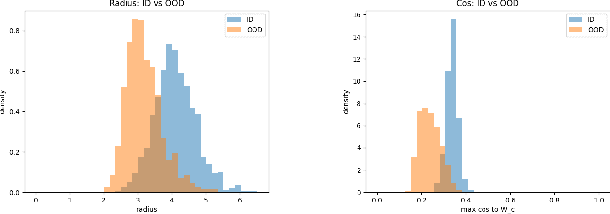
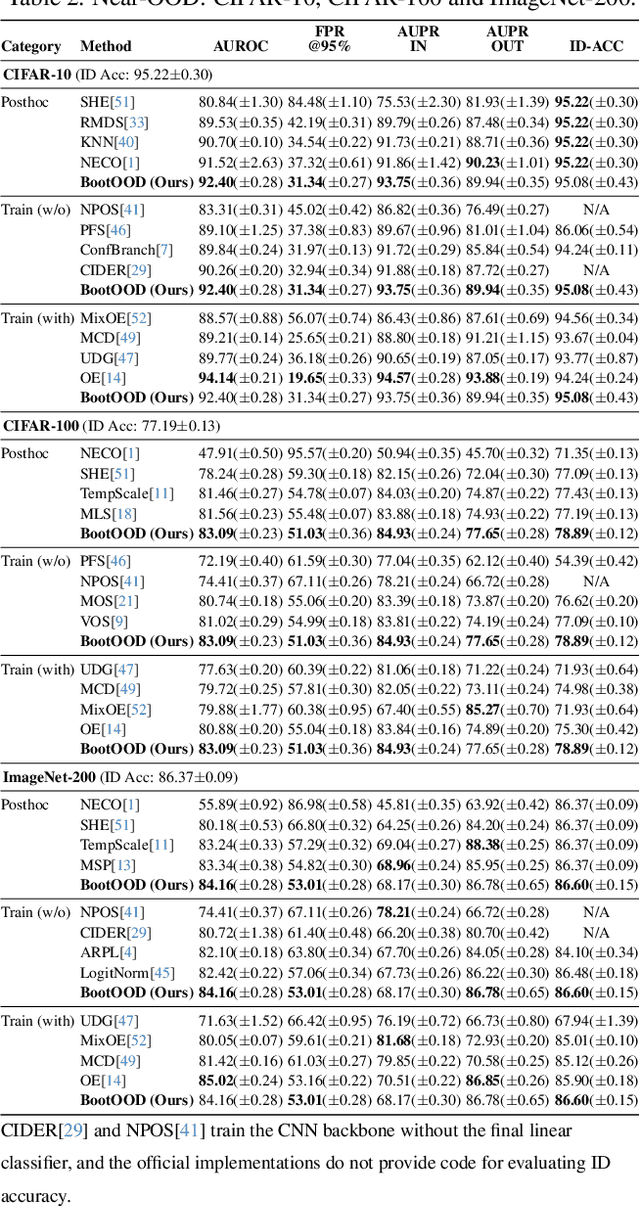
Out-of-distribution (OOD) detection is critical for deploying image classifiers in safety-sensitive environments, yet existing detectors often struggle when OOD samples are semantically similar to the in-distribution (ID) classes. We present BootOOD, a fully self-supervised OOD detection framework that bootstraps exclusively from ID data and is explicitly designed to handle semantically challenging OOD samples. BootOOD synthesizes pseudo-OOD features through simple transformations of ID representations and leverages Neural Collapse (NC), where ID features cluster tightly around class means with consistent feature norms. Unlike prior approaches that aim to constrain OOD features into subspaces orthogonal to the collapsed ID means, BootOOD introduces a lightweight auxiliary head that performs radius-based classification on feature norms. This design decouples OOD detection from the primary classifier and imposes a relaxed requirement: OOD samples are learned to have smaller feature norms than ID features, which is easier to satisfy when ID and OOD are semantically close. Experiments on CIFAR-10, CIFAR-100, and ImageNet-200 show that BootOOD outperforms prior post-hoc methods, surpasses training-based methods without outlier exposure, and is competitive with state-of-the-art outlier-exposure approaches while maintaining or improving ID accuracy.
COMPASS: A Multi-Turn Benchmark for Tool-Mediated Planning & Preference Optimization
Oct 08, 2025
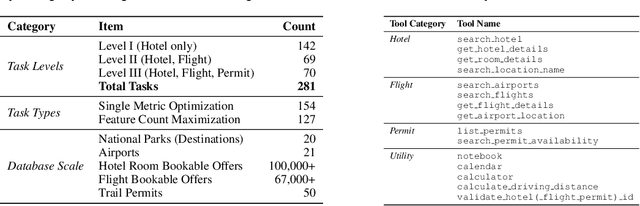
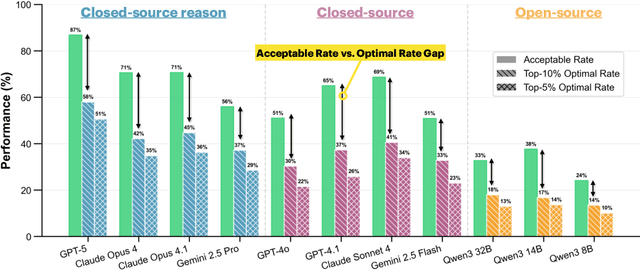

Real-world large language model (LLM) agents must master strategic tool use and user preference optimization through multi-turn interactions to assist users with complex planning tasks. We introduce COMPASS (Constrained Optimization through Multi-turn Planning and Strategic Solutions), a benchmark that evaluates agents on realistic travel-planning scenarios. We cast travel planning as a constrained preference optimization problem, where agents must satisfy hard constraints while simultaneously optimizing soft user preferences. To support this, we build a realistic travel database covering transportation, accommodation, and ticketing for 20 U.S. National Parks, along with a comprehensive tool ecosystem that mirrors commercial booking platforms. Evaluating state-of-the-art models, we uncover two critical gaps: (i) an acceptable-optimal gap, where agents reliably meet constraints but fail to optimize preferences, and (ii) a plan-coordination gap, where performance collapses on multi-service (flight and hotel) coordination tasks, especially for open-source models. By grounding reasoning and planning in a practical, user-facing domain, COMPASS provides a benchmark that directly measures an agent's ability to optimize user preferences in realistic tasks, bridging theoretical advances with real-world impact.
From Static to Adaptive Defense: Federated Multi-Agent Deep Reinforcement Learning-Driven Moving Target Defense Against DoS Attacks in UAV Swarm Networks
Jun 09, 2025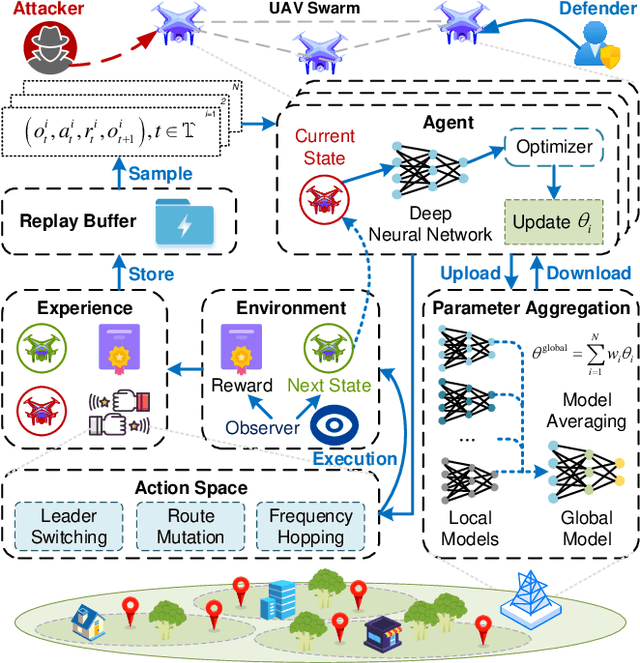
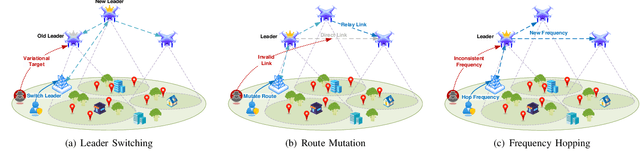
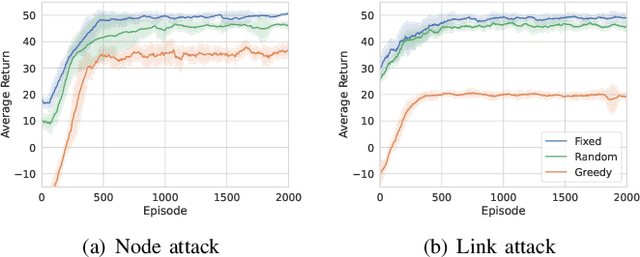
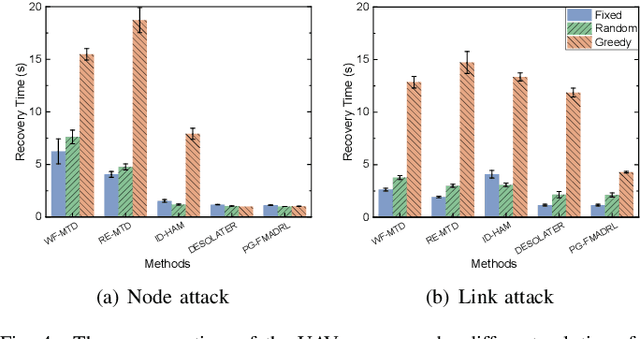
The proliferation of unmanned aerial vehicle (UAV) swarms has enabled a wide range of mission-critical applications, but also exposes UAV networks to severe Denial-of-Service (DoS) threats due to their open wireless environment, dynamic topology, and resource constraints. Traditional static or centralized defense mechanisms are often inadequate for such dynamic and distributed scenarios. To address these challenges, we propose a novel federated multi-agent deep reinforcement learning (FMADRL)-driven moving target defense (MTD) framework for proactive and adaptive DoS mitigation in UAV swarm networks. Specifically, we design three lightweight and coordinated MTD mechanisms, including leader switching, route mutation, and frequency hopping, that leverage the inherent flexibility of UAV swarms to disrupt attacker efforts and enhance network resilience. The defense problem is formulated as a multi-agent partially observable Markov decision process (POMDP), capturing the distributed, resource-constrained, and uncertain nature of UAV swarms under attack. Each UAV is equipped with a local policy agent that autonomously selects MTD actions based on partial observations and local experiences. By employing a policy gradient-based FMADRL algorithm, UAVs collaboratively optimize their defense policies via reward-weighted aggregation, enabling distributed learning without sharing raw data and thus reducing communication overhead. Extensive simulations demonstrate that our approach significantly outperforms state-of-the-art baselines, achieving up to a 34.6% improvement in attack mitigation rate, a reduction in average recovery time of up to 94.6%, and decreases in energy consumption and defense cost by as much as 29.3% and 98.3%, respectively, while maintaining robust mission continuity under various DoS attack strategies.
Decomposing Elements of Problem Solving: What "Math" Does RL Teach?
May 28, 2025Mathematical reasoning tasks have become prominent benchmarks for assessing the reasoning capabilities of LLMs, especially with reinforcement learning (RL) methods such as GRPO showing significant performance gains. However, accuracy metrics alone do not support fine-grained assessment of capabilities and fail to reveal which problem-solving skills have been internalized. To better understand these capabilities, we propose to decompose problem solving into fundamental capabilities: Plan (mapping questions to sequences of steps), Execute (correctly performing solution steps), and Verify (identifying the correctness of a solution). Empirically, we find that GRPO mainly enhances the execution skill-improving execution robustness on problems the model already knows how to solve-a phenomenon we call temperature distillation. More importantly, we show that RL-trained models struggle with fundamentally new problems, hitting a 'coverage wall' due to insufficient planning skills. To explore RL's impact more deeply, we construct a minimal, synthetic solution-tree navigation task as an analogy for mathematical problem-solving. This controlled setup replicates our empirical findings, confirming RL primarily boosts execution robustness. Importantly, in this setting, we identify conditions under which RL can potentially overcome the coverage wall through improved exploration and generalization to new solution paths. Our findings provide insights into the role of RL in enhancing LLM reasoning, expose key limitations, and suggest a path toward overcoming these barriers. Code is available at https://github.com/cfpark00/RL-Wall.
To Backtrack or Not to Backtrack: When Sequential Search Limits Model Reasoning
Apr 09, 2025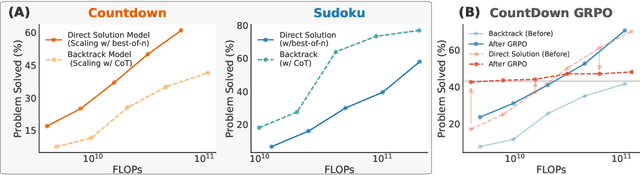

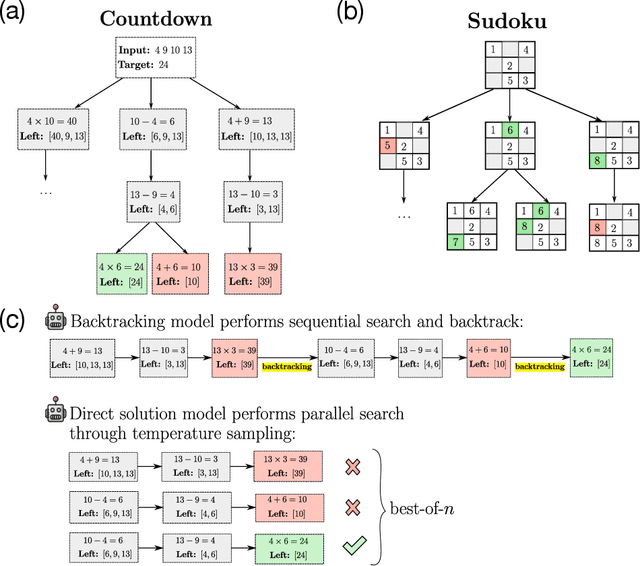
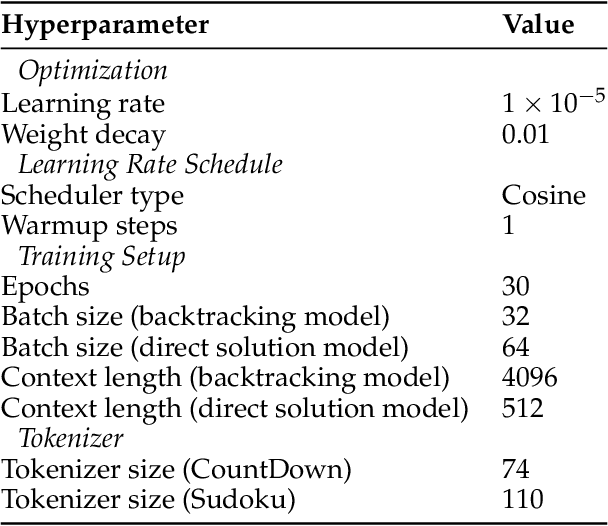
Recent advancements in large language models have significantly improved their reasoning abilities, particularly through techniques involving search and backtracking. Backtracking naturally scales test-time compute by enabling sequential, linearized exploration via long chain-of-thought (CoT) generation. However, this is not the only strategy for scaling test-time compute: parallel sampling with best-of-n selection provides an alternative that generates diverse solutions simultaneously. Despite the growing adoption of sequential search, its advantages over parallel sampling--especially under a fixed compute budget remain poorly understood. In this paper, we systematically compare these two approaches on two challenging reasoning tasks: CountDown and Sudoku. Surprisingly, we find that sequential search underperforms parallel sampling on CountDown but outperforms it on Sudoku, suggesting that backtracking is not universally beneficial. We identify two factors that can cause backtracking to degrade performance: (1) training on fixed search traces can lock models into suboptimal strategies, and (2) explicit CoT supervision can discourage "implicit" (non-verbalized) reasoning. Extending our analysis to reinforcement learning (RL), we show that models with backtracking capabilities benefit significantly from RL fine-tuning, while models without backtracking see limited, mixed gains. Together, these findings challenge the assumption that backtracking universally enhances LLM reasoning, instead revealing a complex interaction between task structure, training data, model scale, and learning paradigm.
Debiasing Kernel-Based Generative Models
Mar 26, 2025We propose a novel two-stage framework of generative models named Debiasing Kernel-Based Generative Models (DKGM) with the insights from kernel density estimation (KDE) and stochastic approximation. In the first stage of DKGM, we employ KDE to bypass the obstacles in estimating the density of data without losing too much image quality. One characteristic of KDE is oversmoothing, which makes the generated image blurry. Therefore, in the second stage, we formulate the process of reducing the blurriness of images as a statistical debiasing problem and develop a novel iterative algorithm to improve image quality, which is inspired by the stochastic approximation. Extensive experiments illustrate that the image quality of DKGM on CIFAR10 is comparable to state-of-the-art models such as diffusion models and GAN models. The performance of DKGM on CelebA 128x128 and LSUN (Church) 128x128 is also competitive. We conduct extra experiments to exploit how the bandwidth in KDE affects the sample diversity and debiasing effect of DKGM. The connections between DKGM and score-based models are also discussed.