 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextFocus: Activation Steering for Contextual Faithfulness in Large Language Models
Jan 07, 2026Large Language Models (LLMs) encode vast amounts of parametric knowledge during pre-training. As world knowledge evolves, effective deployment increasingly depends on their ability to faithfully follow externally retrieved context. When such evidence conflicts with the model's internal knowledge, LLMs often default to memorized facts, producing unfaithful outputs. In this work, we introduce ContextFocus, a lightweight activation steering approach that improves context faithfulness in such knowledge-conflict settings while preserving fluency and efficiency. Unlike prior approaches, our solution requires no model finetuning and incurs minimal inference-time overhead, making it highly efficient. We evaluate ContextFocus on the ConFiQA benchmark, comparing it against strong baselines including ContextDPO, COIECD, and prompting-based methods. Furthermore, we show that our method is complementary to prompting strategies and remains effective on larger models. Extensive experiments show that ContextFocus significantly improves contextual-faithfulness. Our results highlight the effectiveness, robustness, and efficiency of ContextFocus in improving contextual-faithfulness of LLM outputs.
Characterization and Mitigation of Training Instabilities in Microscaling Formats
Jun 25, 2025



Training large language models is an expensive, compute-bound process that must be repeated as models scale, algorithms improve, and new data is collected. To address this, next-generation hardware accelerators increasingly support lower-precision arithmetic formats, such as the Microscaling (MX) formats introduced in NVIDIA's Blackwell architecture. These formats use a shared scale within blocks of parameters to extend representable range and perform forward/backward GEMM operations in reduced precision for efficiency gains. In this work, we investigate the challenges and viability of block-scaled precision formats during model training. Across nearly one thousand language models trained from scratch -- spanning compute budgets from $2 \times 10^{17}$ to $4.8 \times 10^{19}$ FLOPs and sweeping over a broad range of weight-activation precision combinations -- we consistently observe that training in MX formats exhibits sharp, stochastic instabilities in the loss, particularly at larger compute scales. To explain this phenomenon, we conduct controlled experiments and ablations on a smaller proxy model that exhibits similar behavior as the language model, sweeping across architectural settings, hyperparameters, and precision formats. These experiments motivate a simple model in which multiplicative gradient bias introduced by the quantization of layer-norm affine parameters and a small fraction of activations can trigger runaway divergence. Through \emph{in situ} intervention experiments on our proxy model, we demonstrate that instabilities can be averted or delayed by modifying precision schemes mid-training. Guided by these findings, we evaluate stabilization strategies in the LLM setting and show that certain hybrid configurations recover performance competitive with full-precision training. We release our code at https://github.com/Hither1/systems-scaling.
Decomposing Elements of Problem Solving: What "Math" Does RL Teach?
May 28, 2025Mathematical reasoning tasks have become prominent benchmarks for assessing the reasoning capabilities of LLMs, especially with reinforcement learning (RL) methods such as GRPO showing significant performance gains. However, accuracy metrics alone do not support fine-grained assessment of capabilities and fail to reveal which problem-solving skills have been internalized. To better understand these capabilities, we propose to decompose problem solving into fundamental capabilities: Plan (mapping questions to sequences of steps), Execute (correctly performing solution steps), and Verify (identifying the correctness of a solution). Empirically, we find that GRPO mainly enhances the execution skill-improving execution robustness on problems the model already knows how to solve-a phenomenon we call temperature distillation. More importantly, we show that RL-trained models struggle with fundamentally new problems, hitting a 'coverage wall' due to insufficient planning skills. To explore RL's impact more deeply, we construct a minimal, synthetic solution-tree navigation task as an analogy for mathematical problem-solving. This controlled setup replicates our empirical findings, confirming RL primarily boosts execution robustness. Importantly, in this setting, we identify conditions under which RL can potentially overcome the coverage wall through improved exploration and generalization to new solution paths. Our findings provide insights into the role of RL in enhancing LLM reasoning, expose key limitations, and suggest a path toward overcoming these barriers. Code is available at https://github.com/cfpark00/RL-Wall.
Loss-to-Loss Prediction: Scaling Laws for All Datasets
Nov 19, 2024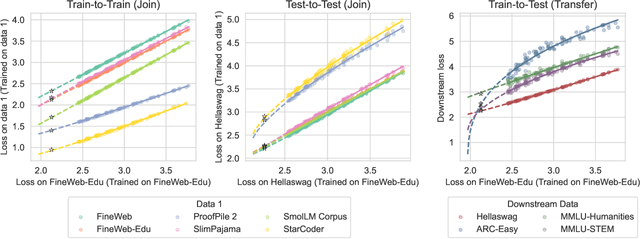
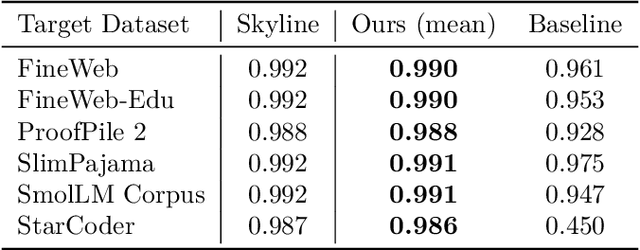
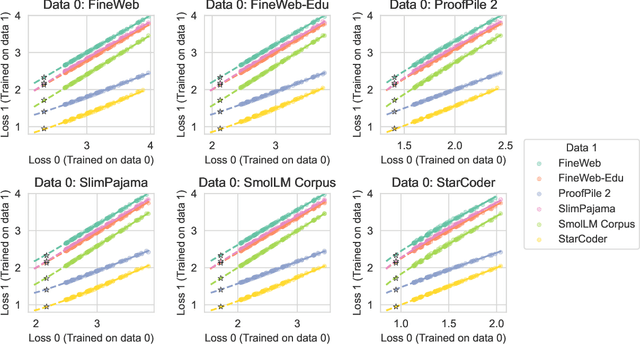

While scaling laws provide a reliable methodology for predicting train loss across compute scales for a single data distribution, less is known about how these predictions should change as we change the distribution. In this paper, we derive a strategy for predicting one loss from another and apply it to predict across different pre-training datasets and from pre-training data to downstream task data. Our predictions extrapolate well even at 20x the largest FLOP budget used to fit the curves. More precisely, we find that there are simple shifted power law relationships between (1) the train losses of two models trained on two separate datasets when the models are paired by training compute (train-to-train), (2) the train loss and the test loss on any downstream distribution for a single model (train-to-test), and (3) the test losses of two models trained on two separate train datasets (test-to-test). The results hold up for pre-training datasets that differ substantially (some are entirely code and others have no code at all) and across a variety of downstream tasks. Finally, we find that in some settings these shifted power law relationships can yield more accurate predictions than extrapolating single-dataset scaling laws.
Mixture of Parrots: Experts improve memorization more than reasoning
Oct 24, 2024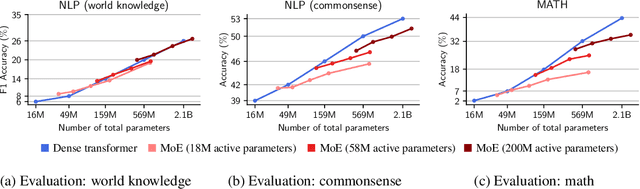
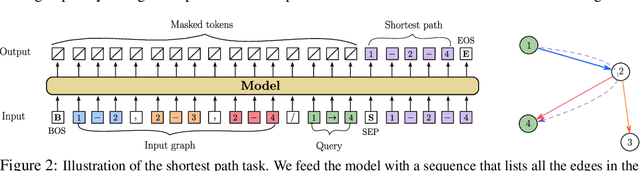
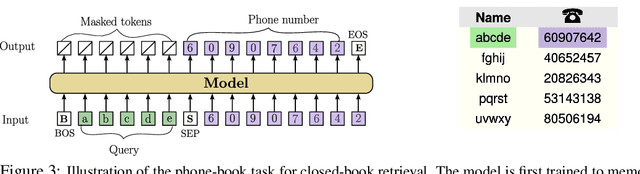
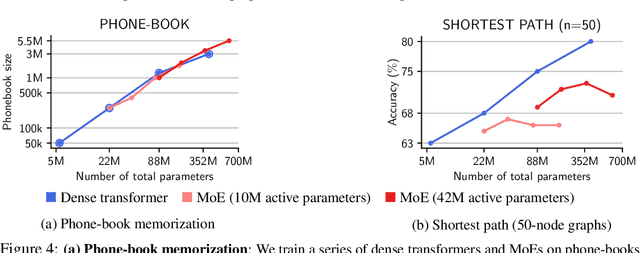
The Mixture-of-Experts (MoE) architecture enables a significant increase in the total number of model parameters with minimal computational overhead. However, it is not clear what performance tradeoffs, if any, exist between MoEs and standard dense transformers. In this paper, we show that as we increase the number of experts (while fixing the number of active parameters), the memorization performance consistently increases while the reasoning capabilities saturate. We begin by analyzing the theoretical limitations of MoEs at reasoning. We prove that there exist graph problems that cannot be solved by any number of experts of a certain width; however, the same task can be easily solved by a dense model with a slightly larger width. On the other hand, we find that on memory-intensive tasks, MoEs can effectively leverage a small number of active parameters with a large number of experts to memorize the data. We empirically validate these findings on synthetic graph problems and memory-intensive closed book retrieval tasks. Lastly, we pre-train a series of MoEs and dense transformers and evaluate them on commonly used benchmarks in math and natural language. We find that increasing the number of experts helps solve knowledge-intensive tasks, but fails to yield the same benefits for reasoning tasks.
Dataset Difficulty and the Role of Inductive Bias
Jan 03, 2024Motivated by the goals of dataset pruning and defect identification, a growing body of methods have been developed to score individual examples within a dataset. These methods, which we call "example difficulty scores", are typically used to rank or categorize examples, but the consistency of rankings between different training runs, scoring methods, and model architectures is generally unknown. To determine how example rankings vary due to these random and controlled effects, we systematically compare different formulations of scores over a range of runs and model architectures. We find that scores largely share the following traits: they are noisy over individual runs of a model, strongly correlated with a single notion of difficulty, and reveal examples that range from being highly sensitive to insensitive to the inductive biases of certain model architectures. Drawing from statistical genetics, we develop a simple method for fingerprinting model architectures using a few sensitive examples. These findings guide practitioners in maximizing the consistency of their scores (e.g. by choosing appropriate scoring methods, number of runs, and subsets of examples), and establishes comprehensive baselines for evaluating scores in the future.
Influence Scores at Scale for Efficient Language Data Sampling
Nov 27, 2023Modern ML systems ingest data aggregated from diverse sources, such as synthetic, human-annotated, and live customer traffic. Understanding \textit{which} examples are important to the performance of a learning algorithm is crucial for efficient model training. Recently, a growing body of literature has given rise to various "influence scores," which use training artifacts such as model confidence or checkpointed gradients to identify important subsets of data. However, these methods have primarily been developed in computer vision settings, and it remains unclear how well they generalize to language-based tasks using pretrained models. In this paper, we explore the applicability of influence scores in language classification tasks. We evaluate a diverse subset of these scores on the SNLI dataset by quantifying accuracy changes in response to pruning training data through random and influence-score-based sampling. We then stress-test one of the scores -- "variance of gradients" (VoG) from Agarwal et al. (2022) -- in an NLU model stack that was exposed to dynamic user speech patterns in a voice assistant type of setting. Our experiments demonstrate that in many cases, encoder-based language models can be finetuned on roughly 50% of the original data without degradation in performance metrics. Along the way, we summarize lessons learned from applying out-of-the-box implementations of influence scores, quantify the effects of noisy and class-imbalanced data, and offer recommendations on score-based sampling for better accuracy and training efficiency.
Comprehensive Benchmarking of Entropy and Margin Based Scoring Metrics for Data Selection
Nov 27, 2023



While data selection methods have been studied extensively in active learning, data pruning, and data augmentation settings, there is little evidence for the efficacy of these methods in industry scale settings, particularly in low-resource languages. Our work presents ways of assessing prospective training examples in those settings for their "usefulness" or "difficulty". We also demonstrate how these measures can be used in selecting important examples for training supervised machine learning models. We primarily experiment with entropy and Error L2-Norm (EL2N) scores. We use these metrics to curate high quality datasets from a large pool of \textit{Weak Signal Labeled} data, which assigns no-defect high confidence hypotheses during inference as ground truth labels. We then conduct training data augmentation experiments using these de-identified datasets and demonstrate that score-based selection can result in a 2% decrease in semantic error rate and 4%-7% decrease in domain classification error rate when compared to the baseline technique of random selection.