 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenAI for Systems: Recurring Challenges and Design Principles from Software to Silicon
Feb 16, 2026Generative AI is reshaping how computing systems are designed, optimized, and built, yet research remains fragmented across software, architecture, and chip design communities. This paper takes a cross-stack perspective, examining how generative models are being applied from code generation and distributed runtimes through hardware design space exploration to RTL synthesis, physical layout, and verification. Rather than reviewing each layer in isolation, we analyze how the same structural difficulties and effective responses recur across the stack. Our central finding is one of convergence. Despite the diversity of domains and tools, the field keeps encountering five recurring challenges (the feedback loop crisis, the tacit knowledge problem, trust and validation, co-design across boundaries, and the shift from determinism to dynamism) and keeps arriving at five design principles that independently emerge as effective responses (embracing hybrid approaches, designing for continuous feedback, separating concerns by role, matching methods to problem structure, and building on decades of systems knowledge). We organize these into a challenge--principle map that serves as a diagnostic and design aid, showing which principles have proven effective for which challenges across layers. Through concrete cross-stack examples, we show how systems navigate this map as they mature, and argue that the field needs shared engineering methodology, including common vocabularies, cross-layer benchmarks, and systematic design practices, so that progress compounds across communities rather than being rediscovered in each one. Our analysis covers more than 275 papers spanning eleven application areas across three layers of the computing stack, and distills open research questions that become visible only from a cross-layer vantage point.
Budgeted Multiple-Expert Deferral
Oct 30, 2025Learning to defer uncertain predictions to costly experts offers a powerful strategy for improving the accuracy and efficiency of machine learning systems. However, standard training procedures for deferral algorithms typically require querying all experts for every training instance, an approach that becomes prohibitively expensive when expert queries incur significant computational or resource costs. This undermines the core goal of deferral: to limit unnecessary expert usage. To overcome this challenge, we introduce the budgeted deferral framework, which aims to train effective deferral algorithms while minimizing expert query costs during training. We propose new algorithms for both two-stage and single-stage multiple-expert deferral settings that selectively query only a subset of experts per training example. While inspired by active learning, our setting is fundamentally different: labels are already known, and the core challenge is to decide which experts to query in order to balance cost and predictive performance. We establish theoretical guarantees for both of our algorithms, including generalization bounds and label complexity analyses. Empirical results across several domains show that our algorithms substantially reduce training costs without sacrificing prediction accuracy, demonstrating the practical value of our budget-aware deferral algorithms.
Mixture of Parrots: Experts improve memorization more than reasoning
Oct 24, 2024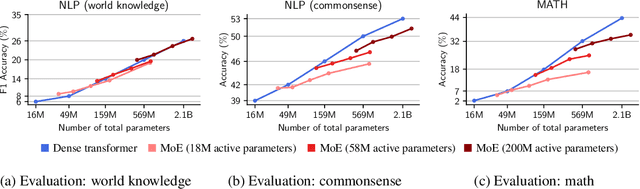
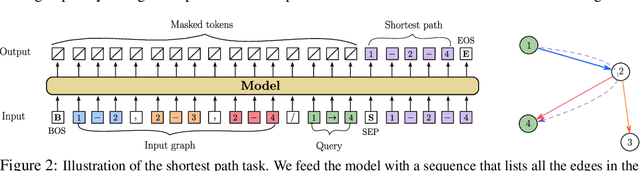
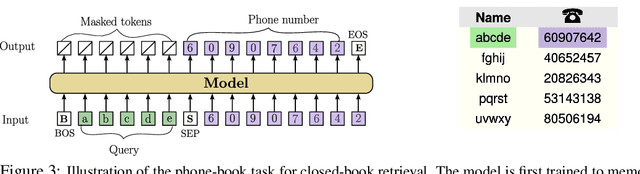
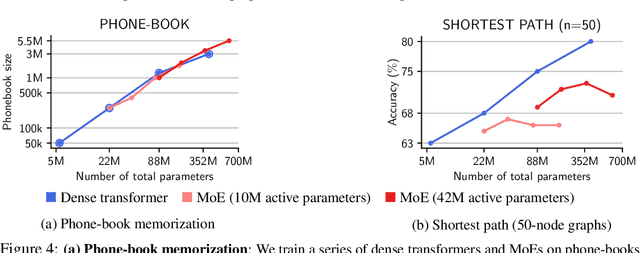
The Mixture-of-Experts (MoE) architecture enables a significant increase in the total number of model parameters with minimal computational overhead. However, it is not clear what performance tradeoffs, if any, exist between MoEs and standard dense transformers. In this paper, we show that as we increase the number of experts (while fixing the number of active parameters), the memorization performance consistently increases while the reasoning capabilities saturate. We begin by analyzing the theoretical limitations of MoEs at reasoning. We prove that there exist graph problems that cannot be solved by any number of experts of a certain width; however, the same task can be easily solved by a dense model with a slightly larger width. On the other hand, we find that on memory-intensive tasks, MoEs can effectively leverage a small number of active parameters with a large number of experts to memorize the data. We empirically validate these findings on synthetic graph problems and memory-intensive closed book retrieval tasks. Lastly, we pre-train a series of MoEs and dense transformers and evaluate them on commonly used benchmarks in math and natural language. We find that increasing the number of experts helps solve knowledge-intensive tasks, but fails to yield the same benefits for reasoning tasks.
Using Language to Extend to Unseen Domains
Oct 20, 2022
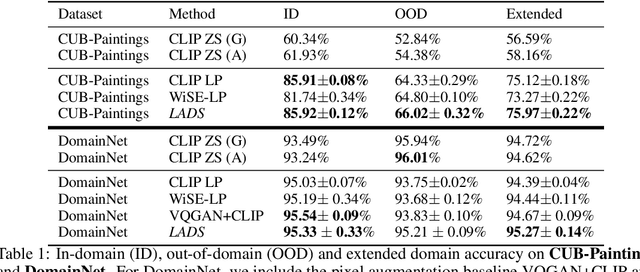
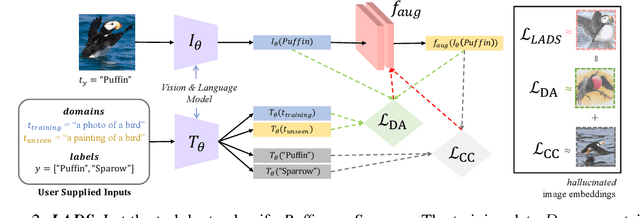

It is expensive to collect training data for every possible domain that a vision model may encounter when deployed. We instead consider how simply verbalizing the training domain (e.g. "photos of birds") as well as domains we want to extend to but do not have data for (e.g. "paintings of birds") can improve robustness. Using a multimodal model with a joint image and language embedding space, our method LADS learns a transformation of the image embeddings from the training domain to each unseen test domain, while preserving task relevant information. Without using any images from the unseen test domain, we show that over the extended domain containing both training and unseen test domains, LADS outperforms standard fine-tuning and ensemble approaches over a suite of four benchmarks targeting domain adaptation and dataset bias