 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMASRA: MLLM-Assisted Semantic-Relational Consistent Alignment for Video Temporal Grounding
May 05, 2026Video Temporal Grounding (VTG) faces a cross-modal semantic gap that often leads to background features being incorrectly aligned with the query, while directly matching the query to moments results in insufficient discriminability and consistency of temporal semantics. To address this issue, we propose MLLM-Assisted Semantic-Relational Consistent Alignment (MASRA), a training-time MLLM-based optimization framework for VTG. MASRA leverages an MLLM during training to produce two forms of textual priors, namely event-level descriptions with temporal spans and clip-level captions, and instantiates two MLLM-assisted alignments. Event Semantic Temporal Alignment (ESTA) aligns temporal context with event semantics to explicitly strengthen the correspondence between semantics and temporal events and improve span-level separability. Local Relational Consistency Alignment (LRCA) constructs a textual relation matrix derived from clip-level captions and aligns it with the temporal feature similarity matrix in the model, enhancing temporal consistency while capturing local structural information. MASRA includes two simple supporting modules, semantic-guided enhancement and second-order relational attention, to better utilize the learned semantic context and relational structure. Moreover, we introduce Decoupled Alignment Interaction (DAI) with a context-aware codebook to adaptively absorb query-irrelevant semantics and alleviate the cross-modal gap. The MLLM is only invoked during training and is not used at inference. Extensive experiments show that MASRA outperforms existing methods, and ablation studies validate its effectiveness.
Enhancing Self-Supervised Talking Head Forgery Detection via a Training-Free Dual-System Framework
May 05, 2026Supervised talking head forgery detection faces severe generalization challenges due to the continuous evolution of generators. By reducing reliance on generator-specific forgery patterns, self-supervised detectors offer stronger cross-generator robustness. However, existing research has mainly focused on building stronger detectors, while the discriminative capacity of trained detectors remains insufficiently exploited. In particular, for score-based self-supervised detectors, the limited discriminative ability on hard cases is often reflected in unreliable anomaly ordering, leaving room for further refinement. Motivated by this observation, we draw inspiration from the dual-system theory of human cognition and propose a Training-Free Dual-System (TFDS) framework to further exploit the latent discriminative capacity of existing score-based self-supervised detectors. TFDS treats anomaly-like scores as the basis of System-1, using lightweight threshold-based routing to partition samples into confident and uncertain subsets. System-2 then revisits only the uncertain subset, performing fine-grained evidence-guided reasoning to refine the relative ordering of ambiguous samples within the original score distribution. Extensive experiments demonstrate consistent improvements across datasets and perturbation settings, with the gains arising mainly from corrected ordering within the uncertain subset. These findings show that existing self-supervised talking head forgery detectors still contain underexploited discriminative cues that can be effectively unlocked through training-free dual-system reasoning.
From Static to Adaptive Defense: Federated Multi-Agent Deep Reinforcement Learning-Driven Moving Target Defense Against DoS Attacks in UAV Swarm Networks
Jun 09, 2025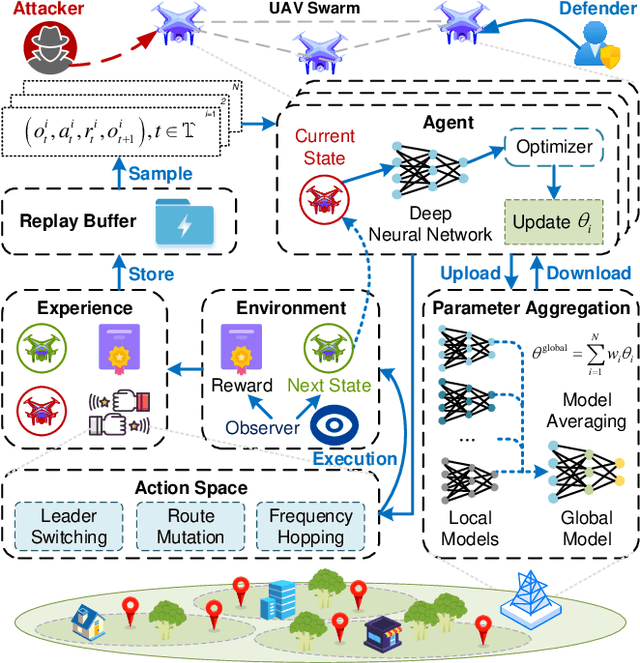
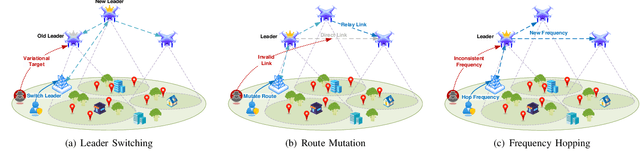
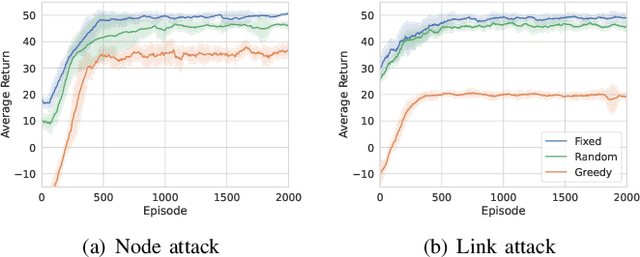
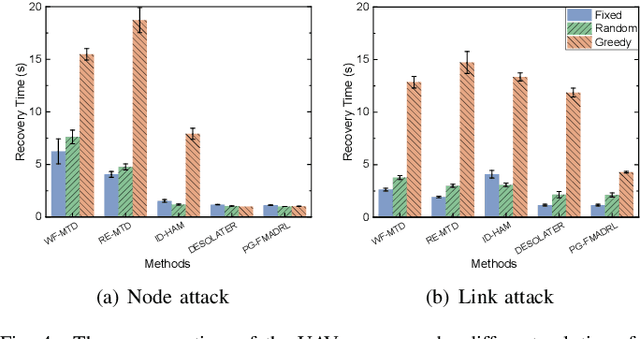
The proliferation of unmanned aerial vehicle (UAV) swarms has enabled a wide range of mission-critical applications, but also exposes UAV networks to severe Denial-of-Service (DoS) threats due to their open wireless environment, dynamic topology, and resource constraints. Traditional static or centralized defense mechanisms are often inadequate for such dynamic and distributed scenarios. To address these challenges, we propose a novel federated multi-agent deep reinforcement learning (FMADRL)-driven moving target defense (MTD) framework for proactive and adaptive DoS mitigation in UAV swarm networks. Specifically, we design three lightweight and coordinated MTD mechanisms, including leader switching, route mutation, and frequency hopping, that leverage the inherent flexibility of UAV swarms to disrupt attacker efforts and enhance network resilience. The defense problem is formulated as a multi-agent partially observable Markov decision process (POMDP), capturing the distributed, resource-constrained, and uncertain nature of UAV swarms under attack. Each UAV is equipped with a local policy agent that autonomously selects MTD actions based on partial observations and local experiences. By employing a policy gradient-based FMADRL algorithm, UAVs collaboratively optimize their defense policies via reward-weighted aggregation, enabling distributed learning without sharing raw data and thus reducing communication overhead. Extensive simulations demonstrate that our approach significantly outperforms state-of-the-art baselines, achieving up to a 34.6% improvement in attack mitigation rate, a reduction in average recovery time of up to 94.6%, and decreases in energy consumption and defense cost by as much as 29.3% and 98.3%, respectively, while maintaining robust mission continuity under various DoS attack strategies.
An Efficient Pre-Processing Method for 6G Dynamic Ray-Tracing Channel Modeling
Jan 06, 2025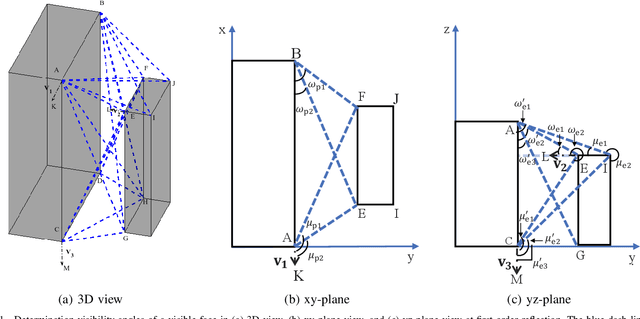
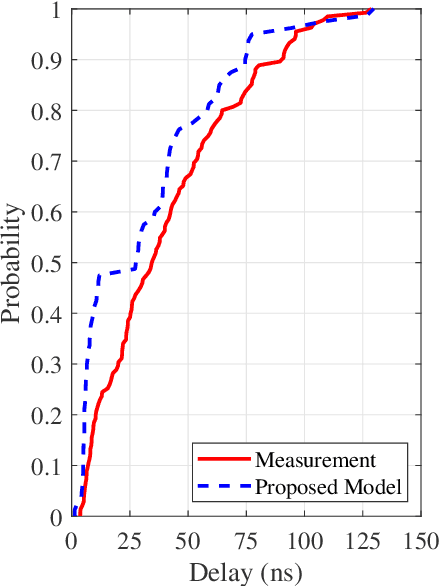
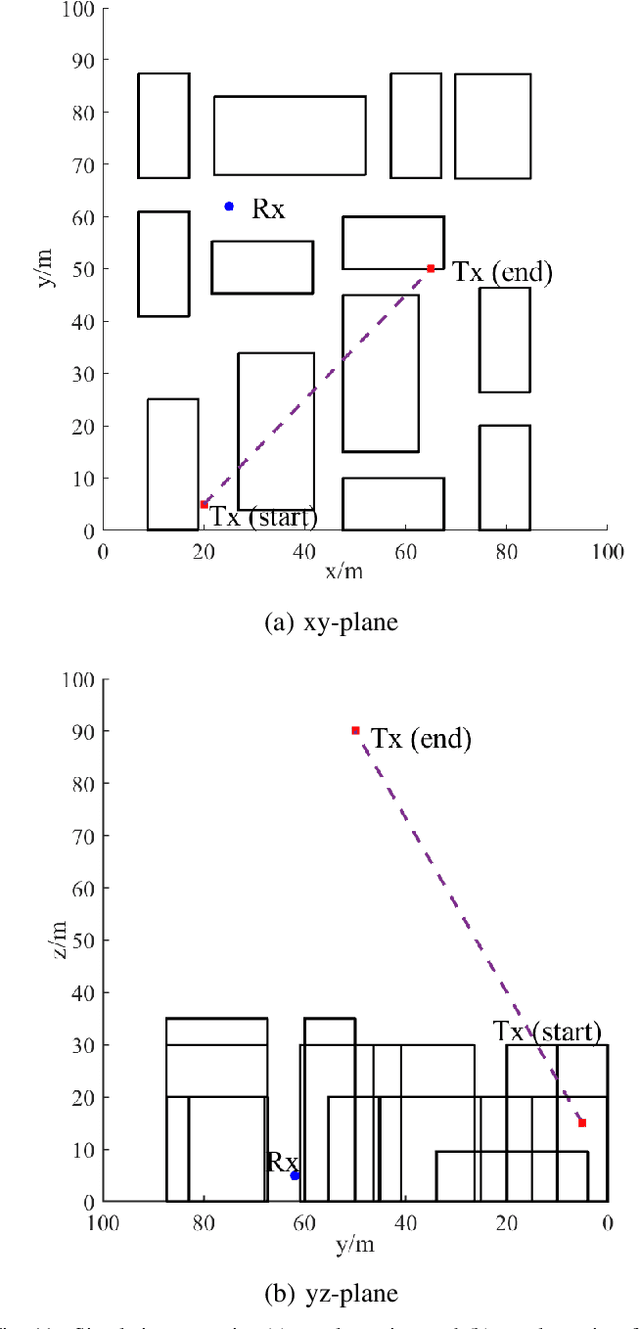
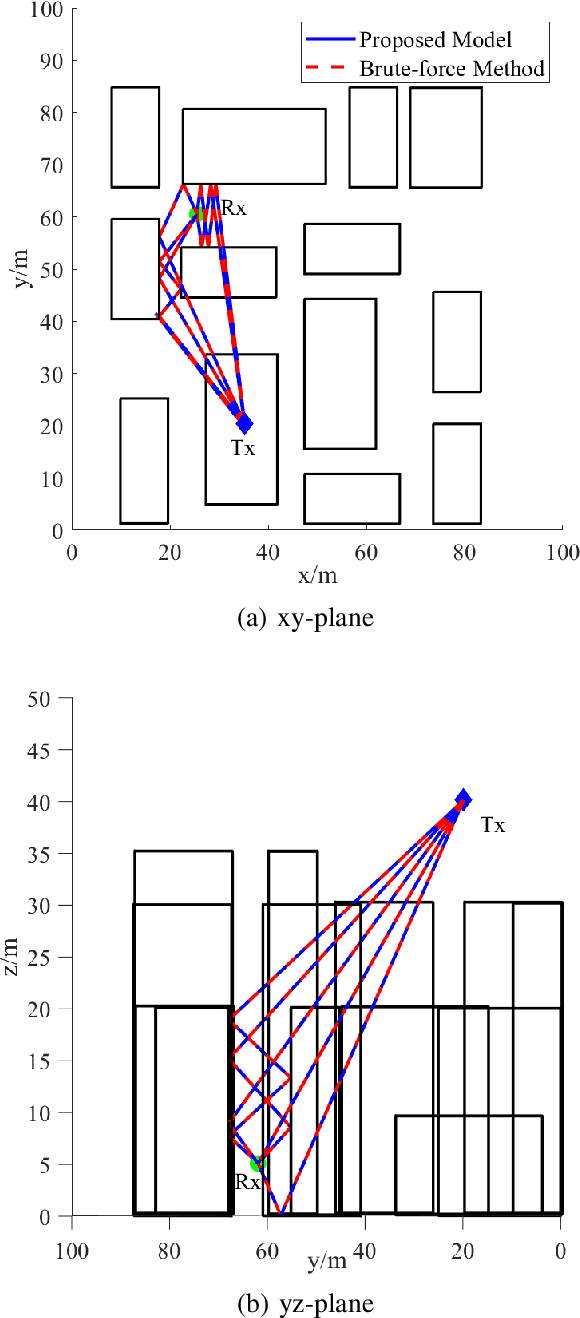
The ray-tracing is often employed in urban areas for channel modeling with high accuracy but encounters a substantial computational complexity for high mobility scenarios. In this paper, we propose a novel pre-processing method for dynamic ray-tracing to reduce the computational burden in high-mobility scenarios by prepending the intersection judgment to the pre-processing stage. The proposed method generates an inter-visibility matrix that establishes visibility relationships among static objects in the environment considering the intersection judgment. Moreover, the inter-visibility matrix can be employed to create the inter-visibility table for mobile transmitters and receivers, which can improve the efficiency of constructing an image tree for the three-dimensional (3D) dynamic ray-tracing method. The results show that the proposed pre-processing method in dynamic ray-tracing has considerable time-saving compared with the traditional method while maintaining the same accuracy. The channel characteristics computed by the proposed method can well match to the channel measurements.
Toward Intelligent and Secure Cloud: Large Language Model Empowered Proactive Defense
Dec 30, 2024The rapid evolution of cloud computing technologies and the increasing number of cloud applications have provided a large number of benefits in daily lives. However, the diversity and complexity of different components pose a significant challenge to cloud security, especially when dealing with sophisticated and advanced cyberattacks. Recent advancements in generative foundation models (GFMs), particularly in the large language models (LLMs), offer promising solutions for security intelligence. By exploiting the powerful abilities in language understanding, data analysis, task inference, action planning, and code generation, we present LLM-PD, a novel proactive defense architecture that defeats various threats in a proactive manner. LLM-PD can efficiently make a decision through comprehensive data analysis and sequential reasoning, as well as dynamically creating and deploying actionable defense mechanisms on the target cloud. Furthermore, it can flexibly self-evolve based on experience learned from previous interactions and adapt to new attack scenarios without additional training. The experimental results demonstrate its remarkable ability in terms of defense effectiveness and efficiency, particularly highlighting an outstanding success rate when compared with other existing methods.
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
DiffLoRA: Generating Personalized Low-Rank Adaptation Weights with Diffusion
Aug 13, 2024

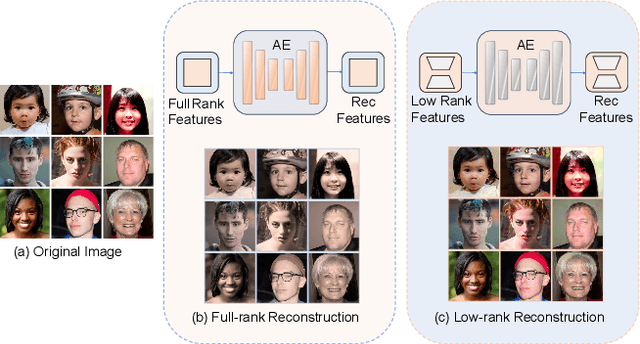
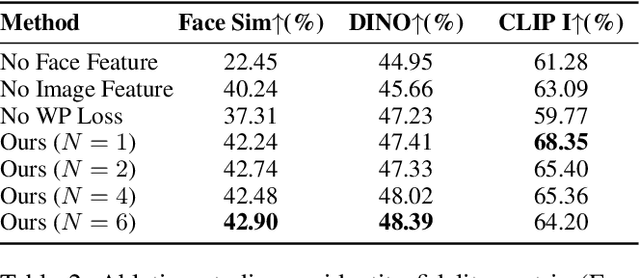
Personalized text-to-image generation has gained significant attention for its capability to generate high-fidelity portraits of specific identities conditioned on user-defined prompts. Existing methods typically involve test-time fine-tuning or instead incorporating an additional pre-trained branch. However, these approaches struggle to simultaneously address the demands of efficiency, identity fidelity, and preserving the model's original generative capabilities. In this paper, we propose DiffLoRA, a novel approach that leverages diffusion models as a hypernetwork to predict personalized low-rank adaptation (LoRA) weights based on the reference images. By integrating these LoRA weights into the text-to-image model, DiffLoRA achieves personalization during inference without further training. Additionally, we propose an identity-oriented LoRA weight construction pipeline to facilitate the training of DiffLoRA. By utilizing the dataset produced by this pipeline, our DiffLoRA consistently generates high-performance and accurate LoRA weights. Extensive evaluations demonstrate the effectiveness of our method, achieving both time efficiency and maintaining identity fidelity throughout the personalization process.
MalPurifier: Enhancing Android Malware Detection with Adversarial Purification against Evasion Attacks
Dec 11, 2023Machine learning (ML) has gained significant adoption in Android malware detection to address the escalating threats posed by the rapid proliferation of malware attacks. However, recent studies have revealed the inherent vulnerabilities of ML-based detection systems to evasion attacks. While efforts have been made to address this critical issue, many of the existing defensive methods encounter challenges such as lower effectiveness or reduced generalization capabilities. In this paper, we introduce a novel Android malware detection method, MalPurifier, which exploits adversarial purification to eliminate perturbations independently, resulting in attack mitigation in a light and flexible way. Specifically, MalPurifier employs a Denoising AutoEncoder (DAE)-based purification model to preprocess input samples, removing potential perturbations from them and then leading to correct classification. To enhance defense effectiveness, we propose a diversified adversarial perturbation mechanism that strengthens the purification model against different manipulations from various evasion attacks. We also incorporate randomized "protective noises" onto benign samples to prevent excessive purification. Furthermore, we customize a loss function for improving the DAE model, combining reconstruction loss and prediction loss, to enhance feature representation learning, resulting in accurate reconstruction and classification. Experimental results on two Android malware datasets demonstrate that MalPurifier outperforms the state-of-the-art defenses, and it significantly strengthens the vulnerable malware detector against 37 evasion attacks, achieving accuracies over 90.91%. Notably, MalPurifier demonstrates easy scalability to other detectors, offering flexibility and robustness in its implementation.
MoConVQ: Unified Physics-Based Motion Control via Scalable Discrete Representations
Oct 17, 2023In this work, we present MoConVQ, a novel unified framework for physics-based motion control leveraging scalable discrete representations. Building upon vector quantized variational autoencoders (VQ-VAE) and model-based reinforcement learning, our approach effectively learns motion embeddings from a large, unstructured dataset spanning tens of hours of motion examples. The resultant motion representation not only captures diverse motion skills but also offers a robust and intuitive interface for various applications. We demonstrate the versatility of MoConVQ through several applications: universal tracking control from various motion sources, interactive character control with latent motion representations using supervised learning, physics-based motion generation from natural language descriptions using the GPT framework, and, most interestingly, seamless integration with large language models (LLMs) with in-context learning to tackle complex and abstract tasks.
An Improved Equiangular Division Algorithm for SBR based Ray Tracing Channel Modeling
Aug 22, 2022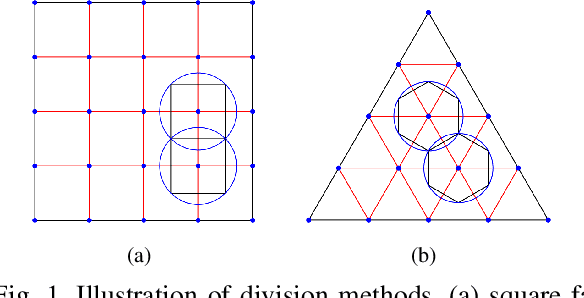
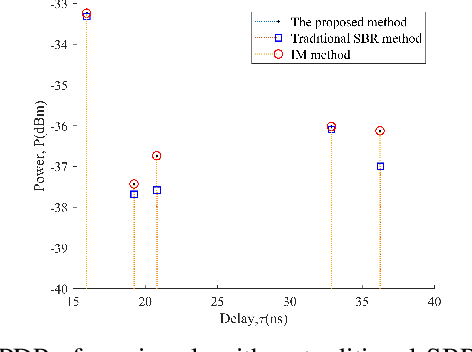
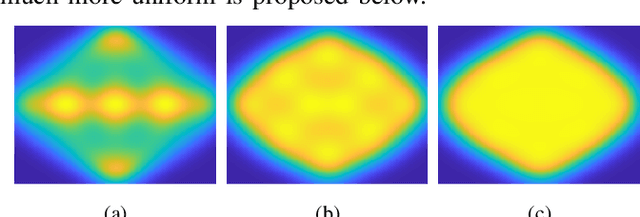
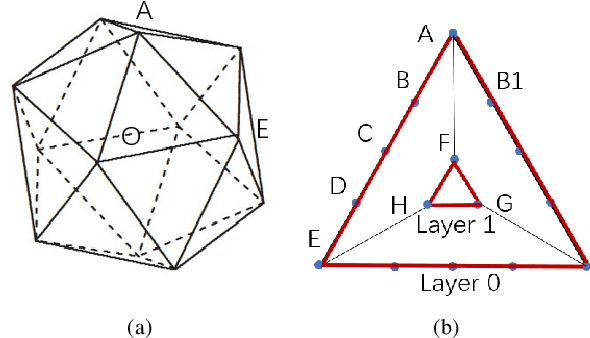
Compared with image method (IM) based ray tracing (RT), shooting and bouncing ray (SBR) method is characterized by fast speed but low accuracy. In this paper, an iterative precise algorithm based on equiangular division is proposed to make rough paths accurate, allowing SBR to calculate exact channel information. Different ray launching methods are compared to obtain a better launching method. By using equiangular division, rays are launched more uniformly from transmitter (Tx) compared with the current equidistant division method. With the proposed iterative precise algorithm, error of angle of departure (AOD) and angle of arrival (AOA) is below 0.01 degree. The relationship between the number of iterations and error reduction is also given. It is illustrated that the proposed method has the same accuracy as IM by comparing the power delay profile (PDP) and angle distribution of paths. This can solve the problem of low accuracy brougth by SBR.