 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Metric-Aware Multi-Person Mesh Recovery by Jointly Optimizing Human Crowd in Camera Space
Nov 17, 2025Multi-person human mesh recovery from a single image is a challenging task, hindered by the scarcity of in-the-wild training data. Prevailing in-the-wild human mesh pseudo-ground-truth (pGT) generation pipelines are single-person-centric, where each human is processed individually without joint optimization. This oversight leads to a lack of scene-level consistency, producing individuals with conflicting depths and scales within the same image. To address this, we introduce Depth-conditioned Translation Optimization (DTO), a novel optimization-based method that jointly refines the camera-space translations of all individuals in a crowd. By leveraging anthropometric priors on human height and depth cues from a monocular depth estimator, DTO solves for a scene-consistent placement of all subjects within a principled Maximum a posteriori (MAP) framework. Applying DTO to the 4D-Humans dataset, we construct DTO-Humans, a new large-scale pGT dataset of 0.56M high-quality, scene-consistent multi-person images, featuring dense crowds with an average of 4.8 persons per image. Furthermore, we propose Metric-Aware HMR, an end-to-end network that directly estimates human mesh and camera parameters in metric scale. This is enabled by a camera branch and a novel relative metric loss that enforces plausible relative scales. Extensive experiments demonstrate that our method achieves state-of-the-art performance on relative depth reasoning and human mesh recovery. Code and data will be released publicly.
GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
Jul 02, 2025



We present GLM-4.1V-Thinking, a vision-language model (VLM) designed to advance general-purpose multimodal understanding and reasoning. In this report, we share our key findings in the development of the reasoning-centric training framework. We first develop a capable vision foundation model with significant potential through large-scale pre-training, which arguably sets the upper bound for the final performance. We then propose Reinforcement Learning with Curriculum Sampling (RLCS) to unlock the full potential of the model, leading to comprehensive capability enhancement across a diverse range of tasks, including STEM problem solving, video understanding, content recognition, coding, grounding, GUI-based agents, and long document understanding. We open-source GLM-4.1V-9B-Thinking, which achieves state-of-the-art performance among models of comparable size. In a comprehensive evaluation across 28 public benchmarks, our model outperforms Qwen2.5-VL-7B on nearly all tasks and achieves comparable or even superior performance on 18 benchmarks relative to the significantly larger Qwen2.5-VL-72B. Notably, GLM-4.1V-9B-Thinking also demonstrates competitive or superior performance compared to closed-source models such as GPT-4o on challenging tasks including long document understanding and STEM reasoning, further underscoring its strong capabilities. Code, models and more information are released at https://github.com/THUDM/GLM-4.1V-Thinking.
Enhancing Multi-task Learning Capability of Medical Generalist Foundation Model via Image-centric Multi-annotation Data
Apr 14, 2025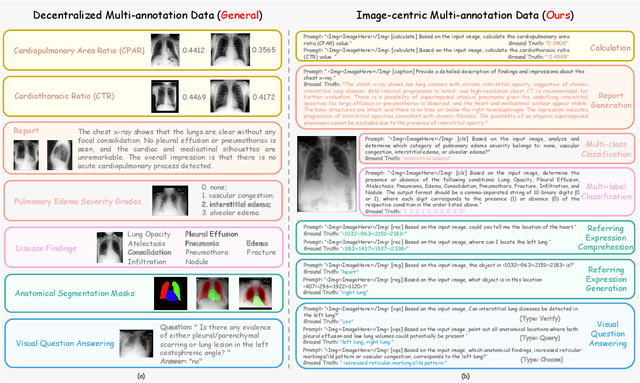
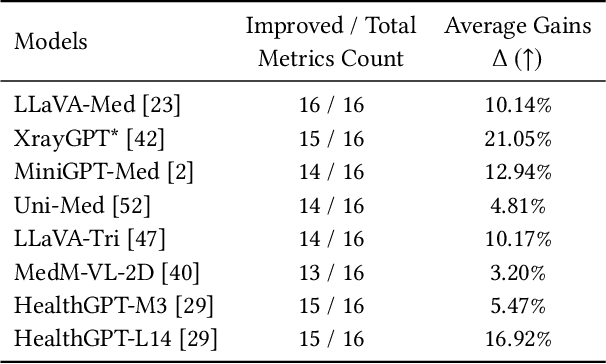
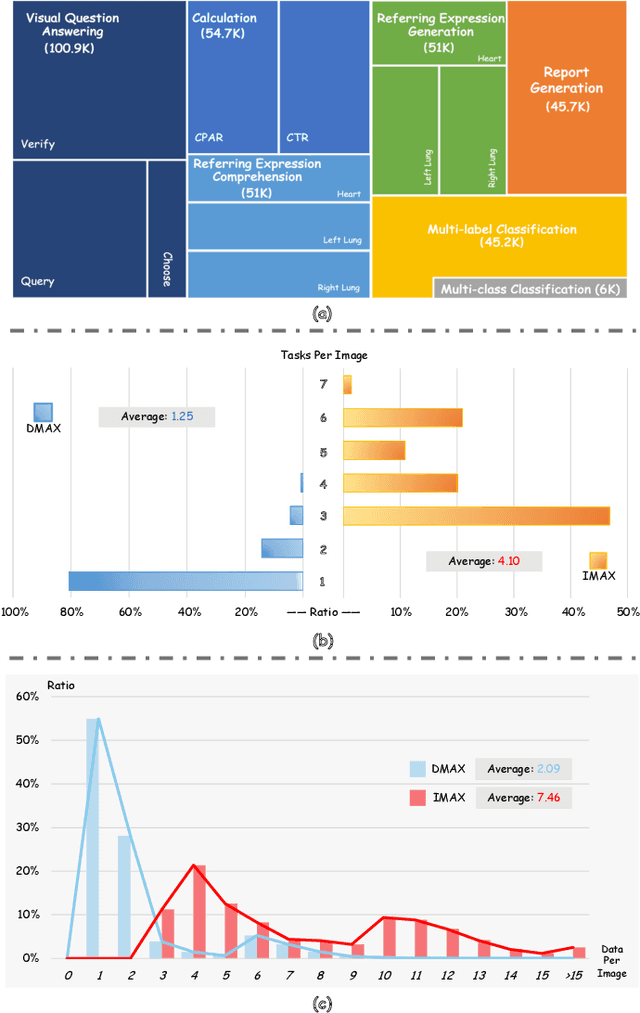

The emergence of medical generalist foundation models has revolutionized conventional task-specific model development paradigms, aiming to better handle multiple tasks through joint training on large-scale medical datasets. However, recent advances prioritize simple data scaling or architectural component enhancement, while neglecting to re-examine multi-task learning from a data-centric perspective. Critically, simply aggregating existing data resources leads to decentralized image-task alignment, which fails to cultivate comprehensive image understanding or align with clinical needs for multi-dimensional image interpretation. In this paper, we introduce the image-centric multi-annotation X-ray dataset (IMAX), the first attempt to enhance the multi-task learning capabilities of medical multi-modal large language models (MLLMs) from the data construction level. To be specific, IMAX is featured from the following attributes: 1) High-quality data curation. A comprehensive collection of more than 354K entries applicable to seven different medical tasks. 2) Image-centric dense annotation. Each X-ray image is associated with an average of 4.10 tasks and 7.46 training entries, ensuring multi-task representation richness per image. Compared to the general decentralized multi-annotation X-ray dataset (DMAX), IMAX consistently demonstrates significant multi-task average performance gains ranging from 3.20% to 21.05% across seven open-source state-of-the-art medical MLLMs. Moreover, we investigate differences in statistical patterns exhibited by IMAX and DMAX training processes, exploring potential correlations between optimization dynamics and multi-task performance. Finally, leveraging the core concept of IMAX data construction, we propose an optimized DMAX-based training strategy to alleviate the dilemma of obtaining high-quality IMAX data in practical scenarios.
MedM-VL: What Makes a Good Medical LVLM?
Apr 06, 2025Medical image analysis is a fundamental component. As deep learning progresses, the focus has shifted from single-task applications, such as classification and segmentation, to more complex multimodal tasks, including medical visual question answering and report generation. Traditional shallow and task-specific models are increasingly limited in addressing the complexity and scalability required in clinical practice. The emergence of large language models (LLMs) has driven the development of medical Large Vision-Language Models (LVLMs), offering a unified solution for diverse vision-language tasks. In this study, we investigate various architectural designs for medical LVLMs based on the widely adopted LLaVA framework, which follows an encoder-connector-LLM paradigm. We construct two distinct models targeting 2D and 3D modalities, respectively. These models are designed to support both general-purpose medical tasks and domain-specific fine-tuning, thereby serving as effective foundation models. To facilitate reproducibility and further research, we develop a modular and extensible codebase, MedM-VL, and release two LVLM variants: MedM-VL-2D for 2D medical image analysis and MedM-VL-CT-Chest for 3D CT-based applications. The code and models are available at: https://github.com/MSIIP/MedM-VL
Connector-S: A Survey of Connectors in Multi-modal Large Language Models
Feb 17, 2025



With the rapid advancements in multi-modal large language models (MLLMs), connectors play a pivotal role in bridging diverse modalities and enhancing model performance. However, the design and evolution of connectors have not been comprehensively analyzed, leaving gaps in understanding how these components function and hindering the development of more powerful connectors. In this survey, we systematically review the current progress of connectors in MLLMs and present a structured taxonomy that categorizes connectors into atomic operations (mapping, compression, mixture of experts) and holistic designs (multi-layer, multi-encoder, multi-modal scenarios), highlighting their technical contributions and advancements. Furthermore, we discuss several promising research frontiers and challenges, including high-resolution input, dynamic compression, guide information selection, combination strategy, and interpretability. This survey is intended to serve as a foundational reference and a clear roadmap for researchers, providing valuable insights into the design and optimization of next-generation connectors to enhance the performance and adaptability of MLLMs.
Med-2E3: A 2D-Enhanced 3D Medical Multimodal Large Language Model
Nov 19, 2024



The analysis of 3D medical images is crucial for modern healthcare, yet traditional task-specific models are becoming increasingly inadequate due to limited generalizability across diverse clinical scenarios. Multimodal large language models (MLLMs) offer a promising solution to these challenges. However, existing MLLMs have limitations in fully leveraging the rich, hierarchical information embedded in 3D medical images. Inspired by clinical practice, where radiologists focus on both 3D spatial structure and 2D planar content, we propose Med-2E3, a novel MLLM for 3D medical image analysis that integrates 3D and 2D encoders. To aggregate 2D features more effectively, we design a Text-Guided Inter-Slice (TG-IS) scoring module, which scores the attention of each 2D slice based on slice contents and task instructions. To the best of our knowledge, Med-2E3 is the first MLLM to integrate both 3D and 2D features for 3D medical image analysis. Experiments on a large-scale, open-source 3D medical multimodal benchmark demonstrate that Med-2E3 exhibits task-specific attention distribution and significantly outperforms current state-of-the-art models, with a 14% improvement in report generation and a 5% gain in medical visual question answering (VQA), highlighting the model's potential in addressing complex multimodal clinical tasks. The code will be released upon acceptance.
LoLDU: Low-Rank Adaptation via Lower-Diag-Upper Decomposition for Parameter-Efficient Fine-Tuning
Oct 17, 2024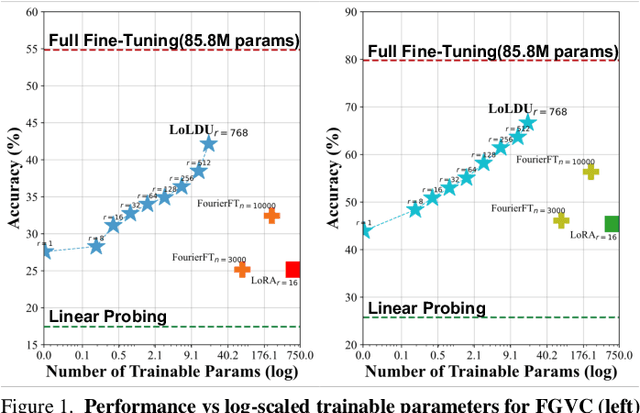
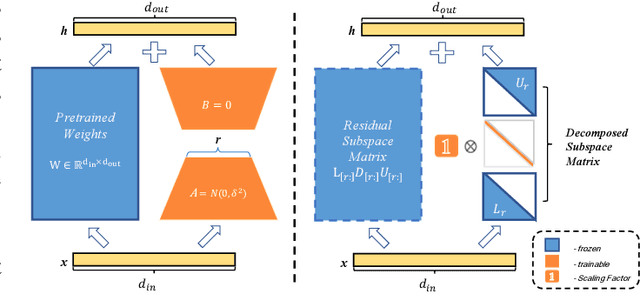
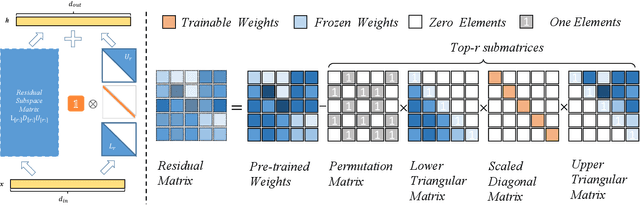
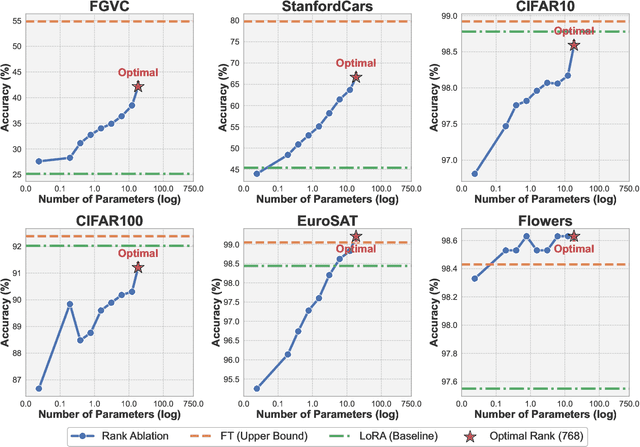
The rapid growth of model scale has necessitated substantial computational resources for fine-tuning. Existing approach such as Low-Rank Adaptation (LoRA) has sought to address the problem of handling the large updated parameters in full fine-tuning. However, LoRA utilize random initialization and optimization of low-rank matrices to approximate updated weights, which can result in suboptimal convergence and an accuracy gap compared to full fine-tuning. To address these issues, we propose LoLDU, a Parameter-Efficient Fine-Tuning (PEFT) approach that significantly reduces trainable parameters by 2600 times compared to regular PEFT methods while maintaining comparable performance. LoLDU leverages Lower-Diag-Upper Decomposition (LDU) to initialize low-rank matrices for faster convergence and orthogonality. We focus on optimizing the diagonal matrix for scaling transformations. To the best of our knowledge, LoLDU has the fewest parameters among all PEFT approaches. We conducted extensive experiments across 4 instruction-following datasets, 6 natural language understanding (NLU) datasets, 8 image classification datasets, and image generation datasets with multiple model types (LLaMA2, RoBERTa, ViT, and Stable Diffusion), providing a comprehensive and detailed analysis. Our open-source code can be accessed at \href{https://github.com/SKDDJ/LoLDU}{https://github.com/SKDDJ/LoLDU}.
Machine Translation Evaluation Benchmark for Wu Chinese: Workflow and Analysis
Oct 14, 2024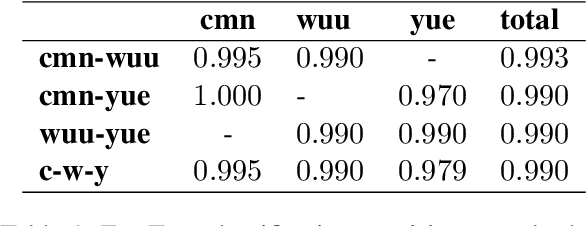
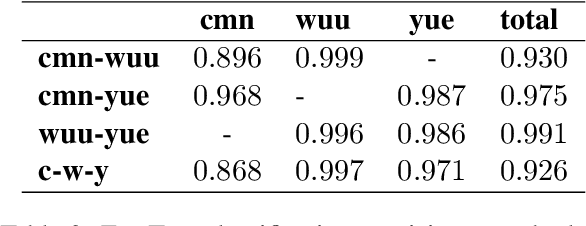
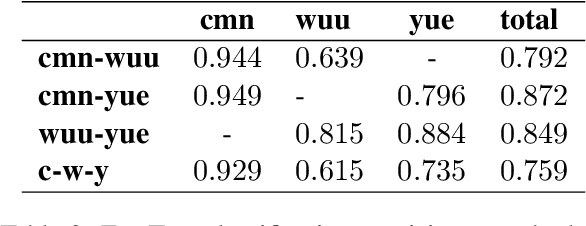
We introduce a FLORES+ dataset as an evaluation benchmark for modern Wu Chinese machine translation models and showcase its compatibility with existing Wu data. Wu Chinese is mutually unintelligible with other Sinitic languages such as Mandarin and Yue (Cantonese), but uses a set of Hanzi (Chinese characters) that profoundly overlaps with others. The population of Wu speakers is the second largest among languages in China, but the language has been suffering from significant drop in usage especially among the younger generations. We identify Wu Chinese as a textually low-resource language and address challenges for its machine translation models. Our contributions include: (1) an open-source, manually translated dataset, (2) full documentations on the process of dataset creation and validation experiments, (3) preliminary tools for Wu Chinese normalization and segmentation, and (4) benefits and limitations of our dataset, as well as implications to other low-resource languages.
SVFit: Parameter-Efficient Fine-Tuning of Large Pre-Trained Models Using Singular Values
Sep 09, 2024

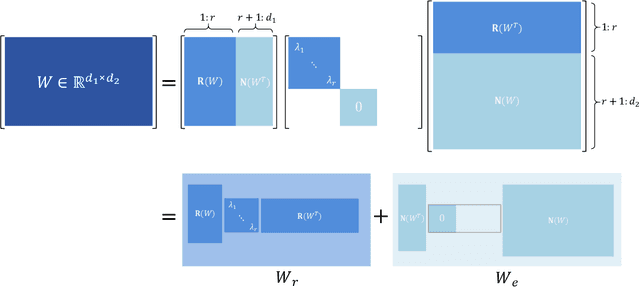

Large pre-trained models (LPMs) have demonstrated exceptional performance in diverse natural language processing and computer vision tasks. However, fully fine-tuning these models poses substantial memory challenges, particularly in resource-constrained environments. Parameter-efficient fine-tuning (PEFT) methods, such as LoRA, mitigate this issue by adjusting only a small subset of parameters. Nevertheless, these methods typically employ random initialization for low-rank matrices, which can lead to inefficiencies in gradient descent and diminished generalizability due to suboptimal starting points. To address these limitations, we propose SVFit, a novel PEFT approach that leverages singular value decomposition (SVD) to initialize low-rank matrices using critical singular values as trainable parameters. Specifically, SVFit performs SVD on the pre-trained weight matrix to obtain the best rank-r approximation matrix, emphasizing the most critical singular values that capture over 99% of the matrix's information. These top-r singular values are then used as trainable parameters to scale the fundamental subspaces of the matrix, facilitating rapid domain adaptation. Extensive experiments across various pre-trained models in natural language understanding, text-to-image generation, and image classification tasks reveal that SVFit outperforms LoRA while requiring 16 times fewer trainable parameters.
Rhyme-aware Chinese lyric generator based on GPT
Aug 19, 2024Neural language representation models such as GPT, pre-trained on large-scale corpora, can effectively capture rich semantic patterns from plain text and be fine-tuned to consistently improve natural language generation performance. However, existing pre-trained language models used to generate lyrics rarely consider rhyme information, which is crucial in lyrics. Using a pre-trained model directly results in poor performance. To enhance the rhyming quality of generated lyrics, we incorporate integrated rhyme information into our model, thereby improving lyric generation performance.