 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelaxing Anchor-Frame Dominance for Mitigating Hallucinations in Video Large Language Models
Apr 14, 2026Recent Video Large Language Models (Video-LLMs) have demonstrated strong capability in video understanding, yet they still suffer from hallucinations. Existing mitigation methods typically rely on training, input modification, auxiliary guidance, or additional decoding procedures, while largely overlooking a more fundamental challenge. During generation, Video-LLMs tend to over-rely on a limited portion of temporal evidence, leading to temporally imbalanced evidence aggregation across the video. To address this issue, we investigate a decoder-side phenomenon in which the model exhibits a temporally imbalanced concentration pattern. We term the frame with the highest aggregated frame-level attention mass the anchor frame. We find that this bias is largely independent of the input video and instead appears to reflect a persistent, model-specific structural or positional bias, whose over-dominance is closely associated with hallucination-prone generation. Motivated by this insight, we propose Decoder-side Temporal Rebalancing (DTR), a training-free, layer-selective inference method that rebalances temporal evidence allocation in middle-to-late decoder layers without altering visual encoding or requiring auxiliary models. DTR adaptively calibrates decoder-side visual attention to alleviate temporally imbalanced concentration and encourage under-attended frames to contribute more effectively to response generation. In this way, DTR guides the decoder to ground its outputs in temporally broader and more balanced video evidence. Extensive experiments on hallucination and video understanding benchmarks show that DTR consistently improves hallucination robustness across diverse Video-LLM families, while preserving competitive video understanding performance and high inference efficiency.
Lightweight LLM Agent Memory with Small Language Models
Apr 09, 2026Although LLM agents can leverage tools for complex tasks, they still need memory to maintain cross-turn consistency and accumulate reusable information in long-horizon interactions. However, retrieval-based external memory systems incur low online overhead but suffer from unstable accuracy due to limited query construction and candidate filtering. In contrast, many systems use repeated large-model calls for online memory operations, improving accuracy but accumulating latency over long interactions. We propose LightMem, a lightweight memory system for better agent memory driven by Small Language Models (SLMs). LightMem modularizes memory retrieval, writing, and long-term consolidation, and separates online processing from offline consolidation to enable efficient memory invocation under bounded compute. We organize memory into short-term memory (STM) for immediate conversational context, mid-term memory (MTM) for reusable interaction summaries, and long-term memory (LTM) for consolidated knowledge, and uses user identifiers to support independent retrieval and incremental maintenance in multi-user settings. Online, LightMem operates under a fixed retrieval budget and selects memories via a two-stage procedure: vector-based coarse retrieval followed by semantic consistency re-ranking. Offline, it abstracts reusable interaction evidence and incrementally integrates it into LTM. Experiments show gains across model scales, with an average F1 improvement of about 2.5 on LoCoMo, more effective and low median latency (83 ms retrieval; 581 ms end-to-end).
ALTER: Asymmetric LoRA for Token-Entropy-Guided Unlearning of LLMs
Mar 02, 2026Large language models (LLMs) have advanced to encompass extensive knowledge across diverse domains. Yet controlling what a LLMs should not know is important for ensuring alignment and thus safe use. However, effective unlearning in LLMs is difficult due to the fuzzy boundary between knowledge retention and forgetting. This challenge is exacerbated by entangled parameter spaces from continuous multi-domain training, often resulting in collateral damage, especially under aggressive unlearning strategies. Furthermore, the computational overhead required to optimize State-of-the-Art (SOTA) models with billions of parameters poses an additional barrier. In this work, we present ALTER, a lightweight unlearning framework for LLMs to address both the challenges of knowledge entanglement and unlearning efficiency. ALTER operates through two phases: (I) high entropy tokens are captured and learned via the shared A matrix in LoRA, followed by (II) an asymmetric LoRA architecture that achieves a specified forgetting objective by parameter isolation and unlearning tokens within the target subdomains. Serving as a new research direction for achieving unlearning via token-level isolation in the asymmetric framework. ALTER achieves SOTA performance on TOFU, WMDP, and MUSE benchmarks with over 95% forget quality and shows minimal side effects through preserving foundational tokens. By decoupling unlearning from LLMs' billion-scale parameters, this framework delivers excellent efficiency while preserving over 90% of model utility, exceeding baseline preservation rates of 47.8-83.6%.
Unleashing the Potential of Neighbors: Diffusion-based Latent Neighbor Generation for Session-based Recommendation
Jan 07, 2026Session-based recommendation aims to predict the next item that anonymous users may be interested in, based on their current session interactions. Recent studies have demonstrated that retrieving neighbor sessions to augment the current session can effectively alleviate the data sparsity issue and improve recommendation performance. However, existing methods typically rely on explicitly observed session data, neglecting latent neighbors - not directly observed but potentially relevant within the interest space - thereby failing to fully exploit the potential of neighbor sessions in recommendation. To address the above limitation, we propose a novel model of diffusion-based latent neighbor generation for session-based recommendation, named DiffSBR. Specifically, DiffSBR leverages two diffusion modules, including retrieval-augmented diffusion and self-augmented diffusion, to generate high-quality latent neighbors. In the retrieval-augmented diffusion module, we leverage retrieved neighbors as guiding signals to constrain and reconstruct the distribution of latent neighbors. Meanwhile, we adopt a training strategy that enables the retriever to learn from the feedback provided by the generator. In the self-augmented diffusion module, we explicitly guide the generation of latent neighbors by injecting the current session's multi-modal signals through contrastive learning. After obtaining the generated latent neighbors, we utilize them to enhance session representations for improving session-based recommendation. Extensive experiments on four public datasets show that DiffSBR generates effective latent neighbors and improves recommendation performance against state-of-the-art baselines.
Pushing the Limits of Safety: A Technical Report on the ATLAS Challenge 2025
Jun 14, 2025Multimodal Large Language Models (MLLMs) have enabled transformative advancements across diverse applications but remain susceptible to safety threats, especially jailbreak attacks that induce harmful outputs. To systematically evaluate and improve their safety, we organized the Adversarial Testing & Large-model Alignment Safety Grand Challenge (ATLAS) 2025}. This technical report presents findings from the competition, which involved 86 teams testing MLLM vulnerabilities via adversarial image-text attacks in two phases: white-box and black-box evaluations. The competition results highlight ongoing challenges in securing MLLMs and provide valuable guidance for developing stronger defense mechanisms. The challenge establishes new benchmarks for MLLM safety evaluation and lays groundwork for advancing safer multimodal AI systems. The code and data for this challenge are openly available at https://github.com/NY1024/ATLAS_Challenge_2025.
Beyond Whole Dialogue Modeling: Contextual Disentanglement for Conversational Recommendation
Apr 24, 2025Conversational recommender systems aim to provide personalized recommendations by analyzing and utilizing contextual information related to dialogue. However, existing methods typically model the dialogue context as a whole, neglecting the inherent complexity and entanglement within the dialogue. Specifically, a dialogue comprises both focus information and background information, which mutually influence each other. Current methods tend to model these two types of information mixedly, leading to misinterpretation of users' actual needs, thereby lowering the accuracy of recommendations. To address this issue, this paper proposes a novel model to introduce contextual disentanglement for improving conversational recommender systems, named DisenCRS. The proposed model DisenCRS employs a dual disentanglement framework, including self-supervised contrastive disentanglement and counterfactual inference disentanglement, to effectively distinguish focus information and background information from the dialogue context under unsupervised conditions. Moreover, we design an adaptive prompt learning module to automatically select the most suitable prompt based on the specific dialogue context, fully leveraging the power of large language models. Experimental results on two widely used public datasets demonstrate that DisenCRS significantly outperforms existing conversational recommendation models, achieving superior performance on both item recommendation and response generation tasks.
Multi-Type Context-Aware Conversational Recommender Systems via Mixture-of-Experts
Apr 18, 2025Conversational recommender systems enable natural language conversations and thus lead to a more engaging and effective recommendation scenario. As the conversations for recommender systems usually contain limited contextual information, many existing conversational recommender systems incorporate external sources to enrich the contextual information. However, how to combine different types of contextual information is still a challenge. In this paper, we propose a multi-type context-aware conversational recommender system, called MCCRS, effectively fusing multi-type contextual information via mixture-of-experts to improve conversational recommender systems. MCCRS incorporates both structured information and unstructured information, including the structured knowledge graph, unstructured conversation history, and unstructured item reviews. It consists of several experts, with each expert specialized in a particular domain (i.e., one specific contextual information). Multiple experts are then coordinated by a ChairBot to generate the final results. Our proposed MCCRS model takes advantage of different contextual information and the specialization of different experts followed by a ChairBot breaks the model bottleneck on a single contextual information. Experimental results demonstrate that our proposed MCCRS method achieves significantly higher performance compared to existing baselines.
Syzygy of Thoughts: Improving LLM CoT with the Minimal Free Resolution
Apr 16, 2025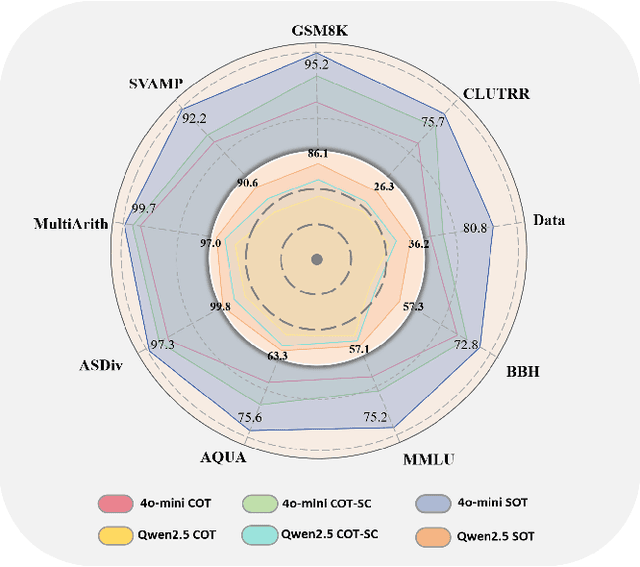
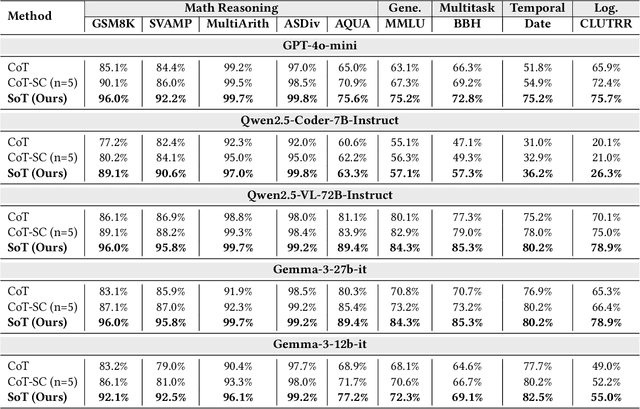
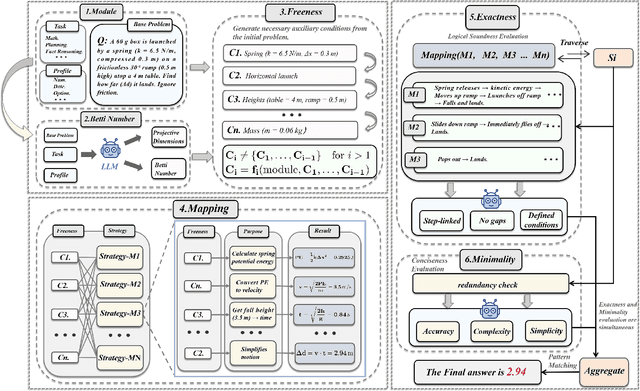

Chain-of-Thought (CoT) prompting enhances the reasoning of large language models (LLMs) by decomposing problems into sequential steps, mimicking human logic and reducing errors. However, complex tasks with vast solution spaces and vague constraints often exceed the capacity of a single reasoning chain. Inspired by Minimal Free Resolution (MFR) in commutative algebra and algebraic geometry, we propose Syzygy of Thoughts (SoT)-a novel framework that extends CoT by introducing auxiliary, interrelated reasoning paths. SoT captures deeper logical dependencies, enabling more robust and structured problem-solving. MFR decomposes a module into a sequence of free modules with minimal rank, providing a structured analytical approach to complex systems. This method introduces the concepts of "Module", "Betti numbers","Freeness", "Mapping", "Exactness" and "Minimality", enabling the systematic decomposition of the original complex problem into logically complete minimal subproblems while preserving key problem features and reducing reasoning length. We tested SoT across diverse datasets (e.g., GSM8K, MATH) and models (e.g., GPT-4o-mini, Qwen2.5), achieving inference accuracy that matches or surpasses mainstream CoTs standards. Additionally, by aligning the sampling process with algebraic constraints, our approach enhances the scalability of inference time in LLMs, ensuring both transparent reasoning and high performance. Our code will be publicly available at https://github.com/dlMARiA/Syzygy-of-thoughts.
LoLDU: Low-Rank Adaptation via Lower-Diag-Upper Decomposition for Parameter-Efficient Fine-Tuning
Oct 17, 2024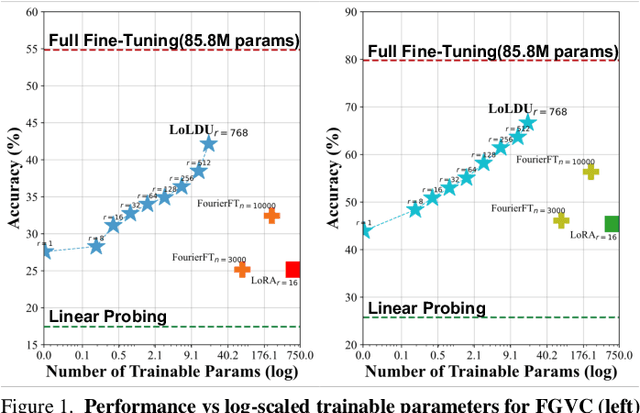
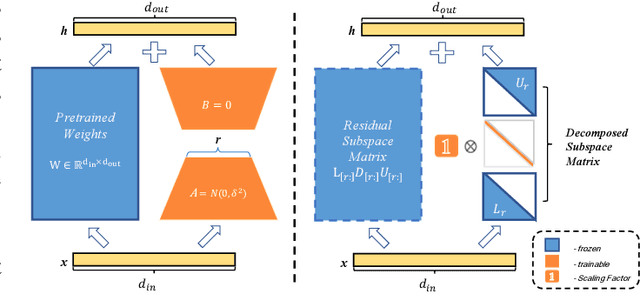
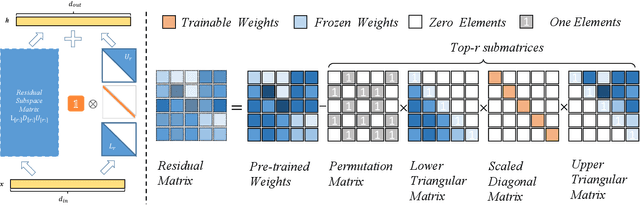
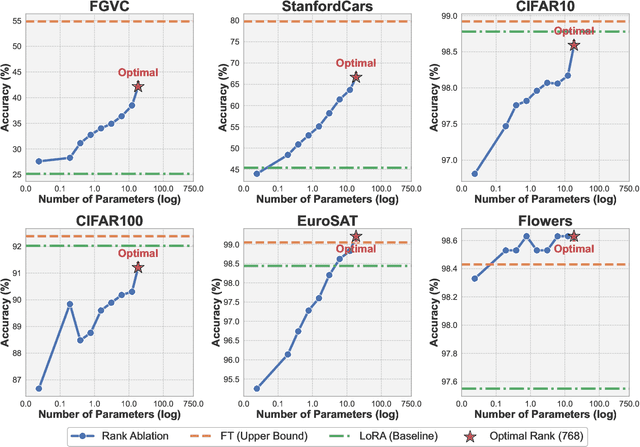
The rapid growth of model scale has necessitated substantial computational resources for fine-tuning. Existing approach such as Low-Rank Adaptation (LoRA) has sought to address the problem of handling the large updated parameters in full fine-tuning. However, LoRA utilize random initialization and optimization of low-rank matrices to approximate updated weights, which can result in suboptimal convergence and an accuracy gap compared to full fine-tuning. To address these issues, we propose LoLDU, a Parameter-Efficient Fine-Tuning (PEFT) approach that significantly reduces trainable parameters by 2600 times compared to regular PEFT methods while maintaining comparable performance. LoLDU leverages Lower-Diag-Upper Decomposition (LDU) to initialize low-rank matrices for faster convergence and orthogonality. We focus on optimizing the diagonal matrix for scaling transformations. To the best of our knowledge, LoLDU has the fewest parameters among all PEFT approaches. We conducted extensive experiments across 4 instruction-following datasets, 6 natural language understanding (NLU) datasets, 8 image classification datasets, and image generation datasets with multiple model types (LLaMA2, RoBERTa, ViT, and Stable Diffusion), providing a comprehensive and detailed analysis. Our open-source code can be accessed at \href{https://github.com/SKDDJ/LoLDU}{https://github.com/SKDDJ/LoLDU}.
SVFit: Parameter-Efficient Fine-Tuning of Large Pre-Trained Models Using Singular Values
Sep 09, 2024

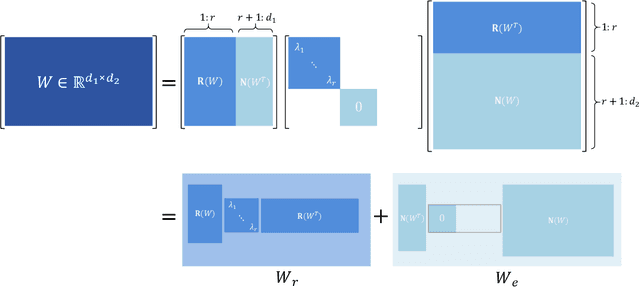

Large pre-trained models (LPMs) have demonstrated exceptional performance in diverse natural language processing and computer vision tasks. However, fully fine-tuning these models poses substantial memory challenges, particularly in resource-constrained environments. Parameter-efficient fine-tuning (PEFT) methods, such as LoRA, mitigate this issue by adjusting only a small subset of parameters. Nevertheless, these methods typically employ random initialization for low-rank matrices, which can lead to inefficiencies in gradient descent and diminished generalizability due to suboptimal starting points. To address these limitations, we propose SVFit, a novel PEFT approach that leverages singular value decomposition (SVD) to initialize low-rank matrices using critical singular values as trainable parameters. Specifically, SVFit performs SVD on the pre-trained weight matrix to obtain the best rank-r approximation matrix, emphasizing the most critical singular values that capture over 99% of the matrix's information. These top-r singular values are then used as trainable parameters to scale the fundamental subspaces of the matrix, facilitating rapid domain adaptation. Extensive experiments across various pre-trained models in natural language understanding, text-to-image generation, and image classification tasks reveal that SVFit outperforms LoRA while requiring 16 times fewer trainable parameters.