 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoLDU: Low-Rank Adaptation via Lower-Diag-Upper Decomposition for Parameter-Efficient Fine-Tuning
Paper and Code
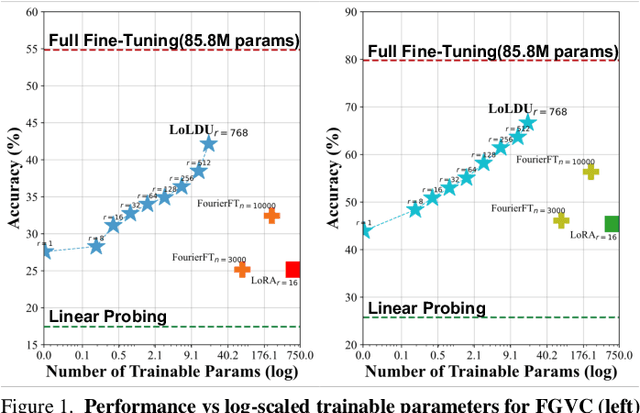
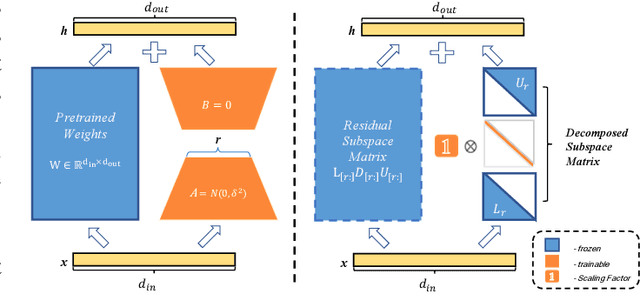
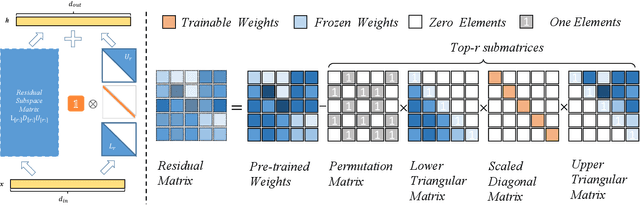
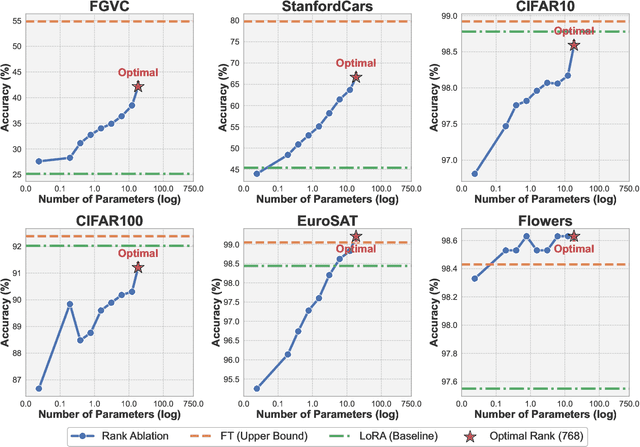
The rapid growth of model scale has necessitated substantial computational resources for fine-tuning. Existing approach such as Low-Rank Adaptation (LoRA) has sought to address the problem of handling the large updated parameters in full fine-tuning. However, LoRA utilize random initialization and optimization of low-rank matrices to approximate updated weights, which can result in suboptimal convergence and an accuracy gap compared to full fine-tuning. To address these issues, we propose LoLDU, a Parameter-Efficient Fine-Tuning (PEFT) approach that significantly reduces trainable parameters by 2600 times compared to regular PEFT methods while maintaining comparable performance. LoLDU leverages Lower-Diag-Upper Decomposition (LDU) to initialize low-rank matrices for faster convergence and orthogonality. We focus on optimizing the diagonal matrix for scaling transformations. To the best of our knowledge, LoLDU has the fewest parameters among all PEFT approaches. We conducted extensive experiments across 4 instruction-following datasets, 6 natural language understanding (NLU) datasets, 8 image classification datasets, and image generation datasets with multiple model types (LLaMA2, RoBERTa, ViT, and Stable Diffusion), providing a comprehensive and detailed analysis. Our open-source code can be accessed at \href{https://github.com/SKDDJ/LoLDU}{https://github.com/SKDDJ/LoLDU}.