 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance-Variant Loss with Gaussian RBF Kernel for 3D Cross-modal Retriveal
Paper and Code
May 07, 2023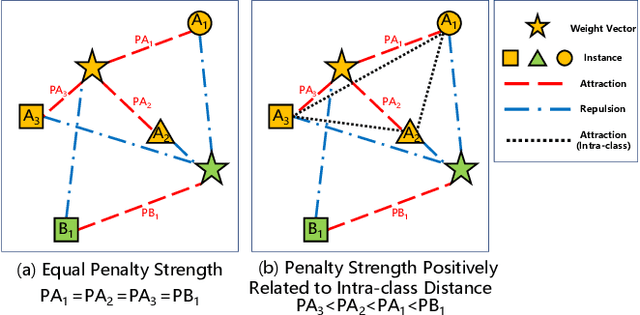
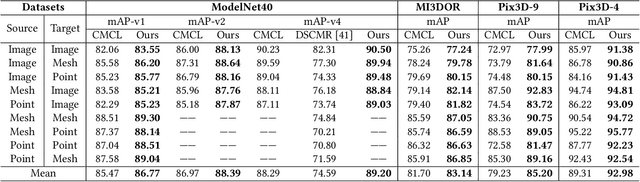
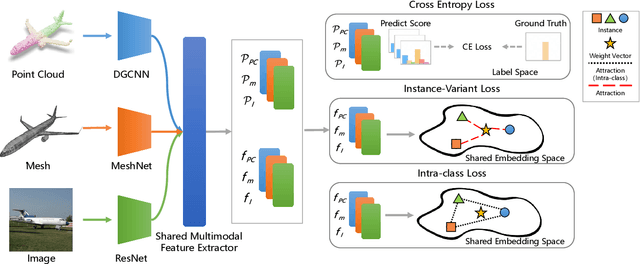
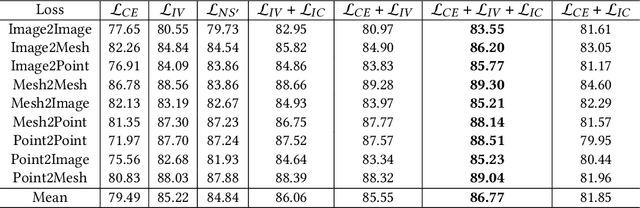
3D cross-modal retrieval is gaining attention in the multimedia community. Central to this topic is learning a joint embedding space to represent data from different modalities, such as images, 3D point clouds, and polygon meshes, to extract modality-invariant and discriminative features. Hence, the performance of cross-modal retrieval methods heavily depends on the representational capacity of this embedding space. Existing methods treat all instances equally, applying the same penalty strength to instances with varying degrees of difficulty, ignoring the differences between instances. This can result in ambiguous convergence or local optima, severely compromising the separability of the feature space. To address this limitation, we propose an Instance-Variant loss to assign different penalty strengths to different instances, improving the space separability. Specifically, we assign different penalty weights to instances positively related to their intra-class distance. Simultaneously, we reduce the cross-modal discrepancy between features by learning a shared weight vector for the same class data from different modalities. By leveraging the Gaussian RBF kernel to evaluate sample similarity, we further propose an Intra-Class loss function that minimizes the intra-class distance among same-class instances. Extensive experiments on three 3D cross-modal datasets show that our proposed method surpasses recent state-of-the-art approaches.