 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Alignment Barriers: TPS-Driven Semantic Correlation Learning for Alignment-Free RGB-T Salient Object Detection
Dec 26, 2025Existing RGB-T salient object detection methods predominantly rely on manually aligned and annotated datasets, struggling to handle real-world scenarios with raw, unaligned RGB-T image pairs. In practical applications, due to significant cross-modal disparities such as spatial misalignment, scale variations, and viewpoint shifts, the performance of current methods drastically deteriorates on unaligned datasets. To address this issue, we propose an efficient RGB-T SOD method for real-world unaligned image pairs, termed Thin-Plate Spline-driven Semantic Correlation Learning Network (TPS-SCL). We employ a dual-stream MobileViT as the encoder, combined with efficient Mamba scanning mechanisms, to effectively model correlations between the two modalities while maintaining low parameter counts and computational overhead. To suppress interference from redundant background information during alignment, we design a Semantic Correlation Constraint Module (SCCM) to hierarchically constrain salient features. Furthermore, we introduce a Thin-Plate Spline Alignment Module (TPSAM) to mitigate spatial discrepancies between modalities. Additionally, a Cross-Modal Correlation Module (CMCM) is incorporated to fully explore and integrate inter-modal dependencies, enhancing detection performance. Extensive experiments on various datasets demonstrate that TPS-SCL attains state-of-the-art (SOTA) performance among existing lightweight SOD methods and outperforms mainstream RGB-T SOD approaches.
Beyond Whole Dialogue Modeling: Contextual Disentanglement for Conversational Recommendation
Apr 24, 2025Conversational recommender systems aim to provide personalized recommendations by analyzing and utilizing contextual information related to dialogue. However, existing methods typically model the dialogue context as a whole, neglecting the inherent complexity and entanglement within the dialogue. Specifically, a dialogue comprises both focus information and background information, which mutually influence each other. Current methods tend to model these two types of information mixedly, leading to misinterpretation of users' actual needs, thereby lowering the accuracy of recommendations. To address this issue, this paper proposes a novel model to introduce contextual disentanglement for improving conversational recommender systems, named DisenCRS. The proposed model DisenCRS employs a dual disentanglement framework, including self-supervised contrastive disentanglement and counterfactual inference disentanglement, to effectively distinguish focus information and background information from the dialogue context under unsupervised conditions. Moreover, we design an adaptive prompt learning module to automatically select the most suitable prompt based on the specific dialogue context, fully leveraging the power of large language models. Experimental results on two widely used public datasets demonstrate that DisenCRS significantly outperforms existing conversational recommendation models, achieving superior performance on both item recommendation and response generation tasks.
Behavior-Contextualized Item Preference Modeling for Multi-Behavior Recommendation
Apr 28, 2024In recommender systems, multi-behavior methods have demonstrated their effectiveness in mitigating issues like data sparsity, a common challenge in traditional single-behavior recommendation approaches. These methods typically infer user preferences from various auxiliary behaviors and apply them to the target behavior for recommendations. However, this direct transfer can introduce noise to the target behavior in recommendation, due to variations in user attention across different behaviors. To address this issue, this paper introduces a novel approach, Behavior-Contextualized Item Preference Modeling (BCIPM), for multi-behavior recommendation. Our proposed Behavior-Contextualized Item Preference Network discerns and learns users' specific item preferences within each behavior. It then considers only those preferences relevant to the target behavior for final recommendations, significantly reducing noise from auxiliary behaviors. These auxiliary behaviors are utilized solely for training the network parameters, thereby refining the learning process without compromising the accuracy of the target behavior recommendations. To further enhance the effectiveness of BCIPM, we adopt a strategy of pre-training the initial embeddings. This step is crucial for enriching the item-aware preferences, particularly in scenarios where data related to the target behavior is sparse. Comprehensive experiments conducted on four real-world datasets demonstrate BCIPM's superior performance compared to several leading state-of-the-art models, validating the robustness and efficiency of our proposed approach.
MB-HGCN: A Hierarchical Graph Convolutional Network for Multi-behavior Recommendation
Jun 19, 2023Collaborative filtering-based recommender systems that rely on a single type of behavior often encounter serious sparsity issues in real-world applications, leading to unsatisfactory performance. Multi-behavior Recommendation (MBR) is a method that seeks to learn user preferences, represented as vector embeddings, from auxiliary information. By leveraging these preferences for target behavior recommendations, MBR addresses the sparsity problem and improves the accuracy of recommendations. In this paper, we propose MB-HGCN, a novel multi-behavior recommendation model that uses a hierarchical graph convolutional network to learn user and item embeddings from coarse-grained on the global level to fine-grained on the behavior-specific level. Our model learns global embeddings from a unified homogeneous graph constructed by the interactions of all behaviors, which are then used as initialized embeddings for behavior-specific embedding learning in each behavior graph. We also emphasize the distinct of the user and item behaviorspecific embeddings and design two simple-yet-effective strategies to aggregate the behavior-specific embeddings for users and items, respectively. Finally, we adopt multi-task learning for optimization. Extensive experimental results on three real-world datasets demonstrate that our model significantly outperforms the baselines, achieving a relative improvement of 73.93% and 74.21% for HR@10 and NDCG@10, respectively, on the Tmall datasets.
Cascading Residual Graph Convolutional Network for Multi-Behavior Recommendation
May 26, 2022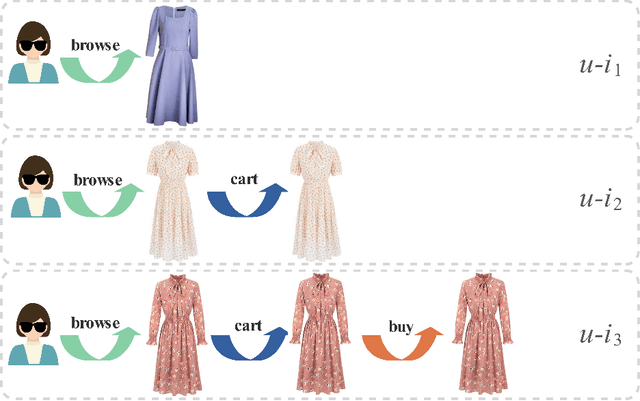

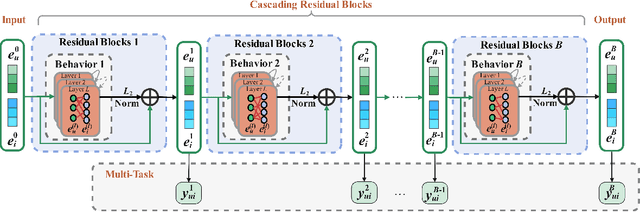
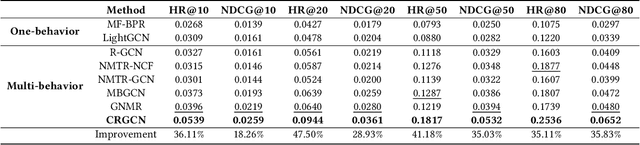
Multi-behavior recommendation exploits multiple types of user-item interactions to alleviate the data sparsity problem faced by the traditional models that often utilize only one type of interaction for recommendation. In real scenarios, users often take a sequence of actions to interact with an item, in order to get more information about the item and thus accurately evaluate whether an item fits personal preference. Those interaction behaviors often obey a certain order, and different behaviors reveal different information or aspects of user preferences towards the target item. Most existing multi-behavior recommendation methods take the strategy to first extract information from different behaviors separately and then fuse them for final prediction. However, they have not exploited the connections between different behaviors to learn user preferences. Besides, they often introduce complex model structures and more parameters to model multiple behaviors, largely increasing the space and time complexity. In this work, we propose a lightweight multi-behavior recommendation model named Cascading Residual Graph Convolutional Network (CRGCN for short), which can explicitly exploit the connections between different behaviors into the embedding learning process without introducing any additional parameters. In particular, we design a cascading residual graph convolutional network structure, which enables our model to learn user preferences by continuously refining user embeddings across different types of behaviors. The multi-task learning method is adopted to jointly optimize our model based on different behaviors. Extensive experimental results on two real-world benchmark datasets show that CRGCN can substantially outperform state-of-the-art methods. Further studies also analyze the effects of leveraging multi-behaviors in different numbers and orders on the final performance.
Sparsely-Labeled Source Assisted Domain Adaptation
May 08, 2020
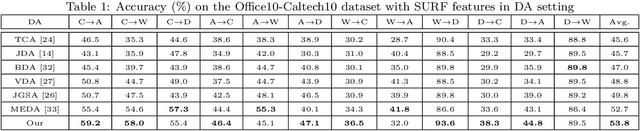
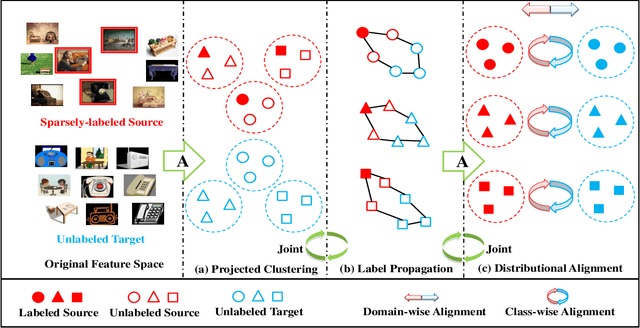

Domain Adaptation (DA) aims to generalize the classifier learned from the source domain to the target domain. Existing DA methods usually assume that rich labels could be available in the source domain. However, there are usually a large number of unlabeled data but only a few labeled data in the source domain, and how to transfer knowledge from this sparsely-labeled source domain to the target domain is still a challenge, which greatly limits their application in the wild. This paper proposes a novel Sparsely-Labeled Source Assisted Domain Adaptation (SLSA-DA) algorithm to address the challenge with limited labeled source domain samples. Specifically, due to the label scarcity problem, the projected clustering is conducted on both the source and target domains, so that the discriminative structures of data could be leveraged elegantly. Then the label propagation is adopted to propagate the labels from those limited labeled source samples to the whole unlabeled data progressively, so that the cluster labels are revealed correctly. Finally, we jointly align the marginal and conditional distributions to mitigate the cross-domain mismatch problem, and optimize those three procedures iteratively. However, it is nontrivial to incorporate those three procedures into a unified optimization framework seamlessly since some variables to be optimized are implicitly involved in their formulas, thus they could not promote to each other. Remarkably, we prove that the projected clustering and conditional distribution alignment could be reformulated as different expressions, thus the implicit variables are revealed in different optimization steps. As such, the variables related to those three quantities could be optimized in a unified optimization framework and facilitate to each other, to improve the recognition performance obviously.