 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEcho-DM: Ultrasound Marker Removal via Conditional Latent Diffusion and Region-Aware Fusion
Jun 08, 2026Clinical ultrasound images often contain artificial markers, such as measurement calipers and text, to assist diagnostic interpretation and comparison. However, these markers can introduce shortcut bias in downstream automated analysis, encouraging deep learning models to rely on marker-related cues rather than clinically meaningful anatomy. Existing marker removal methods are either mask-dependent and vulnerable to error propagation, or mask-free deterministic restorers that may over-smooth ultrasound texture and perturb unaffected background regions. To address these challenges, we present Echo-DM, a framework for ultrasound marker removal via conditional latent diffusion and region-aware fusion. Echo-DM follows a common encoder-diffusion-decoder pipeline, where a DiT-based conditional latent diffusion network performs global restoration and a region-aware fusion module enforces preservation-aware image-space refinement under end-to-end mask-free inference. Building on this fixed core design, we further instantiate Echo-DM-V and Echo-DM-R with VAE-based and RAE-based latent modules, respectively, which demonstrates that the Echo-DM architecture is compatible with diverse latent-module instantiations. Extensive experiments on Echo-PAIR, a large-scale paired clinical ultrasound dataset, demonstrate superior marker removal and strong anatomical fidelity compared with representative two-stage baselines, while providing favorable quality--efficiency trade-offs across deployment settings. Data, code and models will be released at https://github.com/MiliLab/Echo-DM.
DASH-KV: Accelerating Long-Context LLM Inference via Asymmetric KV Cache Hashing
Apr 22, 2026The quadratic computational complexity of the standard attention mechanism constitutes a fundamental bottleneck for large language models in long-context inference. While existing KV cache compression methods alleviate memory pressure, they often sacrifice generation quality and fail to address the high overhead of floating-point arithmetic. This paper introduces DASH-KV, an innovative acceleration framework that reformulates attention as approximate nearest-neighbor search via asymmetric deep hashing. Under this paradigm, we design an asymmetric encoding architecture that differentially maps queries and keys to account for their distinctions in precision and reuse characteristics. To balance efficiency and accuracy, we further introduce a dynamic mixed-precision mechanism that adaptively retains full-precision computation for critical tokens. Extensive experiments on LongBench demonstrate that DASH-KV significantly outperforms state-of-the-art baseline methods while matching the performance of full attention, all while reducing inference complexity from O(N^2) to linear O(N). The code is available at https://github.com/Zhihan-Zh/DASH-KV
Lightweight LLM Agent Memory with Small Language Models
Apr 09, 2026Although LLM agents can leverage tools for complex tasks, they still need memory to maintain cross-turn consistency and accumulate reusable information in long-horizon interactions. However, retrieval-based external memory systems incur low online overhead but suffer from unstable accuracy due to limited query construction and candidate filtering. In contrast, many systems use repeated large-model calls for online memory operations, improving accuracy but accumulating latency over long interactions. We propose LightMem, a lightweight memory system for better agent memory driven by Small Language Models (SLMs). LightMem modularizes memory retrieval, writing, and long-term consolidation, and separates online processing from offline consolidation to enable efficient memory invocation under bounded compute. We organize memory into short-term memory (STM) for immediate conversational context, mid-term memory (MTM) for reusable interaction summaries, and long-term memory (LTM) for consolidated knowledge, and uses user identifiers to support independent retrieval and incremental maintenance in multi-user settings. Online, LightMem operates under a fixed retrieval budget and selects memories via a two-stage procedure: vector-based coarse retrieval followed by semantic consistency re-ranking. Offline, it abstracts reusable interaction evidence and incrementally integrates it into LTM. Experiments show gains across model scales, with an average F1 improvement of about 2.5 on LoCoMo, more effective and low median latency (83 ms retrieval; 581 ms end-to-end).
Efficient and Interpretable Multi-Agent LLM Routing via Ant Colony Optimization
Mar 13, 2026Large Language Model (LLM)-driven Multi-Agent Systems (MAS) have demonstrated strong capability in complex reasoning and tool use, and heterogeneous agent pools further broaden the quality--cost trade-off space. Despite these advances, real-world deployment is often constrained by high inference cost, latency, and limited transparency, which hinders scalable and efficient routing. Existing routing strategies typically rely on expensive LLM-based selectors or static policies, and offer limited controllability for semantic-aware routing under dynamic loads and mixed intents, often resulting in unstable performance and inefficient resource utilization. To address these limitations, we propose AMRO-S, an efficient and interpretable routing framework for Multi-Agent Systems (MAS). AMRO-S models MAS routing as a semantic-conditioned path selection problem, enhancing routing performance through three key mechanisms: First, it leverages a supervised fine-tuned (SFT) small language model for intent inference, providing a low-overhead semantic interface for each query; second, it decomposes routing memory into task-specific pheromone specialists, reducing cross-task interference and optimizing path selection under mixed workloads; finally, it employs a quality-gated asynchronous update mechanism to decouple inference from learning, optimizing routing without increasing latency. Extensive experiments on five public benchmarks and high-concurrency stress tests demonstrate that AMRO-S consistently improves the quality--cost trade-off over strong routing baselines, while providing traceable routing evidence through structured pheromone patterns.
ALTER: Asymmetric LoRA for Token-Entropy-Guided Unlearning of LLMs
Mar 02, 2026Large language models (LLMs) have advanced to encompass extensive knowledge across diverse domains. Yet controlling what a LLMs should not know is important for ensuring alignment and thus safe use. However, effective unlearning in LLMs is difficult due to the fuzzy boundary between knowledge retention and forgetting. This challenge is exacerbated by entangled parameter spaces from continuous multi-domain training, often resulting in collateral damage, especially under aggressive unlearning strategies. Furthermore, the computational overhead required to optimize State-of-the-Art (SOTA) models with billions of parameters poses an additional barrier. In this work, we present ALTER, a lightweight unlearning framework for LLMs to address both the challenges of knowledge entanglement and unlearning efficiency. ALTER operates through two phases: (I) high entropy tokens are captured and learned via the shared A matrix in LoRA, followed by (II) an asymmetric LoRA architecture that achieves a specified forgetting objective by parameter isolation and unlearning tokens within the target subdomains. Serving as a new research direction for achieving unlearning via token-level isolation in the asymmetric framework. ALTER achieves SOTA performance on TOFU, WMDP, and MUSE benchmarks with over 95% forget quality and shows minimal side effects through preserving foundational tokens. By decoupling unlearning from LLMs' billion-scale parameters, this framework delivers excellent efficiency while preserving over 90% of model utility, exceeding baseline preservation rates of 47.8-83.6%.
GHS-TDA: A Synergistic Reasoning Framework Integrating Global Hypothesis Space with Topological Data Analysis
Feb 10, 2026Chain-of-Thought (CoT) has been shown to significantly improve the reasoning accuracy of large language models (LLMs) on complex tasks. However, due to the autoregressive, step-by-step generation paradigm, existing CoT methods suffer from two fundamental limitations. First, the reasoning process is highly sensitive to early decisions: once an initial error is introduced, it tends to propagate and amplify through subsequent steps, while the lack of a global coordination and revision mechanism makes such errors difficult to correct, ultimately leading to distorted reasoning chains. Second, current CoT approaches lack structured analysis techniques for filtering redundant reasoning and extracting key reasoning features, resulting in unstable reasoning processes and limited interpretability. To address these issues, we propose GHS-TDA. GHS-TDA first constructs a semantically enriched global hypothesis graph to aggregate, align, and coordinate multiple candidate reasoning paths, thereby providing alternative global correction routes when local reasoning fails. It then applies topological data analysis based on persistent homology to capture stable multi-scale structures, remove redundancy and inconsistencies, and extract a more reliable reasoning skeleton. By jointly leveraging reasoning diversity and topological stability, GHS-TDA achieves self-adaptive convergence, produces high-confidence and interpretable reasoning paths, and consistently outperforms strong baselines in terms of both accuracy and robustness across multiple reasoning benchmarks.
Unleashing the Potential of Neighbors: Diffusion-based Latent Neighbor Generation for Session-based Recommendation
Jan 07, 2026Session-based recommendation aims to predict the next item that anonymous users may be interested in, based on their current session interactions. Recent studies have demonstrated that retrieving neighbor sessions to augment the current session can effectively alleviate the data sparsity issue and improve recommendation performance. However, existing methods typically rely on explicitly observed session data, neglecting latent neighbors - not directly observed but potentially relevant within the interest space - thereby failing to fully exploit the potential of neighbor sessions in recommendation. To address the above limitation, we propose a novel model of diffusion-based latent neighbor generation for session-based recommendation, named DiffSBR. Specifically, DiffSBR leverages two diffusion modules, including retrieval-augmented diffusion and self-augmented diffusion, to generate high-quality latent neighbors. In the retrieval-augmented diffusion module, we leverage retrieved neighbors as guiding signals to constrain and reconstruct the distribution of latent neighbors. Meanwhile, we adopt a training strategy that enables the retriever to learn from the feedback provided by the generator. In the self-augmented diffusion module, we explicitly guide the generation of latent neighbors by injecting the current session's multi-modal signals through contrastive learning. After obtaining the generated latent neighbors, we utilize them to enhance session representations for improving session-based recommendation. Extensive experiments on four public datasets show that DiffSBR generates effective latent neighbors and improves recommendation performance against state-of-the-art baselines.
HS-SLAM: A Fast and Hybrid Strategy-Based SLAM Approach for Low-Speed Autonomous Driving
May 27, 2025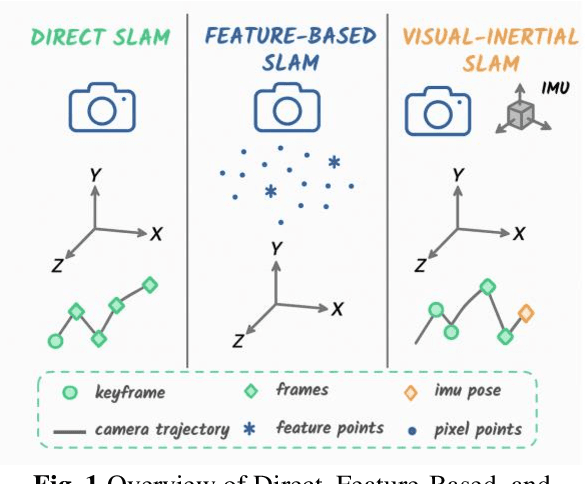


Visual-inertial simultaneous localization and mapping (SLAM) is a key module of robotics and low-speed autonomous vehicles, which is usually limited by the high computation burden for practical applications. To this end, an innovative strategy-based hybrid framework HS-SLAM is proposed to integrate the advantages of direct and feature-based methods for fast computation without decreasing the performance. It first estimates the relative positions of consecutive frames using IMU pose estimation within the tracking thread. Then, it refines these estimates through a multi-layer direct method, which progressively corrects the relative pose from coarse to fine, ultimately achieving accurate corner-based feature matching. This approach serves as an alternative to the conventional constant-velocity tracking model. By selectively bypassing descriptor extraction for non-critical frames, HS-SLAM significantly improves the tracking speed. Experimental evaluations on the EuRoC MAV dataset demonstrate that HS-SLAM achieves higher localization accuracies than ORB-SLAM3 while improving the average tracking efficiency by 15%.
Beyond Whole Dialogue Modeling: Contextual Disentanglement for Conversational Recommendation
Apr 24, 2025Conversational recommender systems aim to provide personalized recommendations by analyzing and utilizing contextual information related to dialogue. However, existing methods typically model the dialogue context as a whole, neglecting the inherent complexity and entanglement within the dialogue. Specifically, a dialogue comprises both focus information and background information, which mutually influence each other. Current methods tend to model these two types of information mixedly, leading to misinterpretation of users' actual needs, thereby lowering the accuracy of recommendations. To address this issue, this paper proposes a novel model to introduce contextual disentanglement for improving conversational recommender systems, named DisenCRS. The proposed model DisenCRS employs a dual disentanglement framework, including self-supervised contrastive disentanglement and counterfactual inference disentanglement, to effectively distinguish focus information and background information from the dialogue context under unsupervised conditions. Moreover, we design an adaptive prompt learning module to automatically select the most suitable prompt based on the specific dialogue context, fully leveraging the power of large language models. Experimental results on two widely used public datasets demonstrate that DisenCRS significantly outperforms existing conversational recommendation models, achieving superior performance on both item recommendation and response generation tasks.
Multi-Type Context-Aware Conversational Recommender Systems via Mixture-of-Experts
Apr 18, 2025Conversational recommender systems enable natural language conversations and thus lead to a more engaging and effective recommendation scenario. As the conversations for recommender systems usually contain limited contextual information, many existing conversational recommender systems incorporate external sources to enrich the contextual information. However, how to combine different types of contextual information is still a challenge. In this paper, we propose a multi-type context-aware conversational recommender system, called MCCRS, effectively fusing multi-type contextual information via mixture-of-experts to improve conversational recommender systems. MCCRS incorporates both structured information and unstructured information, including the structured knowledge graph, unstructured conversation history, and unstructured item reviews. It consists of several experts, with each expert specialized in a particular domain (i.e., one specific contextual information). Multiple experts are then coordinated by a ChairBot to generate the final results. Our proposed MCCRS model takes advantage of different contextual information and the specialization of different experts followed by a ChairBot breaks the model bottleneck on a single contextual information. Experimental results demonstrate that our proposed MCCRS method achieves significantly higher performance compared to existing baselines.