 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCL-CaGAN: Capsule differential adversarial continuous learning for cross-domain hyperspectral anomaly detection
May 17, 2025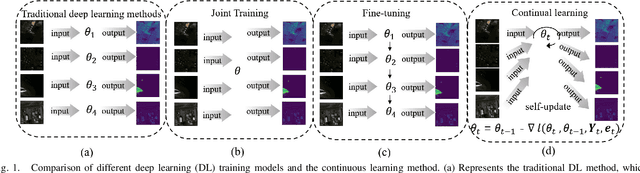
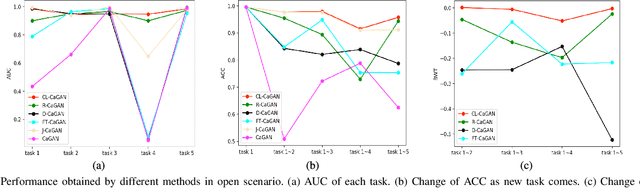
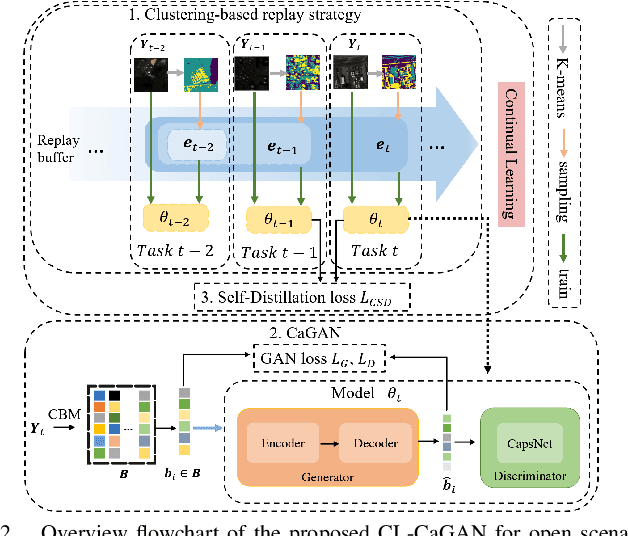
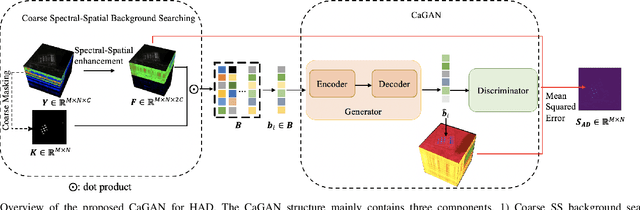
Anomaly detection (AD) has attracted remarkable attention in hyperspectral image (HSI) processing fields, and most existing deep learning (DL)-based algorithms indicate dramatic potential for detecting anomaly samples through specific training process under current scenario. However, the limited prior information and the catastrophic forgetting problem indicate crucial challenges for existing DL structure in open scenarios cross-domain detection. In order to improve the detection performance, a novel continual learning-based capsule differential generative adversarial network (CL-CaGAN) is proposed to elevate the cross-scenario learning performance for facilitating the real application of DL-based structure in hyperspectral AD (HAD) task. First, a modified capsule structure with adversarial learning network is constructed to estimate the background distribution for surmounting the deficiency of prior information. To mitigate the catastrophic forgetting phenomenon, clustering-based sample replay strategy and a designed extra self-distillation regularization are integrated for merging the history and future knowledge in continual AD task, while the discriminative learning ability from previous detection scenario to current scenario is retained by the elaborately designed structure with continual learning (CL) strategy. In addition, the differentiable enhancement is enforced to augment the generation performance of the training data. This further stabilizes the training process with better convergence and efficiently consolidates the reconstruction ability of background samples. To verify the effectiveness of our proposed CL-CaGAN, we conduct experiments on several real HSIs, and the results indicate that the proposed CL-CaGAN demonstrates higher detection performance and continuous learning capacity for mitigating the catastrophic forgetting under cross-domain scenarios.
Evaluating multiple large language models in pediatric ophthalmology
Nov 07, 2023



IMPORTANCE The response effectiveness of different large language models (LLMs) and various individuals, including medical students, graduate students, and practicing physicians, in pediatric ophthalmology consultations, has not been clearly established yet. OBJECTIVE Design a 100-question exam based on pediatric ophthalmology to evaluate the performance of LLMs in highly specialized scenarios and compare them with the performance of medical students and physicians at different levels. DESIGN, SETTING, AND PARTICIPANTS This survey study assessed three LLMs, namely ChatGPT (GPT-3.5), GPT-4, and PaLM2, were assessed alongside three human cohorts: medical students, postgraduate students, and attending physicians, in their ability to answer questions related to pediatric ophthalmology. It was conducted by administering questionnaires in the form of test papers through the LLM network interface, with the valuable participation of volunteers. MAIN OUTCOMES AND MEASURES Mean scores of LLM and humans on 100 multiple-choice questions, as well as the answer stability, correlation, and response confidence of each LLM. RESULTS GPT-4 performed comparably to attending physicians, while ChatGPT (GPT-3.5) and PaLM2 outperformed medical students but slightly trailed behind postgraduate students. Furthermore, GPT-4 exhibited greater stability and confidence when responding to inquiries compared to ChatGPT (GPT-3.5) and PaLM2. CONCLUSIONS AND RELEVANCE Our results underscore the potential for LLMs to provide medical assistance in pediatric ophthalmology and suggest significant capacity to guide the education of medical students.
Evaluating Large Language Models in Ophthalmology
Nov 07, 2023Purpose: The performance of three different large language models (LLMS) (GPT-3.5, GPT-4, and PaLM2) in answering ophthalmology professional questions was evaluated and compared with that of three different professional populations (medical undergraduates, medical masters, and attending physicians). Methods: A 100-item ophthalmology single-choice test was administered to three different LLMs (GPT-3.5, GPT-4, and PaLM2) and three different professional levels (medical undergraduates, medical masters, and attending physicians), respectively. The performance of LLM was comprehensively evaluated and compared with the human group in terms of average score, stability, and confidence. Results: Each LLM outperformed undergraduates in general, with GPT-3.5 and PaLM2 being slightly below the master's level, while GPT-4 showed a level comparable to that of attending physicians. In addition, GPT-4 showed significantly higher answer stability and confidence than GPT-3.5 and PaLM2. Conclusion: Our study shows that LLM represented by GPT-4 performs better in the field of ophthalmology. With further improvements, LLM will bring unexpected benefits in medical education and clinical decision making in the near future.