 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOphtha-LLaMA2: A Large Language Model for Ophthalmology
Dec 08, 2023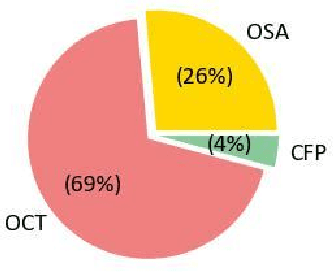

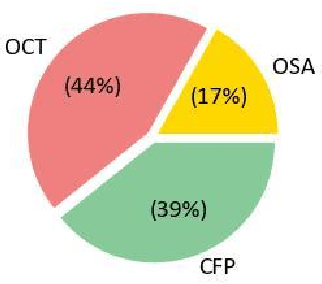
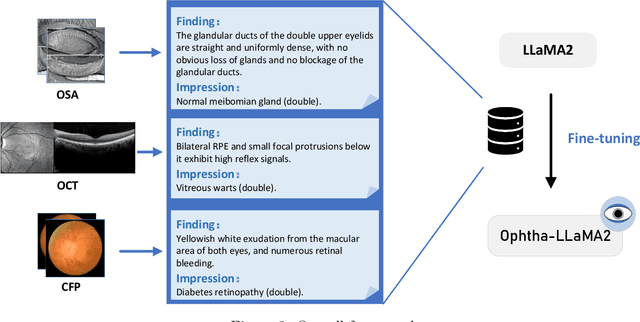
In recent years, pre-trained large language models (LLMs) have achieved tremendous success in the field of Natural Language Processing (NLP). Prior studies have primarily focused on general and generic domains, with relatively less research on specialized LLMs in the medical field. The specialization and high accuracy requirements for diagnosis in the medical field, as well as the challenges in collecting large-scale data, have constrained the application and development of LLMs in medical scenarios. In the field of ophthalmology, clinical diagnosis mainly relies on doctors' interpretation of reports and making diagnostic decisions. In order to take advantage of LLMs to provide decision support for doctors, we collected three modalities of ophthalmic report data and fine-tuned the LLaMA2 model, successfully constructing an LLM termed the "Ophtha-LLaMA2" specifically tailored for ophthalmic disease diagnosis. Inference test results show that even with a smaller fine-tuning dataset, Ophtha-LLaMA2 performs significantly better in ophthalmic diagnosis compared to other LLMs. It demonstrates that the Ophtha-LLaMA2 exhibits satisfying accuracy and efficiency in ophthalmic disease diagnosis, making it a valuable tool for ophthalmologists to provide improved diagnostic support for patients. This research provides a useful reference for the application of LLMs in the field of ophthalmology, while showcasing the immense potential and prospects in this domain.
Evaluating Large Language Models in Ophthalmology
Nov 07, 2023Purpose: The performance of three different large language models (LLMS) (GPT-3.5, GPT-4, and PaLM2) in answering ophthalmology professional questions was evaluated and compared with that of three different professional populations (medical undergraduates, medical masters, and attending physicians). Methods: A 100-item ophthalmology single-choice test was administered to three different LLMs (GPT-3.5, GPT-4, and PaLM2) and three different professional levels (medical undergraduates, medical masters, and attending physicians), respectively. The performance of LLM was comprehensively evaluated and compared with the human group in terms of average score, stability, and confidence. Results: Each LLM outperformed undergraduates in general, with GPT-3.5 and PaLM2 being slightly below the master's level, while GPT-4 showed a level comparable to that of attending physicians. In addition, GPT-4 showed significantly higher answer stability and confidence than GPT-3.5 and PaLM2. Conclusion: Our study shows that LLM represented by GPT-4 performs better in the field of ophthalmology. With further improvements, LLM will bring unexpected benefits in medical education and clinical decision making in the near future.