 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCL-BioGAN: Biologically-Inspired Cross-Domain Continual Learning for Hyperspectral Anomaly Detection
May 17, 2025Memory stability and learning flexibility in continual learning (CL) is a core challenge for cross-scene Hyperspectral Anomaly Detection (HAD) task. Biological neural networks can actively forget history knowledge that conflicts with the learning of new experiences by regulating learning-triggered synaptic expansion and synaptic convergence. Inspired by this phenomenon, we propose a novel Biologically-Inspired Continual Learning Generative Adversarial Network (CL-BioGAN) for augmenting continuous distribution fitting ability for cross-domain HAD task, where Continual Learning Bio-inspired Loss (CL-Bio Loss) and self-attention Generative Adversarial Network (BioGAN) are incorporated to realize forgetting history knowledge as well as involving replay strategy in the proposed BioGAN. Specifically, a novel Bio-Inspired Loss composed with an Active Forgetting Loss (AF Loss) and a CL loss is designed to realize parameters releasing and enhancing between new task and history tasks from a Bayesian perspective. Meanwhile, BioGAN loss with L2-Norm enhances self-attention (SA) to further balance the stability and flexibility for better fitting background distribution for open scenario HAD (OHAD) tasks. Experiment results underscore that the proposed CL-BioGAN can achieve more robust and satisfying accuracy for cross-domain HAD with fewer parameters and computation cost. This dual contribution not only elevates CL performance but also offers new insights into neural adaptation mechanisms in OHAD task.
CL-CaGAN: Capsule differential adversarial continuous learning for cross-domain hyperspectral anomaly detection
May 17, 2025
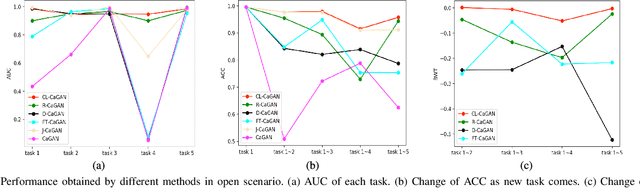
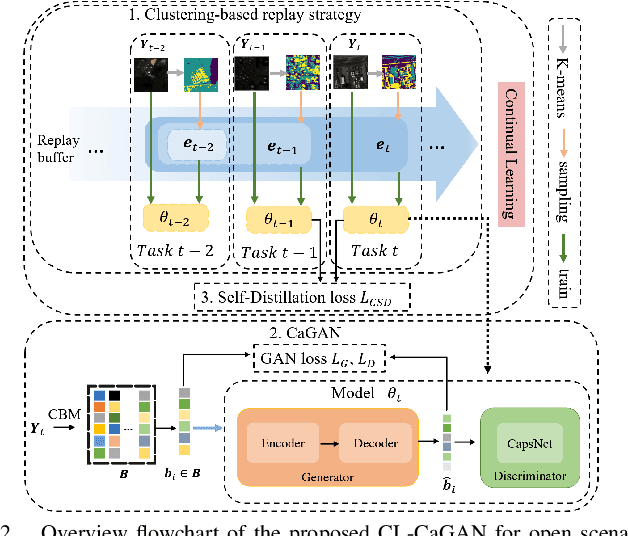
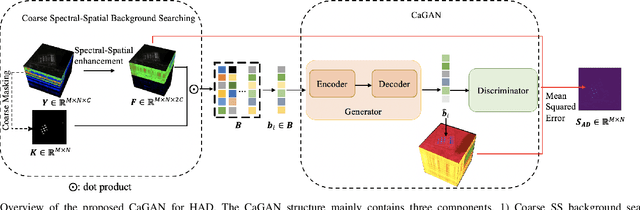
Anomaly detection (AD) has attracted remarkable attention in hyperspectral image (HSI) processing fields, and most existing deep learning (DL)-based algorithms indicate dramatic potential for detecting anomaly samples through specific training process under current scenario. However, the limited prior information and the catastrophic forgetting problem indicate crucial challenges for existing DL structure in open scenarios cross-domain detection. In order to improve the detection performance, a novel continual learning-based capsule differential generative adversarial network (CL-CaGAN) is proposed to elevate the cross-scenario learning performance for facilitating the real application of DL-based structure in hyperspectral AD (HAD) task. First, a modified capsule structure with adversarial learning network is constructed to estimate the background distribution for surmounting the deficiency of prior information. To mitigate the catastrophic forgetting phenomenon, clustering-based sample replay strategy and a designed extra self-distillation regularization are integrated for merging the history and future knowledge in continual AD task, while the discriminative learning ability from previous detection scenario to current scenario is retained by the elaborately designed structure with continual learning (CL) strategy. In addition, the differentiable enhancement is enforced to augment the generation performance of the training data. This further stabilizes the training process with better convergence and efficiently consolidates the reconstruction ability of background samples. To verify the effectiveness of our proposed CL-CaGAN, we conduct experiments on several real HSIs, and the results indicate that the proposed CL-CaGAN demonstrates higher detection performance and continuous learning capacity for mitigating the catastrophic forgetting under cross-domain scenarios.
A Unified Data Augmentation Framework for Low-Resource Multi-Domain Dialogue Generation
Jun 14, 2024



Current state-of-the-art dialogue systems heavily rely on extensive training datasets. However, challenges arise in domains where domain-specific training datasets are insufficient or entirely absent. To tackle this challenge, we propose a novel data \textbf{A}ugmentation framework for \textbf{M}ulti-\textbf{D}omain \textbf{D}ialogue \textbf{G}eneration, referred to as \textbf{AMD$^2$G}. The AMD$^2$G framework consists of a data augmentation process and a two-stage training approach: domain-agnostic training and domain adaptation training. We posit that domain corpora are a blend of domain-agnostic and domain-specific features, with certain representation patterns shared among diverse domains. Domain-agnostic training aims to enable models to learn these common expressive patterns. To construct domain-agnostic dialogue corpora, we employ a \textit{\textbf{de-domaining}} data processing technique used to remove domain-specific features. By mitigating the effects of domain-specific features, the model trained on the de-domained corpora can effectively learn common expression patterns in different domains. Subsequently, we adapt the learned domain-agnostic features to the target domain through domain adaptation training. We conduct experiments on Chinese dialogue datasets from five different domains and show that AMD$^2$G achieves superior performance compared to both direct training on the target domain corpus and collective training on all five domain corpora. Our work underscores AMD$^2$G as a viable alternative solution for low-resource multi-domain dialogue generation. Code and data associated with our work are available on GitHub repository$^{\text 1}$.
* 17pages,ECML-PKDD