 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHS-SLAM: A Fast and Hybrid Strategy-Based SLAM Approach for Low-Speed Autonomous Driving
May 27, 2025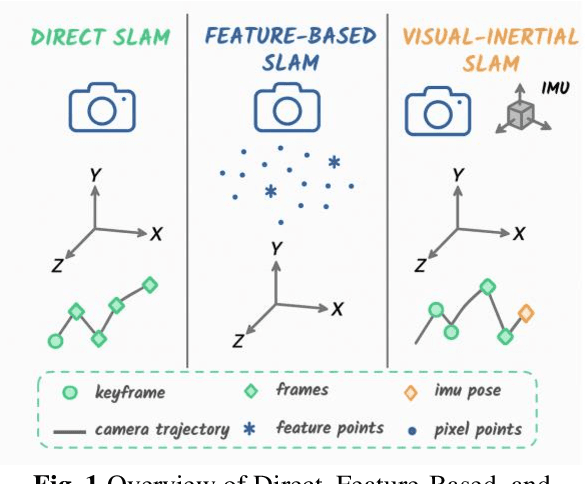


Visual-inertial simultaneous localization and mapping (SLAM) is a key module of robotics and low-speed autonomous vehicles, which is usually limited by the high computation burden for practical applications. To this end, an innovative strategy-based hybrid framework HS-SLAM is proposed to integrate the advantages of direct and feature-based methods for fast computation without decreasing the performance. It first estimates the relative positions of consecutive frames using IMU pose estimation within the tracking thread. Then, it refines these estimates through a multi-layer direct method, which progressively corrects the relative pose from coarse to fine, ultimately achieving accurate corner-based feature matching. This approach serves as an alternative to the conventional constant-velocity tracking model. By selectively bypassing descriptor extraction for non-critical frames, HS-SLAM significantly improves the tracking speed. Experimental evaluations on the EuRoC MAV dataset demonstrate that HS-SLAM achieves higher localization accuracies than ORB-SLAM3 while improving the average tracking efficiency by 15%.
This Time is Different: An Observability Perspective on Time Series Foundation Models
May 20, 2025We introduce Toto, a time series forecasting foundation model with 151 million parameters. Toto uses a modern decoder-only architecture coupled with architectural innovations designed to account for specific challenges found in multivariate observability time series data. Toto's pre-training corpus is a mixture of observability data, open datasets, and synthetic data, and is 4-10$\times$ larger than those of leading time series foundation models. Additionally, we introduce BOOM, a large-scale benchmark consisting of 350 million observations across 2,807 real-world time series. For both Toto and BOOM, we source observability data exclusively from Datadog's own telemetry and internal observability metrics. Extensive evaluations demonstrate that Toto achieves state-of-the-art performance on both BOOM and on established general purpose time series forecasting benchmarks. Toto's model weights, inference code, and evaluation scripts, as well as BOOM's data and evaluation code, are all available as open source under the Apache 2.0 License available at https://huggingface.co/Datadog/Toto-Open-Base-1.0 and https://github.com/DataDog/toto.
Artificial Intelligence in Reactor Physics: Current Status and Future Prospects
Mar 04, 2025Reactor physics is the study of neutron properties, focusing on using models to examine the interactions between neutrons and materials in nuclear reactors. Artificial intelligence (AI) has made significant contributions to reactor physics, e.g., in operational simulations, safety design, real-time monitoring, core management and maintenance. This paper presents a comprehensive review of AI approaches in reactor physics, especially considering the category of Machine Learning (ML), with the aim of describing the application scenarios, frontier topics, unsolved challenges and future research directions. From equation solving and state parameter prediction to nuclear industry applications, this paper provides a step-by-step overview of ML methods applied to steady-state, transient and combustion problems. Most literature works achieve industry-demanded models by enhancing the efficiency of deterministic methods or correcting uncertainty methods, which leads to successful applications. However, research on ML methods in reactor physics is somewhat fragmented, and the ability to generalize models needs to be strengthened. Progress is still possible, especially in addressing theoretical challenges and enhancing industrial applications such as building surrogate models and digital twins.
Toto: Time Series Optimized Transformer for Observability
Jul 11, 2024



This technical report describes the Time Series Optimized Transformer for Observability (Toto), a new state of the art foundation model for time series forecasting developed by Datadog. In addition to advancing the state of the art on generalized time series benchmarks in domains such as electricity and weather, this model is the first general-purpose time series forecasting foundation model to be specifically tuned for observability metrics. Toto was trained on a dataset of one trillion time series data points, the largest among all currently published time series foundation models. Alongside publicly available time series datasets, 75% of the data used to train Toto consists of fully anonymous numerical metric data points from the Datadog platform. In our experiments, Toto outperforms existing time series foundation models on observability data. It does this while also excelling at general-purpose forecasting tasks, achieving state-of-the-art zero-shot performance on multiple open benchmark datasets.
Context Sensing Attention Network for Video-based Person Re-identification
Jul 06, 2022

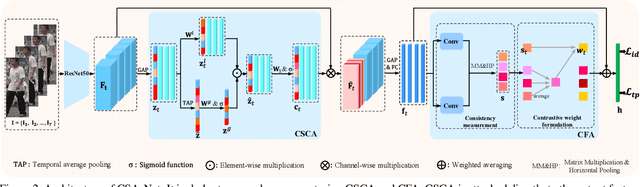
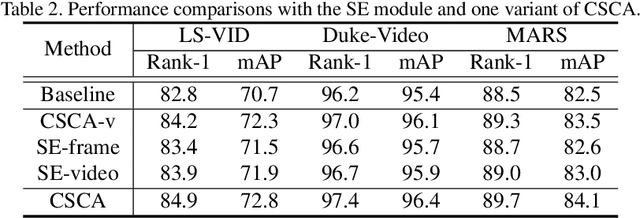
Video-based person re-identification (ReID) is challenging due to the presence of various interferences in video frames. Recent approaches handle this problem using temporal aggregation strategies. In this work, we propose a novel Context Sensing Attention Network (CSA-Net), which improves both the frame feature extraction and temporal aggregation steps. First, we introduce the Context Sensing Channel Attention (CSCA) module, which emphasizes responses from informative channels for each frame. These informative channels are identified with reference not only to each individual frame, but also to the content of the entire sequence. Therefore, CSCA explores both the individuality of each frame and the global context of the sequence. Second, we propose the Contrastive Feature Aggregation (CFA) module, which predicts frame weights for temporal aggregation. Here, the weight for each frame is determined in a contrastive manner: i.e., not only by the quality of each individual frame, but also by the average quality of the other frames in a sequence. Therefore, it effectively promotes the contribution of relatively good frames. Extensive experimental results on four datasets show that CSA-Net consistently achieves state-of-the-art performance.
Batch Coherence-Driven Network for Part-aware Person Re-Identification
Sep 21, 2020



Existing part-aware person re-identification methods typically employ two separate steps: namely, body part detection and part-level feature extraction. However, part detection introduces an additional computational cost and is inherently challenging for low-quality images. Accordingly, in this work, we propose a simple framework named Batch Coherence-Driven Network (BCD-Net) that bypasses body part detection during both the training and testing phases while still learning semantically aligned part features. Our key observation is that the statistics in a batch of images are stable, and therefore that batch-level constraints are robust. First, we introduce a batch coherence-guided channel attention (BCCA) module that highlights the relevant channels for each respective part from the output of a deep backbone model. We investigate channelpart correspondence using a batch of training images, then impose a novel batch-level supervision signal that helps BCCA to identify part-relevant channels. Second, the mean position of a body part is robust and consequently coherent between batches throughout the training process. Accordingly, we introduce a pair of regularization terms based on the semantic consistency between batches. The first term regularizes the high responses of BCD-Net for each part on one batch in order to constrain it within a predefined area, while the second encourages the aggregate of BCD-Nets responses for all parts covering the entire human body. The above constraints guide BCD-Net to learn diverse, complementary, and semantically aligned part-level features. Extensive experimental results demonstrate that BCDNet consistently achieves state-of-the-art performance on four large-scale ReID benchmarks.
Multi-task Learning with Coarse Priors for Robust Part-aware Person Re-identification
Mar 18, 2020Part-level representations are important for robust person re-identification (ReID), but in practice feature quality suffers due to the body part misalignment problem. In this paper, we present a robust, compact, and easy-to-use method called the Multi-task Part-aware Network (MPN), which is designed to extract semantically aligned part-level features from pedestrian images. MPN solves the body part misalignment problem via multi-task learning (MTL) in the training stage. More specifically, it builds one main task (MT) and one auxiliary task (AT) for each body part on the top of the same backbone model. The ATs are equipped with a coarse prior of the body part locations for training images. ATs then transfer the concept of the body parts to the MTs via optimizing the MT parameters to identify part-relevant channels from the backbone model. Concept transfer is accomplished by means of two novel alignment strategies: namely, parameter space alignment via hard parameter sharing and feature space alignment in a class-wise manner. With the aid of the learned high-quality parameters, MTs can independently extract semantically aligned part-level features from relevant channels in the testing stage. MPN has three key advantages: 1) it does not need to conduct body part detection in the inference stage; 2) its model is very compact and efficient for both training and testing; 3) in the training stage, it requires only coarse priors of body part locations, which are easy to obtain. Systematic experiments on four large-scale ReID databases demonstrate that MPN consistently outperforms state-of-the-art approaches by significant margins.
CDPM: Convolutional Deformable Part Models for Person Re-identification
Jun 12, 2019

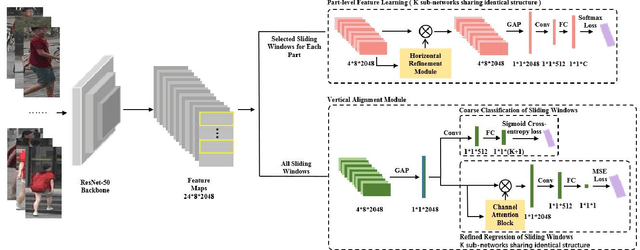
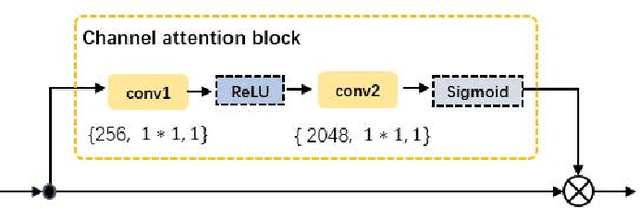
Part-level representations are essential for robust person re-identification. Due to errors in pedestrian detection, there are usually severe mis-alignment problems for body parts, which degrade the quality of part representations. To handle this problem, we propose a novel model named Convolutional Deformable Part Models (CDPM). CDPM works by decoupling the complex part alignment procedure into two easier steps. First, a vertical alignment step detects each part in the vertical direction with the help of a multi-task learning model. Second, a horizontal refinement step based on self-attention suppresses the background information around each detected body part. Since the two steps are performed orthogonally and sequentially, the difficulty of part alignment is significantly reduced. In the testing stage, CDPM is able to accurately align flexible body parts without the need of any outside information. Extensive experimental results justify the effectiveness of CDPM for part alignment. Most impressively, CDPM achieves state-of-the-art performance on three large-scale datasets: Market-1501, DukeMTMC-ReID,and CUHK03.
AVP: Physics-informed Data Generation for Small-data Learning
Feb 05, 2019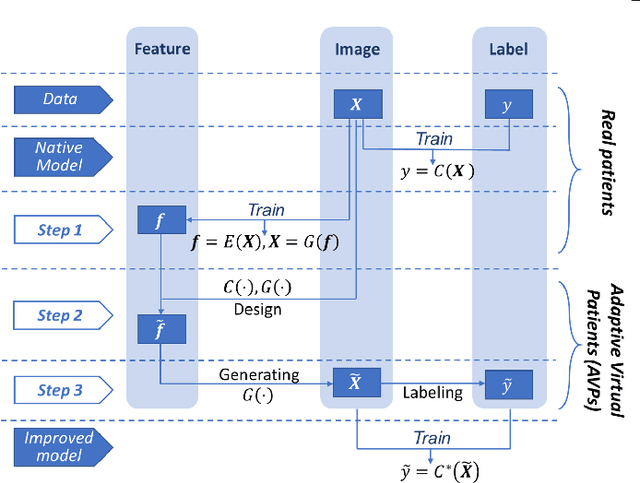

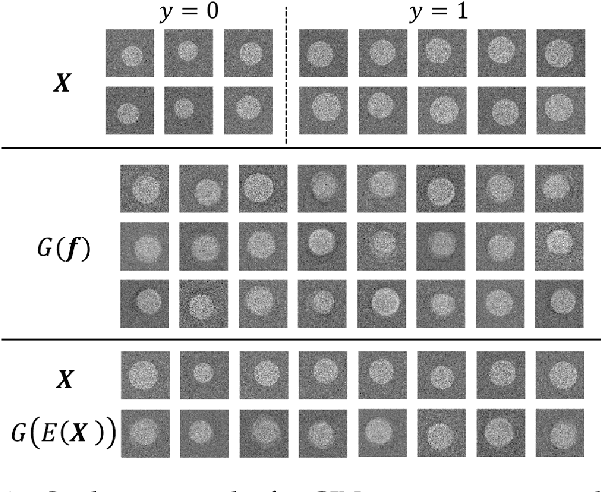
Deep neural networks have achieved great success in multiple learning problems, and attracted increasing attention from the medicine community. In reality, however, the limited availability and high costs of medical data is a major challenge of applying deep neural networks to computer-aided diagnosis and treatment planning. We address this challenge with adaptive virtual patients (AVPs) and the associated physics-informed learning framework. Specifically, the original training dataset is fused with an additional dataset of AVPs, which are generated by a data-driven model and the associated supervision (e.g., labels) is obtained by a physics-based approach. A key novelty in the proposed framework is the bidirectional and uncoupled generative invertible networks (GIN), which can extract pathophysiological features from the training medical image and generate pathophysiologically meaningful virtual patients. In order to mitigate the possibly high labeling cost of physical experiments, a $\mu$-measure design is conducted: this allows the AVPs to not only further explore the uncertain regions, but also balance the label distribution. We then discuss the pathophysiological interpretability of GIN both theoretically and experimentally, and demonstrate the effectiveness of AVPs using a real medical image dataset, in which the proposed AVPs lower the labeling cost by 90% while achieving a 15% improvement in prediction accuracy.
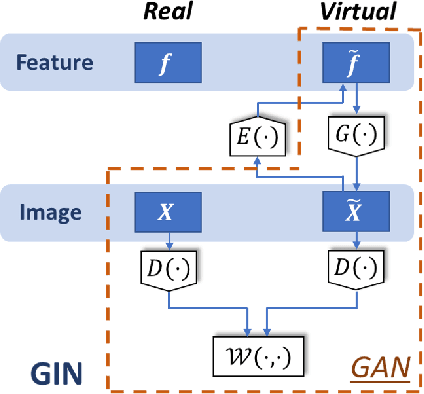
Generative Invertible Networks (GIN): Pathophysiology-Interpretable Feature Mapping and Virtual Patient Generation
Aug 14, 2018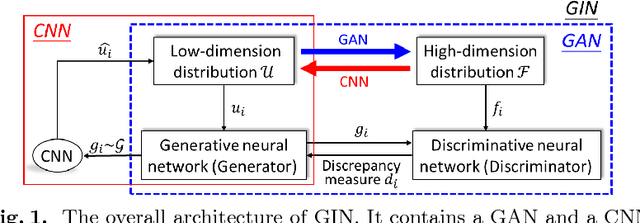

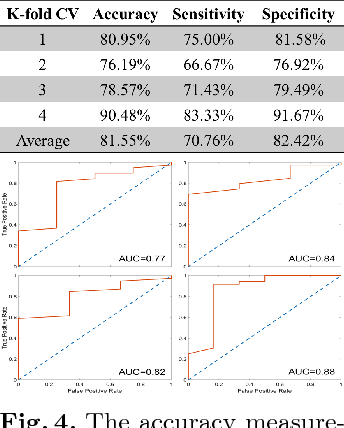
Machine learning methods play increasingly important roles in pre-procedural planning for complex surgeries and interventions. Very often, however, researchers find the historical records of emerging surgical techniques, such as the transcatheter aortic valve replacement (TAVR), are highly scarce in quantity. In this paper, we address this challenge by proposing novel generative invertible networks (GIN) to select features and generate high-quality virtual patients that may potentially serve as an additional data source for machine learning. Combining a convolutional neural network (CNN) and generative adversarial networks (GAN), GIN discovers the pathophysiologic meaning of the feature space. Moreover, a test of predicting the surgical outcome directly using the selected features results in a high accuracy of 81.55%, which suggests little pathophysiologic information has been lost while conducting the feature selection. This demonstrates GIN can generate virtual patients not only visually authentic but also pathophysiologically interpretable.