 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThis Time is Different: An Observability Perspective on Time Series Foundation Models
May 20, 2025We introduce Toto, a time series forecasting foundation model with 151 million parameters. Toto uses a modern decoder-only architecture coupled with architectural innovations designed to account for specific challenges found in multivariate observability time series data. Toto's pre-training corpus is a mixture of observability data, open datasets, and synthetic data, and is 4-10$\times$ larger than those of leading time series foundation models. Additionally, we introduce BOOM, a large-scale benchmark consisting of 350 million observations across 2,807 real-world time series. For both Toto and BOOM, we source observability data exclusively from Datadog's own telemetry and internal observability metrics. Extensive evaluations demonstrate that Toto achieves state-of-the-art performance on both BOOM and on established general purpose time series forecasting benchmarks. Toto's model weights, inference code, and evaluation scripts, as well as BOOM's data and evaluation code, are all available as open source under the Apache 2.0 License available at https://huggingface.co/Datadog/Toto-Open-Base-1.0 and https://github.com/DataDog/toto.
Analyzing Similarity Metrics for Data Selection for Language Model Pretraining
Feb 04, 2025



Similarity between training examples is used to curate pretraining datasets for language models by many methods -- for diversification and to select examples similar to high-quality data. However, similarity is typically measured with off-the-shelf embedding models that are generic or trained for tasks such as retrieval. This paper introduces a framework to analyze the suitability of embedding models specifically for data curation in the language model pretraining setting. We quantify the correlation between similarity in the embedding space to similarity in pretraining loss between different training examples, and how diversifying in the embedding space affects pretraining quality. We analyze a variety of embedding models in our framework, with experiments using the Pile dataset for pretraining a 1.7B parameter decoder-only language model. We find that the embedding models we consider are all useful for pretraining data curation. Moreover, a simple approach of averaging per-token embeddings proves to be surprisingly competitive with more sophisticated embedding models -- likely because the latter are not designed specifically for pretraining data curation. Indeed, we believe our analysis and evaluation framework can serve as a foundation for the design of embedding models that specifically reason about similarity in pretraining datasets.
A Little Help Goes a Long Way: Efficient LLM Training by Leveraging Small LMs
Oct 24, 2024
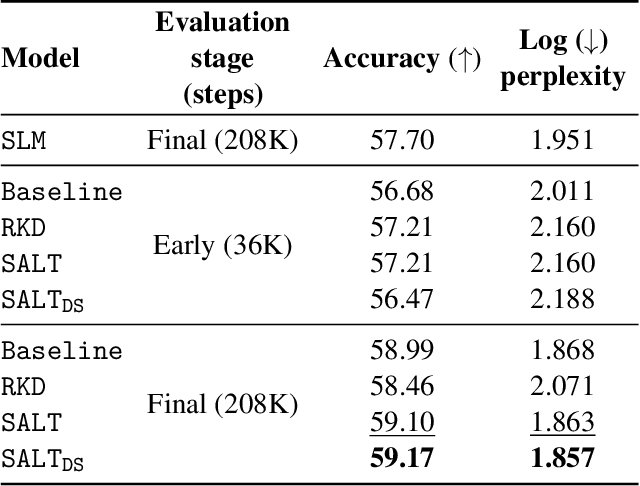

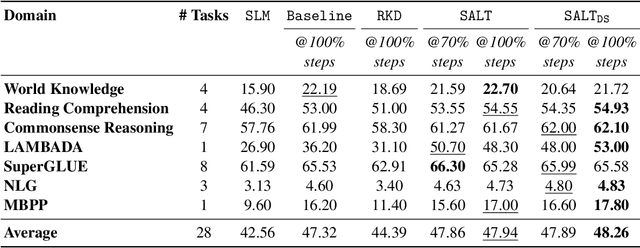
A primary challenge in large language model (LLM) development is their onerous pre-training cost. Typically, such pre-training involves optimizing a self-supervised objective (such as next-token prediction) over a large corpus. This paper explores a promising paradigm to improve LLM pre-training efficiency and quality by suitably leveraging a small language model (SLM). In particular, this paradigm relies on an SLM to both (1) provide soft labels as additional training supervision, and (2) select a small subset of valuable ("informative" and "hard") training examples. Put together, this enables an effective transfer of the SLM's predictive distribution to the LLM, while prioritizing specific regions of the training data distribution. Empirically, this leads to reduced LLM training time compared to standard training, while improving the overall quality. Theoretically, we develop a statistical framework to systematically study the utility of SLMs in enabling efficient training of high-quality LLMs. In particular, our framework characterizes how the SLM's seemingly low-quality supervision can enhance the training of a much more capable LLM. Furthermore, it also highlights the need for an adaptive utilization of such supervision, by striking a balance between the bias and variance introduced by the SLM-provided soft labels. We corroborate our theoretical framework by improving the pre-training of an LLM with 2.8B parameters by utilizing a smaller LM with 1.5B parameters on the Pile dataset.
No more hard prompts: SoftSRV prompting for synthetic data generation
Oct 23, 2024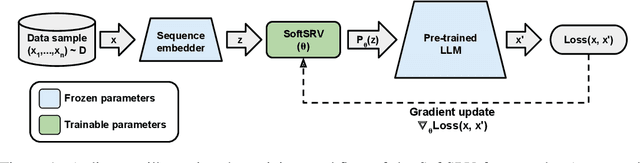
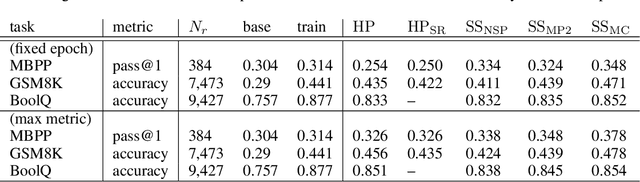
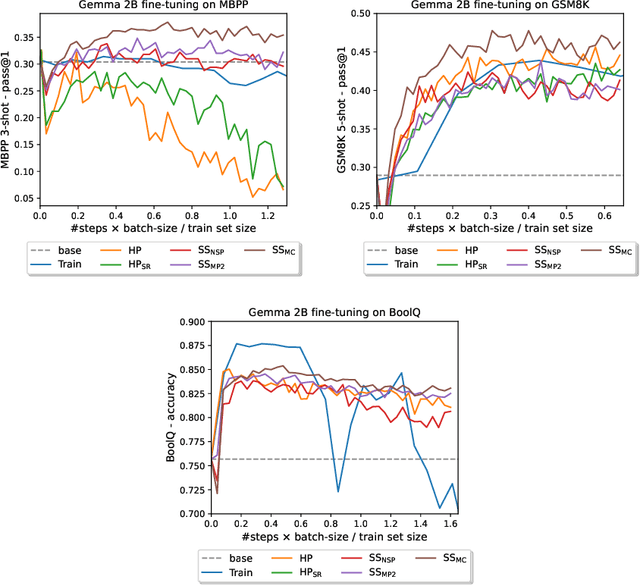
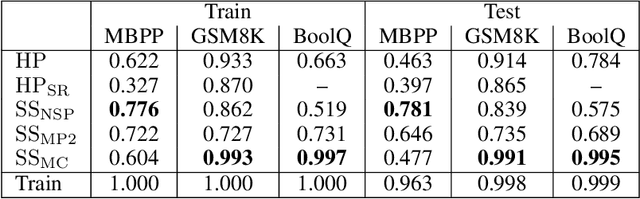
We present a novel soft prompt based framework, SoftSRV, that leverages a frozen pre-trained large language model (LLM) to generate targeted synthetic text sequences. Given a sample from the target distribution, our proposed framework uses data-driven loss minimization to train a parameterized "contextual" soft prompt. This soft prompt is then used to steer the frozen LLM to generate synthetic sequences that are similar to the target distribution. We argue that SoftSRV provides a practical improvement over common hard-prompting approaches that rely on human-curated prompt-templates, which can be idiosyncratic, labor-intensive to craft, and may need to be specialized per domain. We empirically evaluate SoftSRV and hard-prompting baselines by generating synthetic data to fine-tune a small Gemma model on three different domains (coding, math, reasoning). To stress the generality of SoftSRV, we perform these evaluations without any particular specialization of the framework to each domain. We find that SoftSRV significantly improves upon hard-prompting baselines, generating data with superior fine-tuning performance and that better matches the target distribution according to the MAUVE similarity metric.
SpacTor-T5: Pre-training T5 Models with Span Corruption and Replaced Token Detection
Jan 24, 2024Pre-training large language models is known to be extremely resource intensive and often times inefficient, under-utilizing the information encapsulated in the training text sequences. In this paper, we present SpacTor, a new training procedure consisting of (1) a hybrid objective combining span corruption (SC) and token replacement detection (RTD), and (2) a two-stage curriculum that optimizes the hybrid objective over the initial $\tau$ iterations, then transitions to standard SC loss. We show empirically that the effectiveness of the hybrid objective is tied to the two-stage pre-training schedule, and provide extensive analysis on why this is the case. In our experiments with encoder-decoder architectures (T5) on a variety of NLP tasks, SpacTor-T5 yields the same downstream performance as standard SC pre-training, while enabling a 50% reduction in pre-training iterations and 40% reduction in total FLOPs. Alternatively, given the same amount of computing budget, we find that SpacTor results in significantly improved downstream benchmark performance.
DistillSpec: Improving Speculative Decoding via Knowledge Distillation
Oct 12, 2023



Speculative decoding (SD) accelerates large language model inference by employing a faster draft model for generating multiple tokens, which are then verified in parallel by the larger target model, resulting in the text generated according to the target model distribution. However, identifying a compact draft model that is well-aligned with the target model is challenging. To tackle this issue, we propose DistillSpec that uses knowledge distillation to better align the draft model with the target model, before applying SD. DistillSpec makes two key design choices, which we demonstrate via systematic study to be crucial to improving the draft and target alignment: utilizing on-policy data generation from the draft model, and tailoring the divergence function to the task and decoding strategy. Notably, DistillSpec yields impressive 10 - 45% speedups over standard SD on a range of standard benchmarks, using both greedy and non-greedy sampling. Furthermore, we combine DistillSpec with lossy SD to achieve fine-grained control over the latency vs. task performance trade-off. Finally, in practical scenarios with models of varying sizes, first using distillation to boost the performance of the target model and then applying DistillSpec to train a well-aligned draft model can reduce decoding latency by 6-10x with minimal performance drop, compared to standard decoding without distillation.
Leveraging Importance Weights in Subset Selection
Jan 28, 2023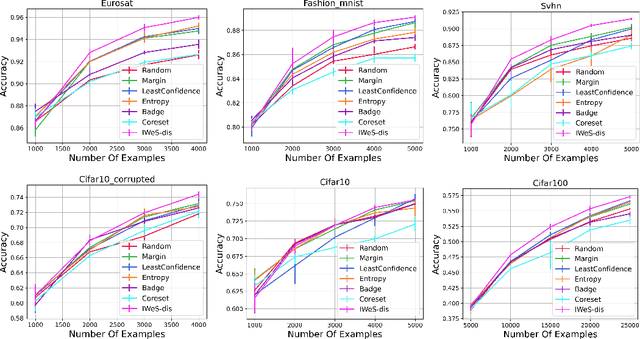
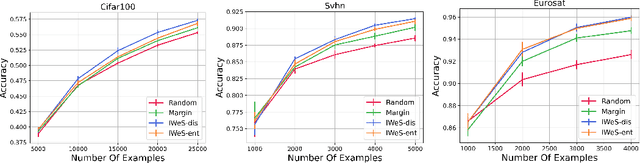
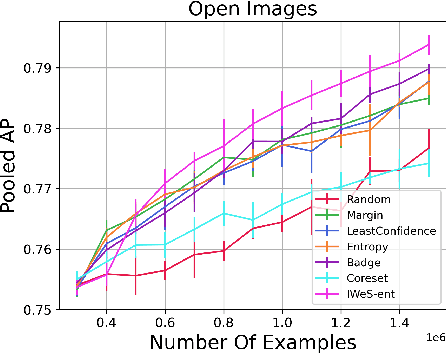
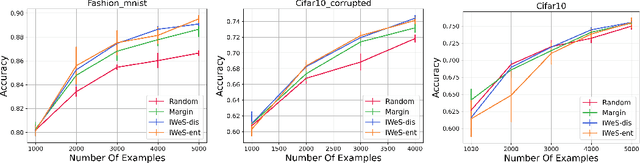
We present a subset selection algorithm designed to work with arbitrary model families in a practical batch setting. In such a setting, an algorithm can sample examples one at a time but, in order to limit overhead costs, is only able to update its state (i.e. further train model weights) once a large enough batch of examples is selected. Our algorithm, IWeS, selects examples by importance sampling where the sampling probability assigned to each example is based on the entropy of models trained on previously selected batches. IWeS admits significant performance improvement compared to other subset selection algorithms for seven publicly available datasets. Additionally, it is competitive in an active learning setting, where the label information is not available at selection time. We also provide an initial theoretical analysis to support our importance weighting approach, proving generalization and sampling rate bounds.
Is margin all you need? An extensive empirical study of active learning on tabular data
Oct 07, 2022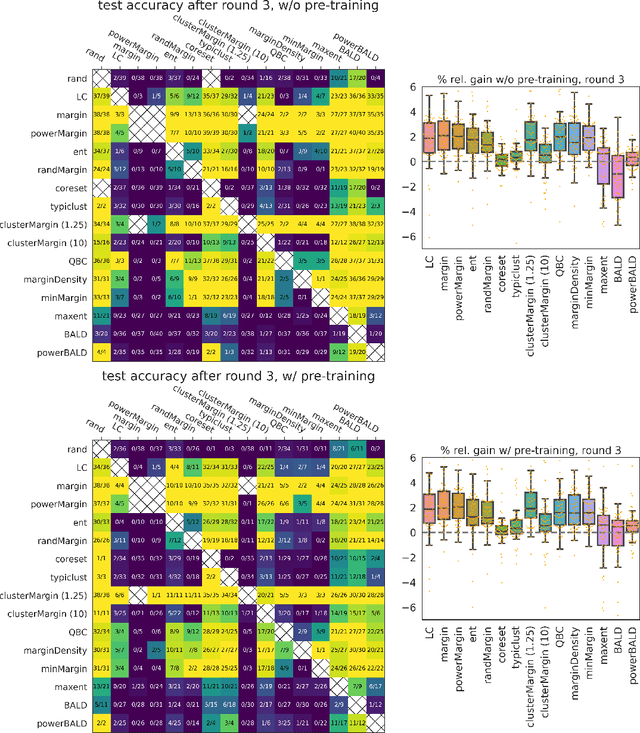
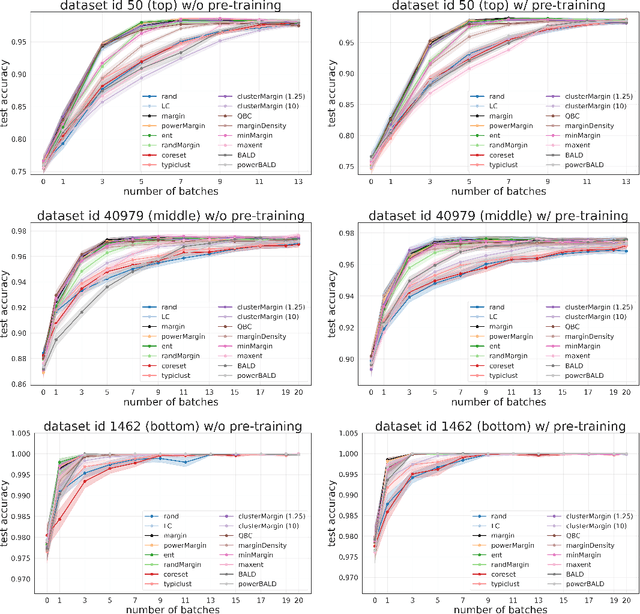
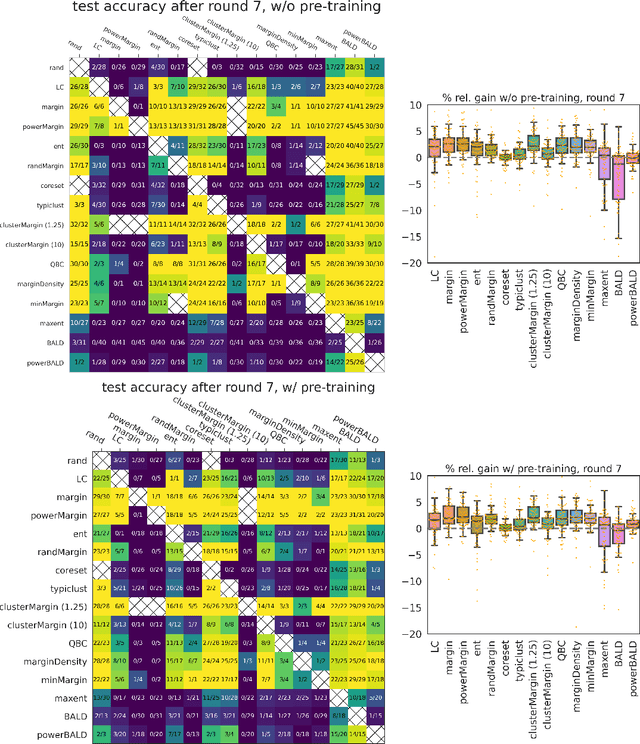
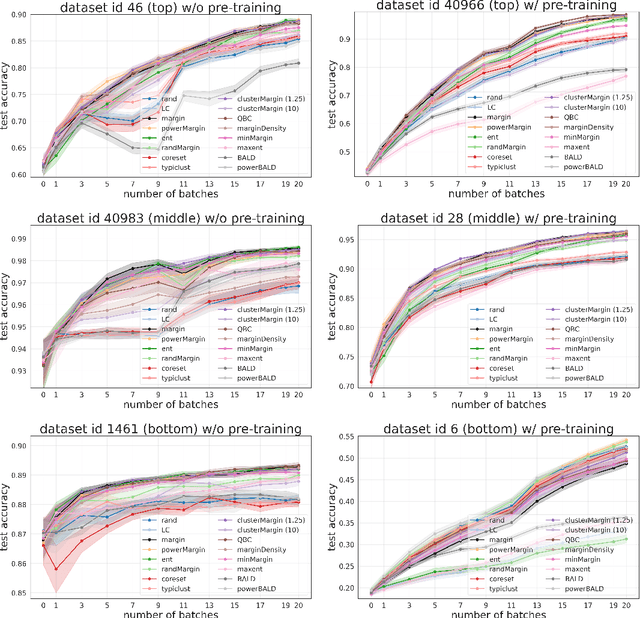
Given a labeled training set and a collection of unlabeled data, the goal of active learning (AL) is to identify the best unlabeled points to label. In this comprehensive study, we analyze the performance of a variety of AL algorithms on deep neural networks trained on 69 real-world tabular classification datasets from the OpenML-CC18 benchmark. We consider different data regimes and the effect of self-supervised model pre-training. Surprisingly, we find that the classical margin sampling technique matches or outperforms all others, including current state-of-art, in a wide range of experimental settings. To researchers, we hope to encourage rigorous benchmarking against margin, and to practitioners facing tabular data labeling constraints that hyper-parameter-free margin may often be all they need.
Batch Active Learning at Scale
Jul 29, 2021
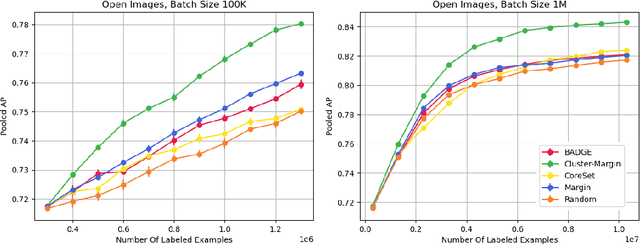
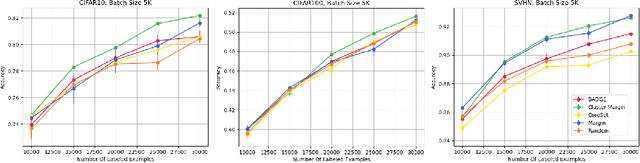
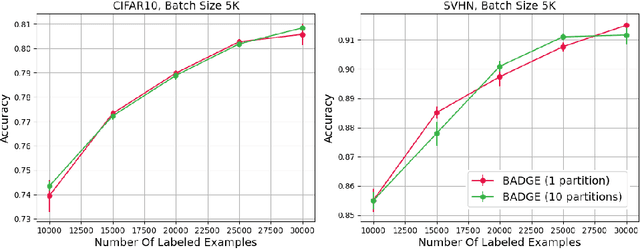
The ability to train complex and highly effective models often requires an abundance of training data, which can easily become a bottleneck in cost, time, and computational resources. Batch active learning, which adaptively issues batched queries to a labeling oracle, is a common approach for addressing this problem. The practical benefits of batch sampling come with the downside of less adaptivity and the risk of sampling redundant examples within a batch -- a risk that grows with the batch size. In this work, we analyze an efficient active learning algorithm, which focuses on the large batch setting. In particular, we show that our sampling method, which combines notions of uncertainty and diversity, easily scales to batch sizes (100K-1M) several orders of magnitude larger than used in previous studies and provides significant improvements in model training efficiency compared to recent baselines. Finally, we provide an initial theoretical analysis, proving label complexity guarantees for a related sampling method, which we show is approximately equivalent to our sampling method in specific settings.
Churn Reduction via Distillation
Jun 04, 2021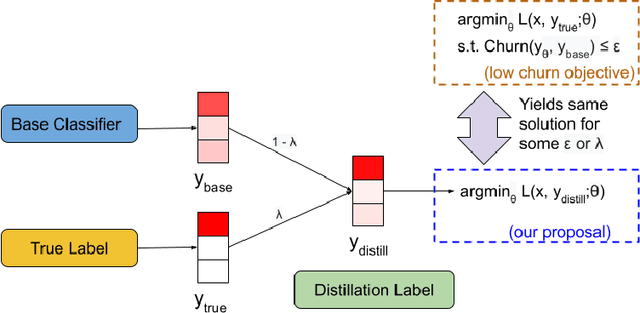

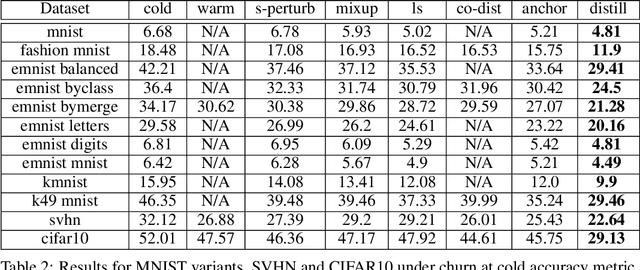
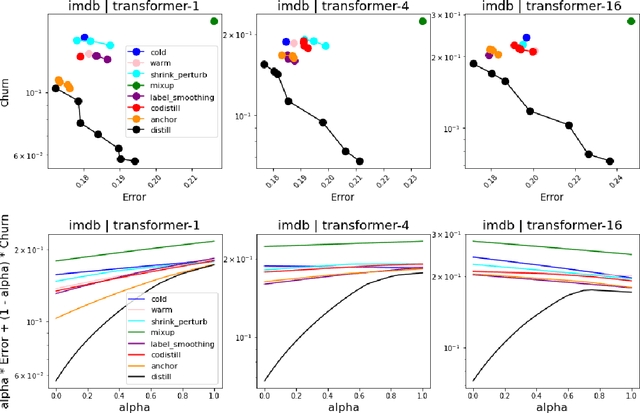
In real-world systems, models are frequently updated as more data becomes available, and in addition to achieving high accuracy, the goal is to also maintain a low difference in predictions compared to the base model (i.e. predictive ``churn''). If model retraining results in vastly different behavior, then it could cause negative effects in downstream systems, especially if this churn can be avoided with limited impact on model accuracy. In this paper, we show an equivalence between training with distillation using the base model as the teacher and training with an explicit constraint on the predictive churn. We then show that distillation performs strongly for low churn training against a number of recent baselines on a wide range of datasets and model architectures, including fully-connected networks, convolutional networks, and transformers.