 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEverybody Prune Now: Structured Pruning of LLMs with only Forward Passes
Feb 09, 2024



Given the generational gap in available hardware between lay practitioners and the most endowed institutions, LLMs are becoming increasingly inaccessible as they grow in size. Whilst many approaches have been proposed to compress LLMs to make their resource consumption manageable, these methods themselves tend to be resource intensive, putting them out of the reach of the very user groups they target. In this work, we explore the problem of structured pruning of LLMs using only forward passes. We seek to empower practitioners to prune models so large that their available hardware has just enough memory to run inference. We develop Bonsai, a gradient-free, perturbative pruning method capable of delivering small, fast, and accurate pruned models. We observe that Bonsai outputs pruned models that (i) outperform those generated by more expensive gradient-based structured pruning methods, and (ii) are twice as fast (with comparable accuracy) as those generated by semi-structured pruning methods requiring comparable resources as Bonsai. We also leverage Bonsai to produce a new sub-2B model using a single A6000 that yields state-of-the-art performance on 4/6 tasks on the Huggingface Open LLM leaderboard.
SpacTor-T5: Pre-training T5 Models with Span Corruption and Replaced Token Detection
Jan 24, 2024Pre-training large language models is known to be extremely resource intensive and often times inefficient, under-utilizing the information encapsulated in the training text sequences. In this paper, we present SpacTor, a new training procedure consisting of (1) a hybrid objective combining span corruption (SC) and token replacement detection (RTD), and (2) a two-stage curriculum that optimizes the hybrid objective over the initial $\tau$ iterations, then transitions to standard SC loss. We show empirically that the effectiveness of the hybrid objective is tied to the two-stage pre-training schedule, and provide extensive analysis on why this is the case. In our experiments with encoder-decoder architectures (T5) on a variety of NLP tasks, SpacTor-T5 yields the same downstream performance as standard SC pre-training, while enabling a 50% reduction in pre-training iterations and 40% reduction in total FLOPs. Alternatively, given the same amount of computing budget, we find that SpacTor results in significantly improved downstream benchmark performance.
DistillSpec: Improving Speculative Decoding via Knowledge Distillation
Oct 12, 2023



Speculative decoding (SD) accelerates large language model inference by employing a faster draft model for generating multiple tokens, which are then verified in parallel by the larger target model, resulting in the text generated according to the target model distribution. However, identifying a compact draft model that is well-aligned with the target model is challenging. To tackle this issue, we propose DistillSpec that uses knowledge distillation to better align the draft model with the target model, before applying SD. DistillSpec makes two key design choices, which we demonstrate via systematic study to be crucial to improving the draft and target alignment: utilizing on-policy data generation from the draft model, and tailoring the divergence function to the task and decoding strategy. Notably, DistillSpec yields impressive 10 - 45% speedups over standard SD on a range of standard benchmarks, using both greedy and non-greedy sampling. Furthermore, we combine DistillSpec with lossy SD to achieve fine-grained control over the latency vs. task performance trade-off. Finally, in practical scenarios with models of varying sizes, first using distillation to boost the performance of the target model and then applying DistillSpec to train a well-aligned draft model can reduce decoding latency by 6-10x with minimal performance drop, compared to standard decoding without distillation.
The Practical Challenges of Active Learning: Lessons Learned from Live Experimentation
Jun 28, 2019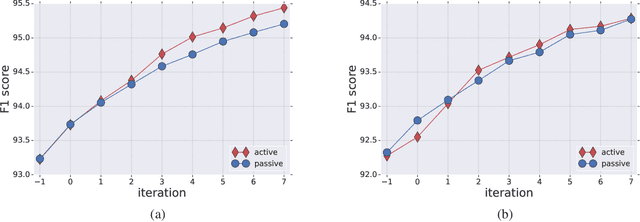
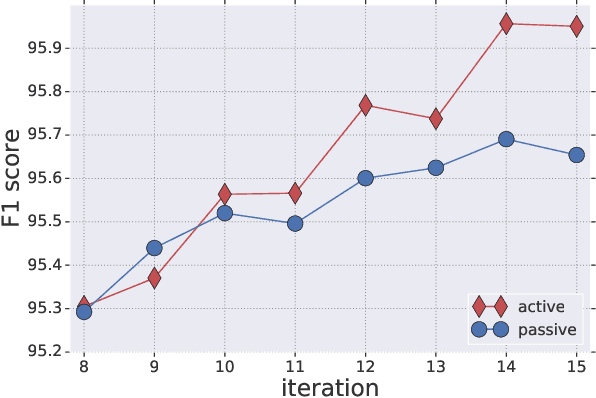
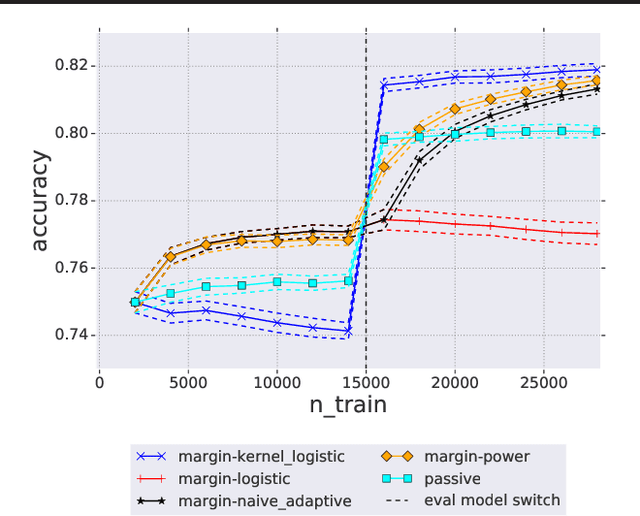
We tested in a live setting the use of active learning for selecting text sentences for human annotations used in training a Thai segmentation machine learning model. In our study, two concurrent annotated samples were constructed, one through random sampling of sentences from a text corpus, and the other through model-based scoring and ranking of sentences from the same corpus. In the course of the experiment, we observed the effect of significant changes to the learning environment which are likely to occur in real-world learning tasks. We describe how our active learning strategy interacted with these events and discuss other practical challenges encountered in using active learning in the live setting.