 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Power of Power Law: Asymmetry Enables Compositional Reasoning
Apr 24, 2026Natural language data follows a power-law distribution, with most knowledge and skills appearing at very low frequency. While a common intuition suggests that reweighting or curating data towards a uniform distribution may help models better learn these long-tail skills, we find a counterintuitive result: across a wide range of compositional reasoning tasks, such as state tracking and multi-step arithmetic, training under power-law distributions consistently outperforms training under uniform distributions. To understand this advantage, we introduce a minimalist skill-composition task and show that learning under a power-law distribution provably requires significantly less training data. Our theoretical analysis reveals that power law sampling induces a beneficial asymmetry that improves the pathological loss landscape, which enables models to first acquire high-frequency skill compositions with low data complexity, which in turn serves as a stepping stone to efficiently learn rare long-tailed skills. Our results offer an alternative perspective on what constitutes an effective data distribution for training models.
SPA: A Simple but Tough-to-Beat Baseline for Knowledge Injection
Mar 23, 2026While large language models (LLMs) are pretrained on massive amounts of data, their knowledge coverage remains incomplete in specialized, data-scarce domains, motivating extensive efforts to study synthetic data generation for knowledge injection. We propose SPA (Scaling Prompt-engineered Augmentation), a simple but tough-to-beat baseline that uses a small set of carefully designed prompts to generate large-scale synthetic data for knowledge injection. Through systematic comparisons, we find that SPA outperforms several strong baselines. Furthermore, we identify two key limitations of prior approaches: (1) while RL-based methods may improve the token efficiency of LLM-based data augmentation at small scale, they suffer from diversity collapse as data scales, leading to diminishing returns; and (2) while multi-stage prompting may outperform simple augmentation methods, their advantages can disappear after careful prompt tuning. Our results suggest that, for knowledge injection, careful prompt design combined with straightforward large-scale augmentation can be surprisingly effective, and we hope SPA can serve as a strong baseline for future studies in this area. Our code is available at https://github.com/Tangkexian/SPA.
Fine-tuning MLLMs Without Forgetting Is Easier Than You Think
Mar 15, 2026The paper demonstrate that simple adjustments of the fine-tuning recipes of multimodal large language models (MLLM) are sufficient to mitigate catastrophic forgetting. On visual question answering, we design a 2x2 experimental framework to assess model performance across in-distribution and out-of-distribution image and text inputs. Our results show that appropriate regularization, such as constraining the number of trainable parameters or adopting a low learning rate, effectively prevents forgetting when dealing with out-of-distribution images. However, we uncover a distinct form of forgetting in settings with in-distribution images and out-of-distribution text. We attribute this forgetting as task-specific overfitting and address this issue by introducing a data-hybrid training strategy that combines datasets and tasks. Finally, we demonstrate that this approach naturally extends to continual learning, outperforming existing methods with complex auxiliary mechanisms. In general, our findings challenge the prevailing assumptions by highlighting the inherent robustness of MLLMs and providing practical guidelines for adapting them while preserving their general capabilities.
Can Small Training Runs Reliably Guide Data Curation? Rethinking Proxy-Model Practice
Dec 30, 2025Data teams at frontier AI companies routinely train small proxy models to make critical decisions about pretraining data recipes for full-scale training runs. However, the community has a limited understanding of whether and when conclusions drawn from small-scale experiments reliably transfer to full-scale model training. In this work, we uncover a subtle yet critical issue in the standard experimental protocol for data recipe assessment: the use of identical small-scale model training configurations across all data recipes in the name of "fair" comparison. We show that the experiment conclusions about data quality can flip with even minor adjustments to training hyperparameters, as the optimal training configuration is inherently data-dependent. Moreover, this fixed-configuration protocol diverges from full-scale model development pipelines, where hyperparameter optimization is a standard step. Consequently, we posit that the objective of data recipe assessment should be to identify the recipe that yields the best performance under data-specific tuning. To mitigate the high cost of hyperparameter tuning, we introduce a simple patch to the evaluation protocol: using reduced learning rates for proxy model training. We show that this approach yields relative performance that strongly correlates with that of fully tuned large-scale LLM pretraining runs. Theoretically, we prove that for random-feature models, this approach preserves the ordering of datasets according to their optimal achievable loss. Empirically, we validate this approach across 23 data recipes covering four critical dimensions of data curation, demonstrating dramatic improvements in the reliability of small-scale experiments.
PCMind-2.1-Kaiyuan-2B Technical Report
Dec 08, 2025The rapid advancement of Large Language Models (LLMs) has resulted in a significant knowledge gap between the open-source community and industry, primarily because the latter relies on closed-source, high-quality data and training recipes. To address this, we introduce PCMind-2.1-Kaiyuan-2B, a fully open-source 2-billion-parameter model focused on improving training efficiency and effectiveness under resource constraints. Our methodology includes three key innovations: a Quantile Data Benchmarking method for systematically comparing heterogeneous open-source datasets and providing insights on data mixing strategies; a Strategic Selective Repetition scheme within a multi-phase paradigm to effectively leverage sparse, high-quality data; and a Multi-Domain Curriculum Training policy that orders samples by quality. Supported by a highly optimized data preprocessing pipeline and architectural modifications for FP16 stability, Kaiyuan-2B achieves performance competitive with state-of-the-art fully open-source models, demonstrating practical and scalable solutions for resource-limited pretraining. We release all assets (including model weights, data, and code) under Apache 2.0 license at https://huggingface.co/thu-pacman/PCMind-2.1-Kaiyuan-2B.
Larger Datasets Can Be Repeated More: A Theoretical Analysis of Multi-Epoch Scaling in Linear Regression
Nov 17, 2025While data scaling laws of large language models (LLMs) have been widely examined in the one-pass regime with massive corpora, their form under limited data and repeated epochs remains largely unexplored. This paper presents a theoretical analysis of how a common workaround, training for multiple epochs on the same dataset, reshapes the data scaling laws in linear regression. Concretely, we ask: to match the performance of training on a dataset of size $N$ for $K$ epochs, how much larger must a dataset be if the model is trained for only one pass? We quantify this using the \textit{effective reuse rate} of the data, $E(K, N)$, which we define as the multiplicative factor by which the dataset must grow under one-pass training to achieve the same test loss as $K$-epoch training. Our analysis precisely characterizes the scaling behavior of $E(K, N)$ for SGD in linear regression under either strong convexity or Zipf-distributed data: (1) When $K$ is small, we prove that $E(K, N) \approx K$, indicating that every new epoch yields a linear gain; (2) As $K$ increases, $E(K, N)$ plateaus at a problem-dependent value that grows with $N$ ($Θ(\log N)$ for the strongly-convex case), implying that larger datasets can be repeated more times before the marginal benefit vanishes. These theoretical findings point out a neglected factor in a recent empirical study (Muennighoff et al. (2023)), which claimed that training LLMs for up to $4$ epochs results in negligible loss differences compared to using fresh data at each step, \textit{i.e.}, $E(K, N) \approx K$ for $K \le 4$ in our notation. Supported by further empirical validation with LLMs, our results reveal that the maximum $K$ value for which $E(K, N) \approx K$ in fact depends on the data size and distribution, and underscore the need to explicitly model both factors in future studies of scaling laws with data reuse.
When Bias Pretends to Be Truth: How Spurious Correlations Undermine Hallucination Detection in LLMs
Nov 10, 2025Despite substantial advances, large language models (LLMs) continue to exhibit hallucinations, generating plausible yet incorrect responses. In this paper, we highlight a critical yet previously underexplored class of hallucinations driven by spurious correlations -- superficial but statistically prominent associations between features (e.g., surnames) and attributes (e.g., nationality) present in the training data. We demonstrate that these spurious correlations induce hallucinations that are confidently generated, immune to model scaling, evade current detection methods, and persist even after refusal fine-tuning. Through systematically controlled synthetic experiments and empirical evaluations on state-of-the-art open-source and proprietary LLMs (including GPT-5), we show that existing hallucination detection methods, such as confidence-based filtering and inner-state probing, fundamentally fail in the presence of spurious correlations. Our theoretical analysis further elucidates why these statistical biases intrinsically undermine confidence-based detection techniques. Our findings thus emphasize the urgent need for new approaches explicitly designed to address hallucinations caused by spurious correlations.
How Far Are We from Optimal Reasoning Efficiency?
Jun 08, 2025Large Reasoning Models (LRMs) demonstrate remarkable problem-solving capabilities through extended Chain-of-Thought (CoT) reasoning but often produce excessively verbose and redundant reasoning traces. This inefficiency incurs high inference costs and limits practical deployment. While existing fine-tuning methods aim to improve reasoning efficiency, assessing their efficiency gains remains challenging due to inconsistent evaluations. In this work, we introduce the reasoning efficiency frontiers, empirical upper bounds derived from fine-tuning base LRMs across diverse approaches and training configurations. Based on these frontiers, we propose the Reasoning Efficiency Gap (REG), a unified metric quantifying deviations of any fine-tuned LRMs from these frontiers. Systematic evaluation on challenging mathematical benchmarks reveals significant gaps in current methods: they either sacrifice accuracy for short length or still remain inefficient under tight token budgets. To reduce the efficiency gap, we propose REO-RL, a class of Reinforcement Learning algorithms that minimizes REG by targeting a sparse set of token budgets. Leveraging numerical integration over strategically selected budgets, REO-RL approximates the full efficiency objective with low error using a small set of token budgets. Through systematic benchmarking, we demonstrate that our efficiency metric, REG, effectively captures the accuracy-length trade-off, with low-REG methods reducing length while maintaining accuracy. Our approach, REO-RL, consistently reduces REG by >=50 across all evaluated LRMs and matching Qwen3-4B/8B efficiency frontiers under a 16K token budget with minimal accuracy loss. Ablation studies confirm the effectiveness of our exponential token budget strategy. Finally, our findings highlight that fine-tuning LRMs to perfectly align with the efficiency frontiers remains an open challenge.
Data Mixing Can Induce Phase Transitions in Knowledge Acquisition
May 23, 2025Large Language Models (LLMs) are typically trained on data mixtures: most data come from web scrapes, while a small portion is curated from high-quality sources with dense domain-specific knowledge. In this paper, we show that when training LLMs on such data mixtures, knowledge acquisition from knowledge-dense datasets, unlike training exclusively on knowledge-dense data (arXiv:2404.05405), does not always follow a smooth scaling law but can exhibit phase transitions with respect to the mixing ratio and model size. Through controlled experiments on a synthetic biography dataset mixed with web-scraped data, we demonstrate that: (1) as we increase the model size to a critical value, the model suddenly transitions from memorizing very few to most of the biographies; (2) below a critical mixing ratio, the model memorizes almost nothing even with extensive training, but beyond this threshold, it rapidly memorizes more biographies. We attribute these phase transitions to a capacity allocation phenomenon: a model with bounded capacity must act like a knapsack problem solver to minimize the overall test loss, and the optimal allocation across datasets can change discontinuously as the model size or mixing ratio varies. We formalize this intuition in an information-theoretic framework and reveal that these phase transitions are predictable, with the critical mixing ratio following a power-law relationship with the model size. Our findings highlight a concrete case where a good mixing recipe for large models may not be optimal for small models, and vice versa.
LEGO-Puzzles: How Good Are MLLMs at Multi-Step Spatial Reasoning?
Mar 25, 2025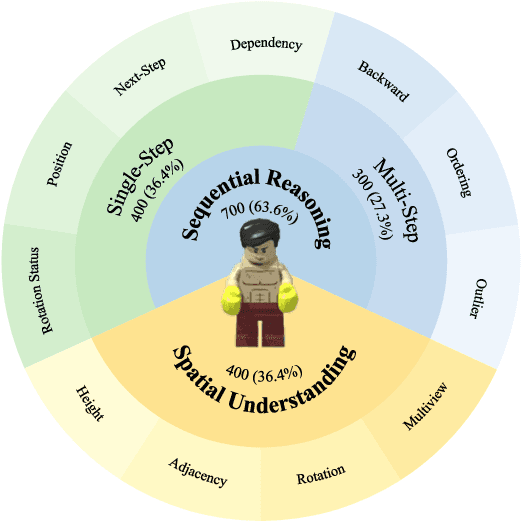
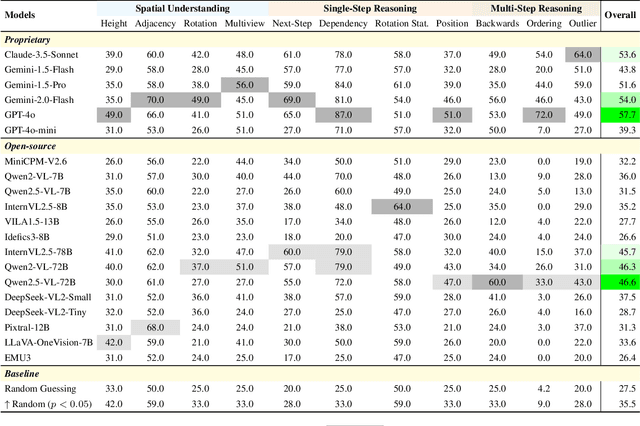
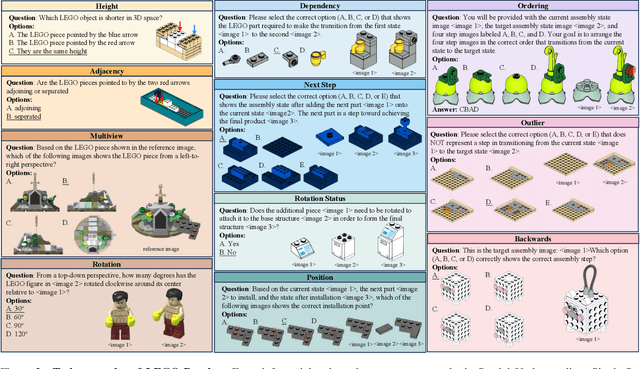
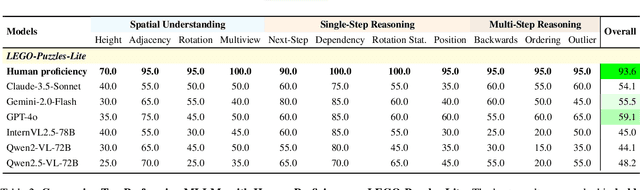
Multi-step spatial reasoning entails understanding and reasoning about spatial relationships across multiple sequential steps, which is crucial for tackling complex real-world applications, such as robotic manipulation, autonomous navigation, and automated assembly. To assess how well current Multimodal Large Language Models (MLLMs) have acquired this fundamental capability, we introduce \textbf{LEGO-Puzzles}, a scalable benchmark designed to evaluate both \textbf{spatial understanding} and \textbf{sequential reasoning} in MLLMs through LEGO-based tasks. LEGO-Puzzles consists of 1,100 carefully curated visual question-answering (VQA) samples spanning 11 distinct tasks, ranging from basic spatial understanding to complex multi-step reasoning. Based on LEGO-Puzzles, we conduct a comprehensive evaluation of state-of-the-art MLLMs and uncover significant limitations in their spatial reasoning capabilities: even the most powerful MLLMs can answer only about half of the test cases, whereas human participants achieve over 90\% accuracy. In addition to VQA tasks, we evaluate MLLMs' abilities to generate LEGO images following assembly illustrations. Our experiments show that only Gemini-2.0-Flash and GPT-4o exhibit a limited ability to follow these instructions, while other MLLMs either replicate the input image or generate completely irrelevant outputs. Overall, LEGO-Puzzles exposes critical deficiencies in existing MLLMs' spatial understanding and sequential reasoning capabilities, and underscores the need for further advancements in multimodal spatial reasoning.