 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThickening-to-Thinning: Reward Shaping via Human-Inspired Learning Dynamics for LLM Reasoning
Feb 04, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a promising paradigm for enhancing reasoning in Large Language Models (LLMs). However, it frequently encounters challenges such as entropy collapse, excessive verbosity, and insufficient exploration for hard problems. Crucially, existing reward schemes fail to distinguish between the need for extensive search during problem-solving and the efficiency required for mastered knowledge. In this work, we introduce T2T(Thickening-to-Thinning), a dynamic reward framework inspired by human learning processes. Specifically, it implements a dual-phase mechanism: (1) On incorrect attempts, T2T incentivizes "thickening" (longer trajectories) to broaden the search space and explore novel solution paths; (2) Upon achieving correctness, it shifts to "thinning", imposing length penalties to discourage redundancy, thereby fostering model confidence and crystallizing reasoning capabilities. Extensive experiments on mathematical benchmarks (MATH-500, AIME, AMC) across Qwen-series and Deepseek models demonstrate that T2T significantly outperforms standard GRPO and recent baselines, achieving superior performance.
Towards Understanding Text Hallucination of Diffusion Models via Local Generation Bias
Mar 05, 2025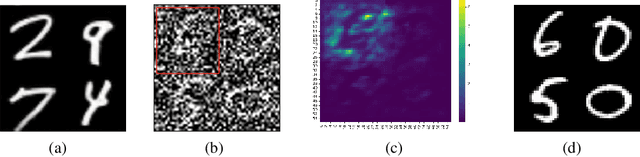
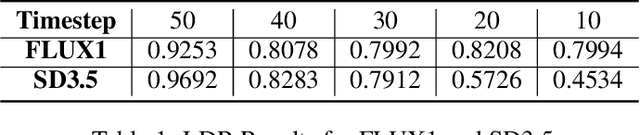

Score-based diffusion models have achieved incredible performance in generating realistic images, audio, and video data. While these models produce high-quality samples with impressive details, they often introduce unrealistic artifacts, such as distorted fingers or hallucinated texts with no meaning. This paper focuses on textual hallucinations, where diffusion models correctly generate individual symbols but assemble them in a nonsensical manner. Through experimental probing, we consistently observe that such phenomenon is attributed it to the network's local generation bias. Denoising networks tend to produce outputs that rely heavily on highly correlated local regions, particularly when different dimensions of the data distribution are nearly pairwise independent. This behavior leads to a generation process that decomposes the global distribution into separate, independent distributions for each symbol, ultimately failing to capture the global structure, including underlying grammar. Intriguingly, this bias persists across various denoising network architectures including MLP and transformers which have the structure to model global dependency. These findings also provide insights into understanding other types of hallucinations, extending beyond text, as a result of implicit biases in the denoising models. Additionally, we theoretically analyze the training dynamics for a specific case involving a two-layer MLP learning parity points on a hypercube, offering an explanation of its underlying mechanism.