 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Far Are We from Optimal Reasoning Efficiency?
Jun 08, 2025Large Reasoning Models (LRMs) demonstrate remarkable problem-solving capabilities through extended Chain-of-Thought (CoT) reasoning but often produce excessively verbose and redundant reasoning traces. This inefficiency incurs high inference costs and limits practical deployment. While existing fine-tuning methods aim to improve reasoning efficiency, assessing their efficiency gains remains challenging due to inconsistent evaluations. In this work, we introduce the reasoning efficiency frontiers, empirical upper bounds derived from fine-tuning base LRMs across diverse approaches and training configurations. Based on these frontiers, we propose the Reasoning Efficiency Gap (REG), a unified metric quantifying deviations of any fine-tuned LRMs from these frontiers. Systematic evaluation on challenging mathematical benchmarks reveals significant gaps in current methods: they either sacrifice accuracy for short length or still remain inefficient under tight token budgets. To reduce the efficiency gap, we propose REO-RL, a class of Reinforcement Learning algorithms that minimizes REG by targeting a sparse set of token budgets. Leveraging numerical integration over strategically selected budgets, REO-RL approximates the full efficiency objective with low error using a small set of token budgets. Through systematic benchmarking, we demonstrate that our efficiency metric, REG, effectively captures the accuracy-length trade-off, with low-REG methods reducing length while maintaining accuracy. Our approach, REO-RL, consistently reduces REG by >=50 across all evaluated LRMs and matching Qwen3-4B/8B efficiency frontiers under a 16K token budget with minimal accuracy loss. Ablation studies confirm the effectiveness of our exponential token budget strategy. Finally, our findings highlight that fine-tuning LRMs to perfectly align with the efficiency frontiers remains an open challenge.
AED: Automatic Discovery of Effective and Diverse Vulnerabilities for Autonomous Driving Policy with Large Language Models
Mar 24, 2025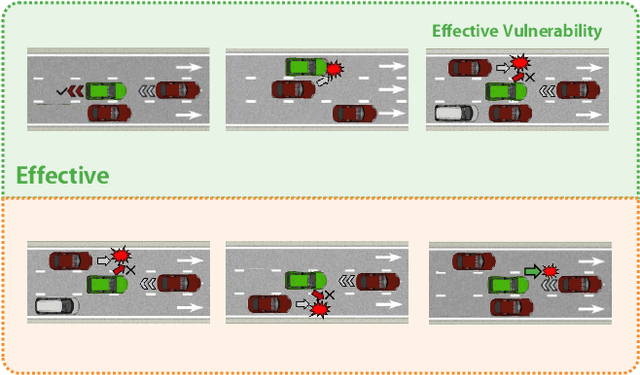


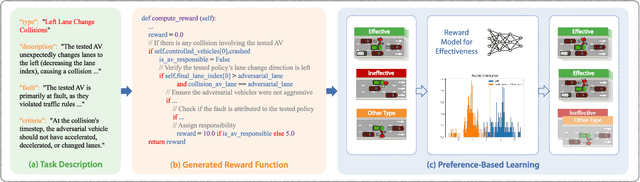
Assessing the safety of autonomous driving policy is of great importance, and reinforcement learning (RL) has emerged as a powerful method for discovering critical vulnerabilities in driving policies. However, existing RL-based approaches often struggle to identify vulnerabilities that are both effective-meaning the autonomous vehicle is genuinely responsible for the accidents-and diverse-meaning they span various failure types. To address these challenges, we propose AED, a framework that uses large language models (LLMs) to automatically discover effective and diverse vulnerabilities in autonomous driving policies. We first utilize an LLM to automatically design reward functions for RL training. Then we let the LLM consider a diverse set of accident types and train adversarial policies for different accident types in parallel. Finally, we use preference-based learning to filter ineffective accidents and enhance the effectiveness of each vulnerability. Experiments across multiple simulated traffic scenarios and tested policies show that AED uncovers a broader range of vulnerabilities and achieves higher attack success rates compared with expert-designed rewards, thereby reducing the need for manual reward engineering and improving the diversity and effectiveness of vulnerability discovery.
Few-shot In-Context Preference Learning Using Large Language Models
Oct 22, 2024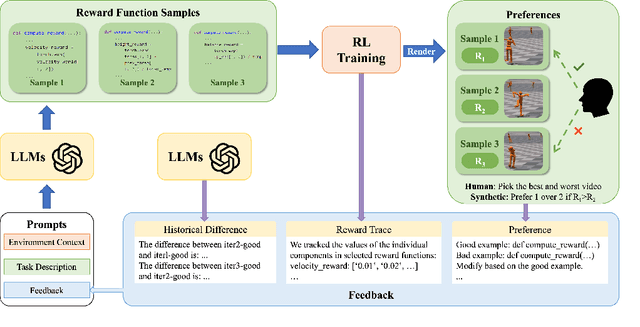

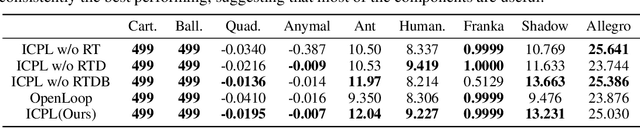
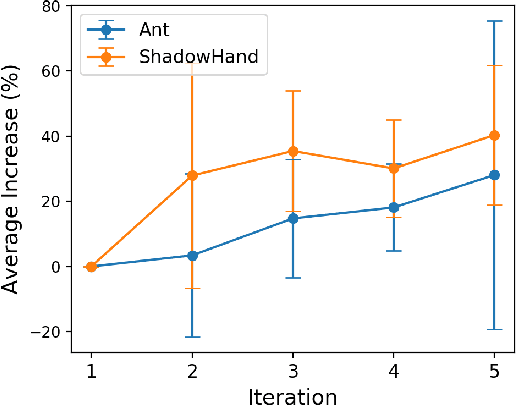
Designing reward functions is a core component of reinforcement learning but can be challenging for truly complex behavior. Reinforcement Learning from Human Feedback (RLHF) has been used to alleviate this challenge by replacing a hand-coded reward function with a reward function learned from preferences. However, it can be exceedingly inefficient to learn these rewards as they are often learned tabula rasa. We investigate whether Large Language Models (LLMs) can reduce this query inefficiency by converting an iterative series of human preferences into code representing the rewards. We propose In-Context Preference Learning (ICPL), a method that uses the grounding of an LLM to accelerate learning reward functions from preferences. ICPL takes the environment context and task description, synthesizes a set of reward functions, and then repeatedly updates the reward functions using human rankings of videos of the resultant policies. Using synthetic preferences, we demonstrate that ICPL is orders of magnitude more efficient than RLHF and is even competitive with methods that use ground-truth reward functions instead of preferences. Finally, we perform a series of human preference-learning trials and observe that ICPL extends beyond synthetic settings and can work effectively with humans-in-the-loop. Additional information and videos are provided at https://sites.google.com/view/few-shot-icpl/home.