 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-shot In-Context Preference Learning Using Large Language Models
Oct 22, 2024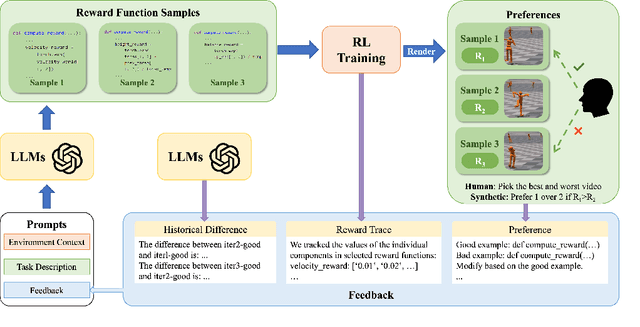

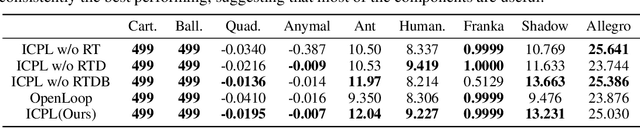
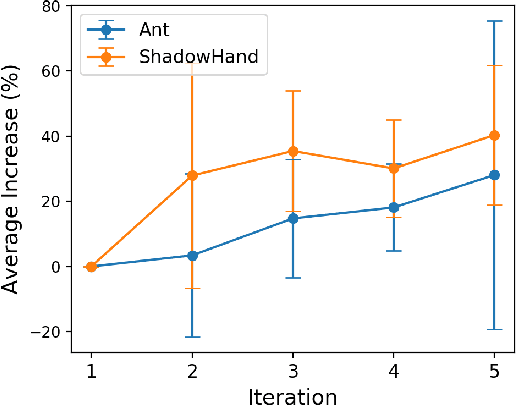
Designing reward functions is a core component of reinforcement learning but can be challenging for truly complex behavior. Reinforcement Learning from Human Feedback (RLHF) has been used to alleviate this challenge by replacing a hand-coded reward function with a reward function learned from preferences. However, it can be exceedingly inefficient to learn these rewards as they are often learned tabula rasa. We investigate whether Large Language Models (LLMs) can reduce this query inefficiency by converting an iterative series of human preferences into code representing the rewards. We propose In-Context Preference Learning (ICPL), a method that uses the grounding of an LLM to accelerate learning reward functions from preferences. ICPL takes the environment context and task description, synthesizes a set of reward functions, and then repeatedly updates the reward functions using human rankings of videos of the resultant policies. Using synthetic preferences, we demonstrate that ICPL is orders of magnitude more efficient than RLHF and is even competitive with methods that use ground-truth reward functions instead of preferences. Finally, we perform a series of human preference-learning trials and observe that ICPL extends beyond synthetic settings and can work effectively with humans-in-the-loop. Additional information and videos are provided at https://sites.google.com/view/few-shot-icpl/home.
MASP: Scalable GNN-based Planning for Multi-Agent Navigation
Dec 05, 2023



We investigate the problem of decentralized multi-agent navigation tasks, where multiple agents need to reach initially unassigned targets in a limited time. Classical planning-based methods suffer from expensive computation overhead at each step and offer limited expressiveness for complex cooperation strategies. In contrast, reinforcement learning (RL) has recently become a popular paradigm for addressing this issue. However, RL struggles with low data efficiency and cooperation when directly exploring (nearly) optimal policies in the large search space, especially with an increased agent number (e.g., 10+ agents) or in complex environments (e.g., 3D simulators). In this paper, we propose Multi-Agent Scalable GNN-based P lanner (MASP), a goal-conditioned hierarchical planner for navigation tasks with a substantial number of agents. MASP adopts a hierarchical framework to divide a large search space into multiple smaller spaces, thereby reducing the space complexity and accelerating training convergence. We also leverage graph neural networks (GNN) to model the interaction between agents and goals, improving goal achievement. Besides, to enhance generalization capabilities in scenarios with unseen team sizes, we divide agents into multiple groups, each with a previously trained number of agents. The results demonstrate that MASP outperforms classical planning-based competitors and RL baselines, achieving a nearly 100% success rate with minimal training data in both multi-agent particle environments (MPE) with 50 agents and a quadrotor 3-dimensional environment (OmniDrones) with 20 agents. Furthermore, the learned policy showcases zero-shot generalization across unseen team sizes.
Deep learning for smart fish farming: applications, opportunities and challenges
Apr 06, 2020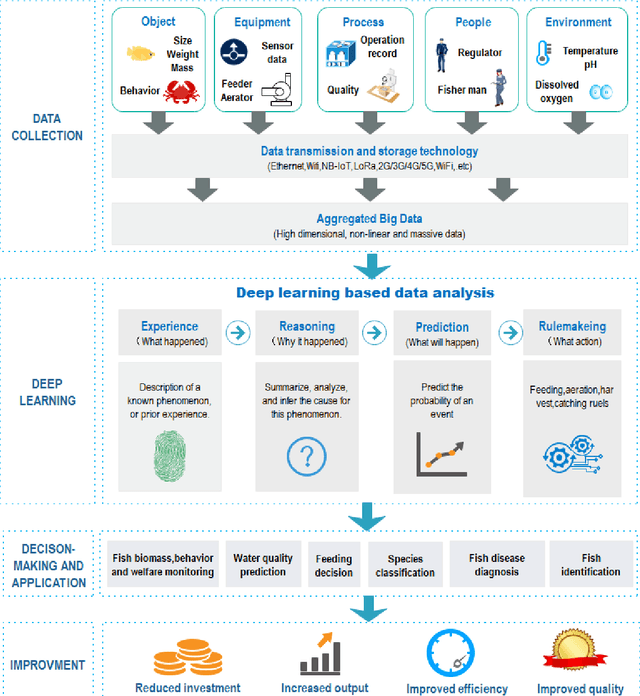

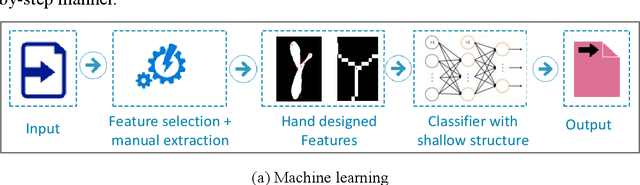

With the rapid emergence of deep learning (DL) technology, it has been successfully used in various fields including aquaculture. This change can create new opportunities and a series of challenges for information and data processing in smart fish farming. This paper focuses on the applications of DL in aquaculture, including live fish identification, species classification, behavioral analysis, feeding decision-making, size or biomass estimation, water quality prediction. In addition, the technical details of DL methods applied to smart fish farming are also analyzed, including data, algorithms, computing power, and performance. The results of this review show that the most significant contribution of DL is the ability to automatically extract features. However, challenges still exist; DL is still in an era of weak artificial intelligence. A large number of labeled data are needed for training, which has become a bottleneck restricting further DL applications in aquaculture. Nevertheless, DL still offers breakthroughs in the handling of complex data in aquaculture. In brief, our purpose is to provide researchers and practitioners with a better understanding of the current state of the art of DL in aquaculture, which can provide strong support for the implementation of smart fish farming.