 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMRareBench: A Rare-Disease Multimodal and Multi-Image Medical Benchmark
Apr 12, 2026Multimodal large language models (MLLMs) have advanced clinical tasks for common conditions, but their performance on rare diseases remains largely untested. In rare-disease scenarios, clinicians often lack prior clinical knowledge, forcing them to rely strictly on case-level evidence for clinical judgments. Existing benchmarks predominantly evaluate common-condition, single-image settings, leaving multimodal and multi-image evidence integration under rare-disease data scarcity systematically unevaluated. We introduce MMRareBench, to our knowledge the first rare-disease benchmark jointly evaluating multimodal and multi-image clinical capability across four workflow-aligned tracks: diagnosis, treatment planning, cross-image evidence alignment, and examination suggestion. The benchmark comprises 1,756 question-answer pairs with 7,958 associated medical images curated from PMC case reports, with Orphanet-anchored ontology alignment, track-specific leakage control, evidence-grounded annotations, and a two-level evaluation protocol. A systematic evaluation of 23 MLLMs reveals fragmented capability profiles and universally low treatment-planning performance, with medical-domain models trailing general-purpose MLLMs substantially on multi-image tracks despite competitive diagnostic scores. These patterns are consistent with a capacity dilution effect: medical fine-tuning can narrow the diagnostic gap but may erode the compositional multi-image capability that rare-disease evidence integration demands.
Project Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development
Mar 29, 2026Foundation models have demonstrated remarkable success across diverse domains and tasks, primarily due to the thrive of large-scale, diverse, and high-quality datasets. However, in the field of medical imaging, the curation and assembling of such medical datasets are highly challenging due to the reliance on clinical expertise and strict ethical and privacy constraints, resulting in a scarcity of large-scale unified medical datasets and hindering the development of powerful medical foundation models. In this work, we present the largest survey to date of medical image datasets, covering over 1,000 open-access datasets with a systematic catalog of their modalities, tasks, anatomies, annotations, limitations, and potential for integration. Our analysis exposes a landscape that is modest in scale, fragmented across narrowly scoped tasks, and unevenly distributed across organs and modalities, which in turn limits the utility of existing medical image datasets for developing versatile and robust medical foundation models. To turn fragmentation into scale, we propose a metadata-driven fusion paradigm (MDFP) that integrates public datasets with shared modalities or tasks, thereby transforming multiple small data silos into larger, more coherent resources. Building on MDFP, we release an interactive discovery portal that enables end-to-end, automated medical image dataset integration, and compile all surveyed datasets into a unified, structured table that clearly summarizes their key characteristics and provides reference links, offering the community an accessible and comprehensive repository. By charting the current terrain and offering a principled path to dataset consolidation, our survey provides a practical roadmap for scaling medical imaging corpora, supporting faster data discovery, more principled dataset creation, and more capable medical foundation models.
RLinf-USER: A Unified and Extensible System for Real-World Online Policy Learning in Embodied AI
Feb 08, 2026Online policy learning directly in the physical world is a promising yet challenging direction for embodied intelligence. Unlike simulation, real-world systems cannot be arbitrarily accelerated, cheaply reset, or massively replicated, which makes scalable data collection, heterogeneous deployment, and long-horizon effective training difficult. These challenges suggest that real-world policy learning is not only an algorithmic issue but fundamentally a systems problem. We present USER, a Unified and extensible SystEm for Real-world online policy learning. USER treats physical robots as first-class hardware resources alongside GPUs through a unified hardware abstraction layer, enabling automatic discovery, management, and scheduling of heterogeneous robots. To address cloud-edge communication, USER introduces an adaptive communication plane with tunneling-based networking, distributed data channels for traffic localization, and streaming-multiprocessor-aware weight synchronization to regulate GPU-side overhead. On top of this infrastructure, USER organizes learning as a fully asynchronous framework with a persistent, cache-aware buffer, enabling efficient long-horizon experiments with robust crash recovery and reuse of historical data. In addition, USER provides extensible abstractions for rewards, algorithms, and policies, supporting online imitation or reinforcement learning of CNN/MLP, generative policies, and large vision-language-action (VLA) models within a unified pipeline. Results in both simulation and the real world show that USER enables multi-robot coordination, heterogeneous manipulators, edge-cloud collaboration with large models, and long-running asynchronous training, offering a unified and extensible systems foundation for real-world online policy learning.
Automatic Reward Shaping from Multi-Objective Human Heuristics
Dec 17, 2025Designing effective reward functions remains a central challenge in reinforcement learning, especially in multi-objective environments. In this work, we propose Multi-Objective Reward Shaping with Exploration (MORSE), a general framework that automatically combines multiple human-designed heuristic rewards into a unified reward function. MORSE formulates the shaping process as a bi-level optimization problem: the inner loop trains a policy to maximize the current shaped reward, while the outer loop updates the reward function to optimize task performance. To encourage exploration in the reward space and avoid suboptimal local minima, MORSE introduces stochasticity into the shaping process, injecting noise guided by task performance and the prediction error of a fixed, randomly initialized neural network. Experimental results in MuJoCo and Isaac Sim environments show that MORSE effectively balances multiple objectives across various robotic tasks, achieving task performance comparable to those obtained with manually tuned reward functions.
A Survey of Scientific Large Language Models: From Data Foundations to Agent Frontiers
Aug 28, 2025



Scientific Large Language Models (Sci-LLMs) are transforming how knowledge is represented, integrated, and applied in scientific research, yet their progress is shaped by the complex nature of scientific data. This survey presents a comprehensive, data-centric synthesis that reframes the development of Sci-LLMs as a co-evolution between models and their underlying data substrate. We formulate a unified taxonomy of scientific data and a hierarchical model of scientific knowledge, emphasizing the multimodal, cross-scale, and domain-specific challenges that differentiate scientific corpora from general natural language processing datasets. We systematically review recent Sci-LLMs, from general-purpose foundations to specialized models across diverse scientific disciplines, alongside an extensive analysis of over 270 pre-/post-training datasets, showing why Sci-LLMs pose distinct demands -- heterogeneous, multi-scale, uncertainty-laden corpora that require representations preserving domain invariance and enabling cross-modal reasoning. On evaluation, we examine over 190 benchmark datasets and trace a shift from static exams toward process- and discovery-oriented assessments with advanced evaluation protocols. These data-centric analyses highlight persistent issues in scientific data development and discuss emerging solutions involving semi-automated annotation pipelines and expert validation. Finally, we outline a paradigm shift toward closed-loop systems where autonomous agents based on Sci-LLMs actively experiment, validate, and contribute to a living, evolving knowledge base. Collectively, this work provides a roadmap for building trustworthy, continually evolving artificial intelligence (AI) systems that function as a true partner in accelerating scientific discovery.
Mastering Multi-Drone Volleyball through Hierarchical Co-Self-Play Reinforcement Learning
May 07, 2025In this paper, we tackle the problem of learning to play 3v3 multi-drone volleyball, a new embodied competitive task that requires both high-level strategic coordination and low-level agile control. The task is turn-based, multi-agent, and physically grounded, posing significant challenges due to its long-horizon dependencies, tight inter-agent coupling, and the underactuated dynamics of quadrotors. To address this, we propose Hierarchical Co-Self-Play (HCSP), a hierarchical reinforcement learning framework that separates centralized high-level strategic decision-making from decentralized low-level motion control. We design a three-stage population-based training pipeline to enable both strategy and skill to emerge from scratch without expert demonstrations: (I) training diverse low-level skills, (II) learning high-level strategy via self-play with fixed low-level controllers, and (III) joint fine-tuning through co-self-play. Experiments show that HCSP achieves superior performance, outperforming non-hierarchical self-play and rule-based hierarchical baselines with an average 82.9\% win rate and a 71.5\% win rate against the two-stage variant. Moreover, co-self-play leads to emergent team behaviors such as role switching and coordinated formations, demonstrating the effectiveness of our hierarchical design and training scheme.
Hysteresis-Aware Neural Network Modeling and Whole-Body Reinforcement Learning Control of Soft Robots
Apr 18, 2025Soft robots exhibit inherent compliance and safety, which makes them particularly suitable for applications requiring direct physical interaction with humans, such as surgical procedures. However, their nonlinear and hysteretic behavior, resulting from the properties of soft materials, presents substantial challenges for accurate modeling and control. In this study, we present a soft robotic system designed for surgical applications and propose a hysteresis-aware whole-body neural network model that accurately captures and predicts the soft robot's whole-body motion, including its hysteretic behavior. Building upon the high-precision dynamic model, we construct a highly parallel simulation environment for soft robot control and apply an on-policy reinforcement learning algorithm to efficiently train whole-body motion control strategies. Based on the trained control policy, we developed a soft robotic system for surgical applications and validated it through phantom-based laser ablation experiments in a physical environment. The results demonstrate that the hysteresis-aware modeling reduces the Mean Squared Error (MSE) by 84.95 percent compared to traditional modeling methods. The deployed control algorithm achieved a trajectory tracking error ranging from 0.126 to 0.250 mm on the real soft robot, highlighting its precision in real-world conditions. The proposed method showed strong performance in phantom-based surgical experiments and demonstrates its potential for complex scenarios, including future real-world clinical applications.
AED: Automatic Discovery of Effective and Diverse Vulnerabilities for Autonomous Driving Policy with Large Language Models
Mar 24, 2025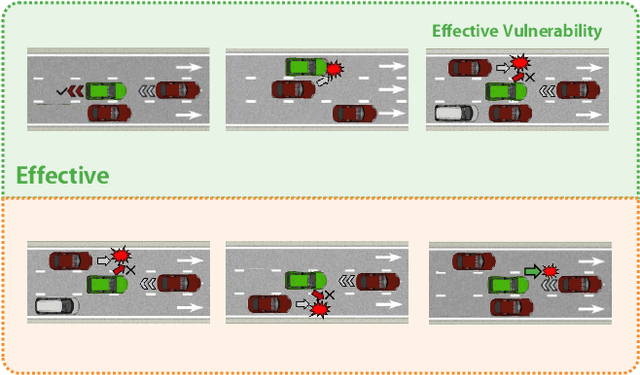


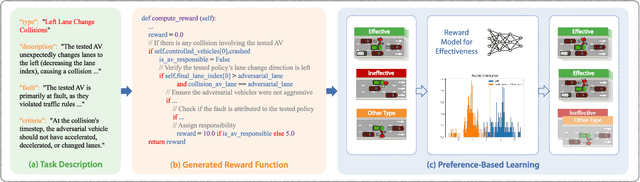
Assessing the safety of autonomous driving policy is of great importance, and reinforcement learning (RL) has emerged as a powerful method for discovering critical vulnerabilities in driving policies. However, existing RL-based approaches often struggle to identify vulnerabilities that are both effective-meaning the autonomous vehicle is genuinely responsible for the accidents-and diverse-meaning they span various failure types. To address these challenges, we propose AED, a framework that uses large language models (LLMs) to automatically discover effective and diverse vulnerabilities in autonomous driving policies. We first utilize an LLM to automatically design reward functions for RL training. Then we let the LLM consider a diverse set of accident types and train adversarial policies for different accident types in parallel. Finally, we use preference-based learning to filter ineffective accidents and enhance the effectiveness of each vulnerability. Experiments across multiple simulated traffic scenarios and tested policies show that AED uncovers a broader range of vulnerabilities and achieves higher attack success rates compared with expert-designed rewards, thereby reducing the need for manual reward engineering and improving the diversity and effectiveness of vulnerability discovery.
Multi-Robot System for Cooperative Exploration in Unknown Environments: A Survey
Mar 10, 2025With the advancement of multi-robot technology, cooperative exploration tasks have garnered increasing attention. This paper presents a comprehensive review of multi-robot cooperative exploration systems. First, we review the evolution of robotic exploration and introduce a modular research framework tailored for multi-robot cooperative exploration. Based on this framework, we systematically categorize and summarize key system components. As a foundational module for multi-robot exploration, the localization and mapping module is primarily introduced by focusing on global and relative pose estimation, as well as multi-robot map merging techniques. The cooperative motion module is further divided into learning-based approaches and multi-stage planning, with the latter encompassing target generation, task allocation, and motion planning strategies. Given the communication constraints of real-world environments, we also analyze the communication module, emphasizing how robots exchange information within local communication ranges and under limited transmission capabilities. Finally, we discuss the challenges and future research directions for multi-robot cooperative exploration in light of real-world trends. This review aims to serve as a valuable reference for researchers and practitioners in the field.
VolleyBots: A Testbed for Multi-Drone Volleyball Game Combining Motion Control and Strategic Play
Feb 04, 2025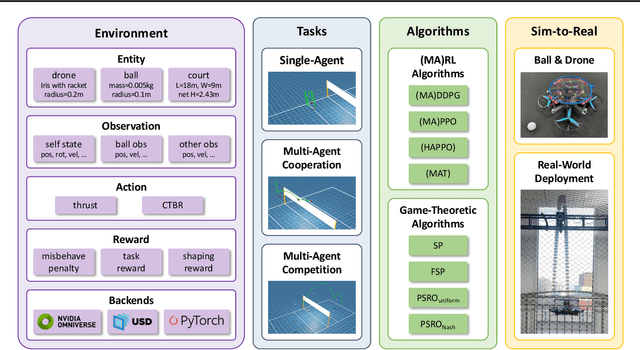
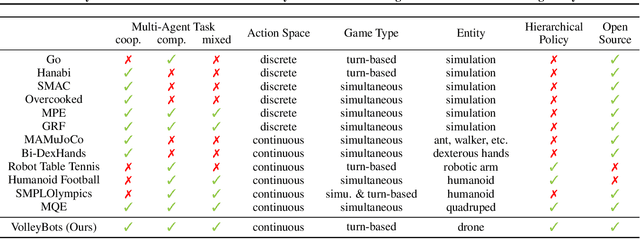
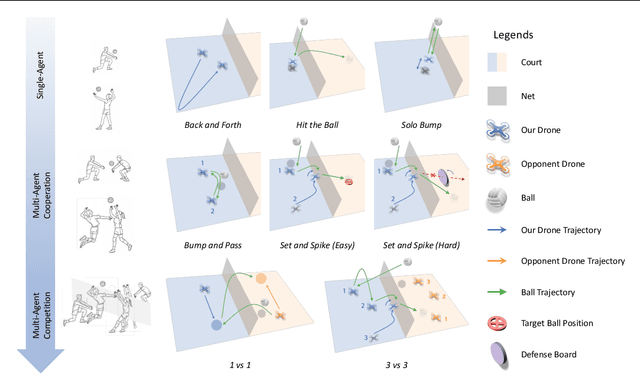

Multi-agent reinforcement learning (MARL) has made significant progress, largely fueled by the development of specialized testbeds that enable systematic evaluation of algorithms in controlled yet challenging scenarios. However, existing testbeds often focus on purely virtual simulations or limited robot morphologies such as robotic arms, quadrupeds, and humanoids, leaving high-mobility platforms with real-world physical constraints like drones underexplored. To bridge this gap, we present VolleyBots, a new MARL testbed where multiple drones cooperate and compete in the sport of volleyball under physical dynamics. VolleyBots features a turn-based interaction model under volleyball rules, a hierarchical decision-making process that combines motion control and strategic play, and a high-fidelity simulation for seamless sim-to-real transfer. We provide a comprehensive suite of tasks ranging from single-drone drills to multi-drone cooperative and competitive tasks, accompanied by baseline evaluations of representative MARL and game-theoretic algorithms. Results in simulation show that while existing algorithms handle simple tasks effectively, they encounter difficulty in complex tasks that require both low-level control and high-level strategy. We further demonstrate zero-shot deployment of a simulation-learned policy to real-world drones, highlighting VolleyBots' potential to propel MARL research involving agile robotic platforms. The project page is at https://sites.google.com/view/volleybots/home.