 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCategory-Prompt Refined Feature Learning for Long-Tailed Multi-Label Image Classification
Aug 15, 2024



Real-world data consistently exhibits a long-tailed distribution, often spanning multiple categories. This complexity underscores the challenge of content comprehension, particularly in scenarios requiring Long-Tailed Multi-Label image Classification (LTMLC). In such contexts, imbalanced data distribution and multi-object recognition pose significant hurdles. To address this issue, we propose a novel and effective approach for LTMLC, termed Category-Prompt Refined Feature Learning (CPRFL), utilizing semantic correlations between different categories and decoupling category-specific visual representations for each category. Specifically, CPRFL initializes category-prompts from the pretrained CLIP's embeddings and decouples category-specific visual representations through interaction with visual features, thereby facilitating the establishment of semantic correlations between the head and tail classes. To mitigate the visual-semantic domain bias, we design a progressive Dual-Path Back-Propagation mechanism to refine the prompts by progressively incorporating context-related visual information into prompts. Simultaneously, the refinement process facilitates the progressive purification of the category-specific visual representations under the guidance of the refined prompts. Furthermore, taking into account the negative-positive sample imbalance, we adopt the Asymmetric Loss as our optimization objective to suppress negative samples across all classes and potentially enhance the head-to-tail recognition performance. We validate the effectiveness of our method on two LTMLC benchmarks and extensive experiments demonstrate the superiority of our work over baselines. The code is available at https://github.com/jiexuanyan/CPRFL.
SAM-MIL: A Spatial Contextual Aware Multiple Instance Learning Approach for Whole Slide Image Classification
Jul 25, 2024
Multiple Instance Learning (MIL) represents the predominant framework in Whole Slide Image (WSI) classification, covering aspects such as sub-typing, diagnosis, and beyond. Current MIL models predominantly rely on instance-level features derived from pretrained models such as ResNet. These models segment each WSI into independent patches and extract features from these local patches, leading to a significant loss of global spatial context and restricting the model's focus to merely local features. To address this issue, we propose a novel MIL framework, named SAM-MIL, that emphasizes spatial contextual awareness and explicitly incorporates spatial context by extracting comprehensive, image-level information. The Segment Anything Model (SAM) represents a pioneering visual segmentation foundational model that can capture segmentation features without the need for additional fine-tuning, rendering it an outstanding tool for extracting spatial context directly from raw WSIs. Our approach includes the design of group feature extraction based on spatial context and a SAM-Guided Group Masking strategy to mitigate class imbalance issues. We implement a dynamic mask ratio for different segmentation categories and supplement these with representative group features of categories. Moreover, SAM-MIL divides instances to generate additional pseudo-bags, thereby augmenting the training set, and introduces consistency of spatial context across pseudo-bags to further enhance the model's performance. Experimental results on the CAMELYON-16 and TCGA Lung Cancer datasets demonstrate that our proposed SAM-MIL model outperforms existing mainstream methods in WSIs classification. Our open-source implementation code is is available at https://github.com/FangHeng/SAM-MIL.
Data Distribution Distilled Generative Model for Generalized Zero-Shot Recognition
Feb 18, 2024
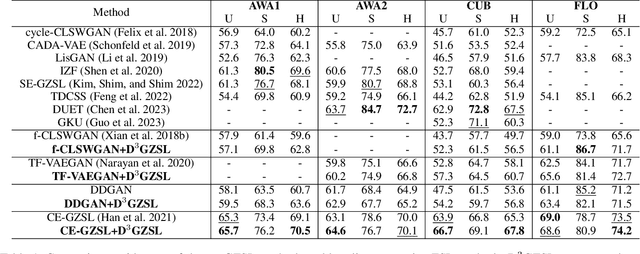
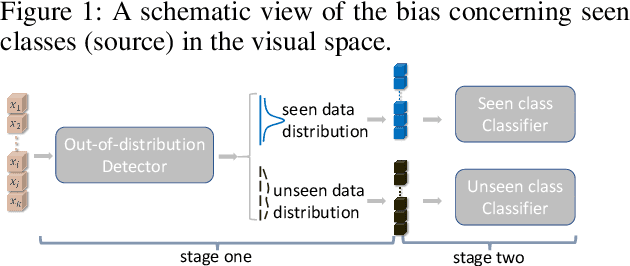

In the realm of Zero-Shot Learning (ZSL), we address biases in Generalized Zero-Shot Learning (GZSL) models, which favor seen data. To counter this, we introduce an end-to-end generative GZSL framework called D$^3$GZSL. This framework respects seen and synthesized unseen data as in-distribution and out-of-distribution data, respectively, for a more balanced model. D$^3$GZSL comprises two core modules: in-distribution dual space distillation (ID$^2$SD) and out-of-distribution batch distillation (O$^2$DBD). ID$^2$SD aligns teacher-student outcomes in embedding and label spaces, enhancing learning coherence. O$^2$DBD introduces low-dimensional out-of-distribution representations per batch sample, capturing shared structures between seen and unseen categories. Our approach demonstrates its effectiveness across established GZSL benchmarks, seamlessly integrating into mainstream generative frameworks. Extensive experiments consistently showcase that D$^3$GZSL elevates the performance of existing generative GZSL methods, underscoring its potential to refine zero-shot learning practices.The code is available at: https://github.com/PJBQ/D3GZSL.git
Kernel Inversed Pyramidal Resizing Network for Efficient Pavement Distress Recognition
Dec 04, 2022


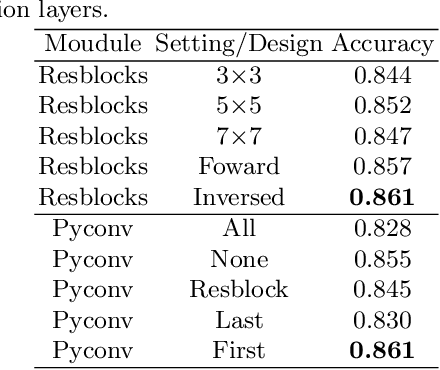
Pavement Distress Recognition (PDR) is an important step in pavement inspection and can be powered by image-based automation to expedite the process and reduce labor costs. Pavement images are often in high-resolution with a low ratio of distressed to non-distressed areas. Advanced approaches leverage these properties via dividing images into patches and explore discriminative features in the scale space. However, these approaches usually suffer from information loss during image resizing and low efficiency due to complex learning frameworks. In this paper, we propose a novel and efficient method for PDR. A light network named the Kernel Inversed Pyramidal Resizing Network (KIPRN) is introduced for image resizing, and can be flexibly plugged into the image classification network as a pre-network to exploit resolution and scale information. In KIPRN, pyramidal convolution and kernel inversed convolution are specifically designed to mine discriminative information across different feature granularities and scales. The mined information is passed along to the resized images to yield an informative image pyramid to assist the image classification network for PDR. We applied our method to three well-known Convolutional Neural Networks (CNNs), and conducted an evaluation on a large-scale pavement image dataset named CQU-BPDD. Extensive results demonstrate that KIPRN can generally improve the pavement distress recognition of these CNN models and show that the simple combination of KIPRN and EfficientNet-B3 significantly outperforms the state-of-the-art patch-based method in both performance and efficiency.
PicT: A Slim Weakly Supervised Vision Transformer for Pavement Distress Classification
Sep 21, 2022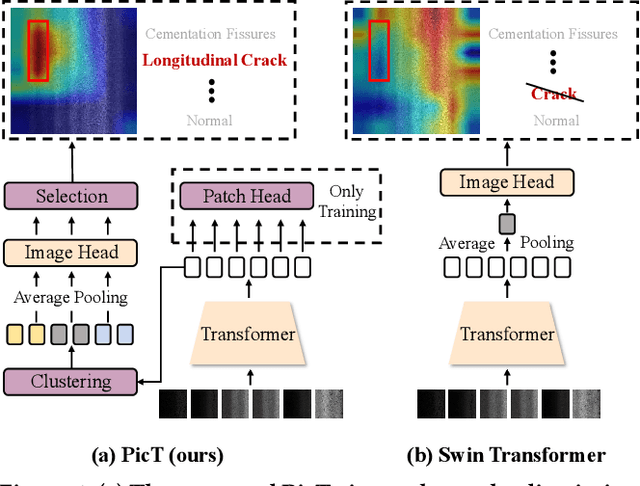
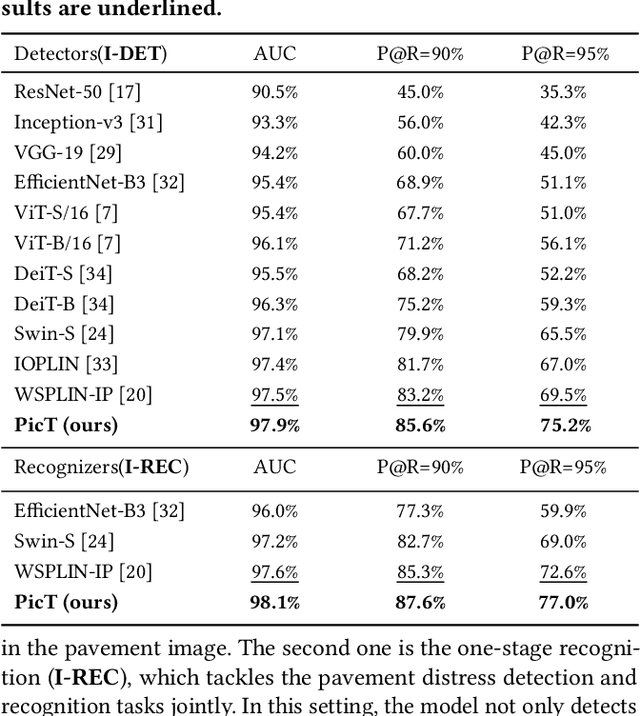
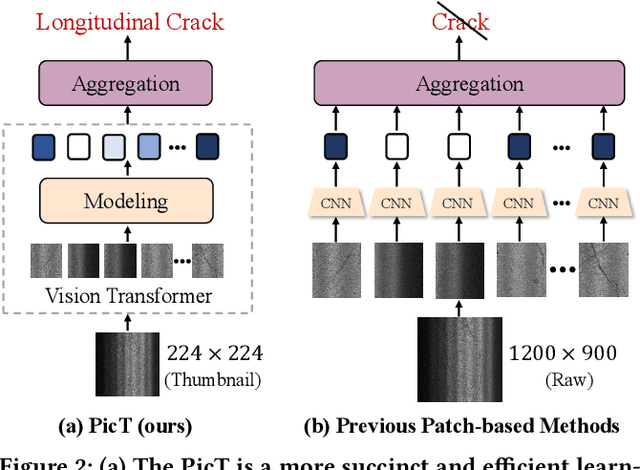
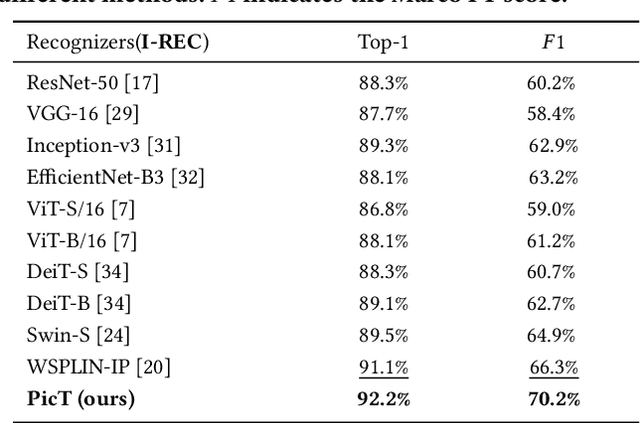
Automatic pavement distress classification facilitates improving the efficiency of pavement maintenance and reducing the cost of labor and resources. A recently influential branch of this task divides the pavement image into patches and addresses these issues from the perspective of multi-instance learning. However, these methods neglect the correlation between patches and suffer from a low efficiency in the model optimization and inference. Meanwhile, Swin Transformer is able to address both of these issues with its unique strengths. Built upon Swin Transformer, we present a vision Transformer named \textbf{P}avement \textbf{I}mage \textbf{C}lassification \textbf{T}ransformer (\textbf{PicT}) for pavement distress classification. In order to better exploit the discriminative information of pavement images at the patch level, the \textit{Patch Labeling Teacher} is proposed to leverage a teacher model to dynamically generate pseudo labels of patches from image labels during each iteration, and guides the model to learn the discriminative features of patches. The broad classification head of Swin Transformer may dilute the discriminative features of distressed patches in the feature aggregation step due to the small distressed area ratio of the pavement image. To overcome this drawback, we present a \textit{Patch Refiner} to cluster patches into different groups and only select the highest distress-risk group to yield a slim head for the final image classification. We evaluate our method on CQU-BPDD. Extensive results show that \textbf{PicT} outperforms the second-best performed model by a large margin of $+2.4\%$ in P@R on detection task, $+3.9\%$ in $F1$ on recognition task, and 1.8x throughput, while enjoying 7x faster training speed using the same computing resources. Our codes and models have been released on \href{https://github.com/DearCaat/PicT}{https://github.com/DearCaat/PicT}.
Boosting Multi-Label Image Classification with Complementary Parallel Self-Distillation
May 23, 2022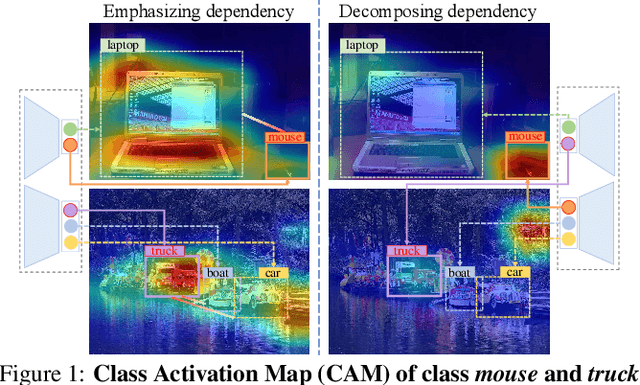
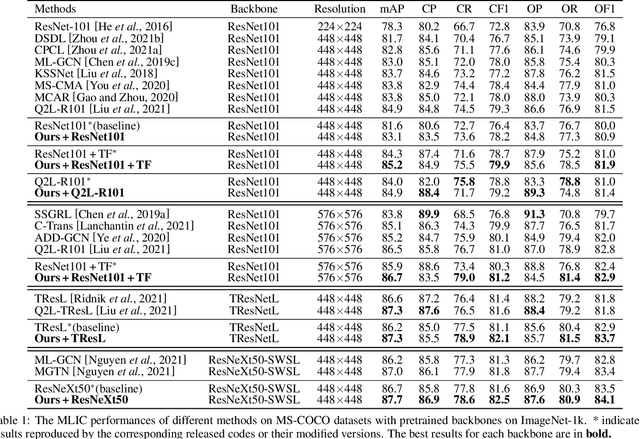
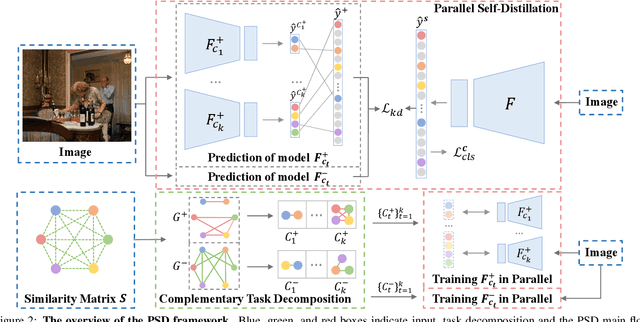
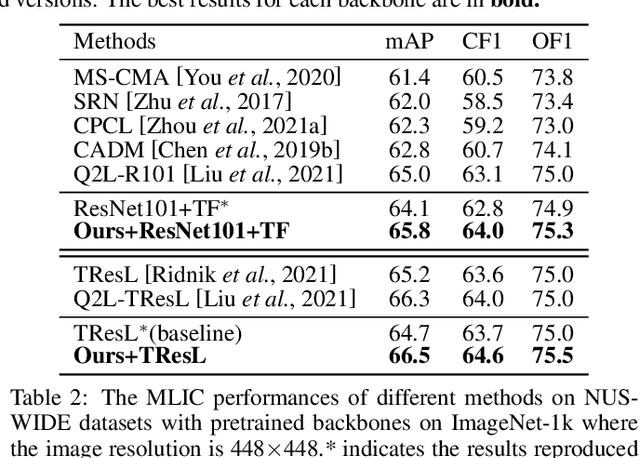
Multi-Label Image Classification (MLIC) approaches usually exploit label correlations to achieve good performance. However, emphasizing correlation like co-occurrence may overlook discriminative features of the target itself and lead to model overfitting, thus undermining the performance. In this study, we propose a generic framework named Parallel Self-Distillation (PSD) for boosting MLIC models. PSD decomposes the original MLIC task into several simpler MLIC sub-tasks via two elaborated complementary task decomposition strategies named Co-occurrence Graph Partition (CGP) and Dis-occurrence Graph Partition (DGP). Then, the MLIC models of fewer categories are trained with these sub-tasks in parallel for respectively learning the joint patterns and the category-specific patterns of labels. Finally, knowledge distillation is leveraged to learn a compact global ensemble of full categories with these learned patterns for reconciling the label correlation exploitation and model overfitting. Extensive results on MS-COCO and NUS-WIDE datasets demonstrate that our framework can be easily plugged into many MLIC approaches and improve performances of recent state-of-the-art approaches. The explainable visual study also further validates that our method is able to learn both the category-specific and co-occurring features. The source code is released at https://github.com/Robbie-Xu/CPSD.
Weakly Supervised Patch Label Inference Networks for Efficient Pavement Distress Detection and Recognition in the Wild
Mar 31, 2022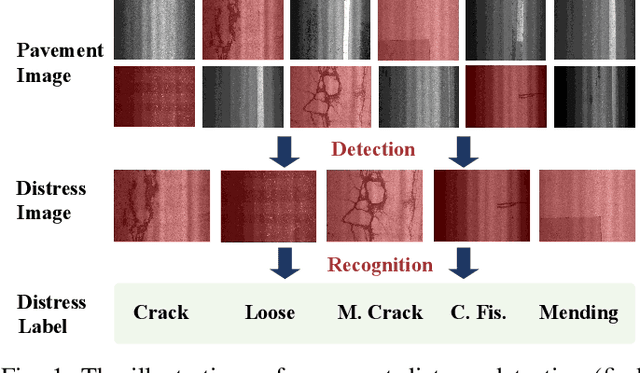
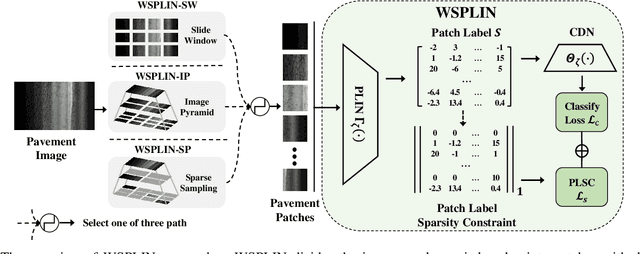

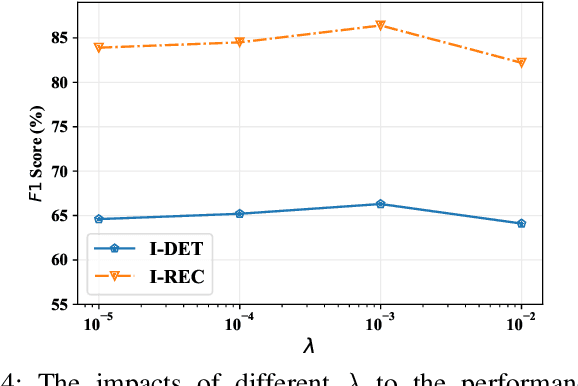
Automatic image-based pavement distress detection and recognition are vital for pavement maintenance and management. However, existing deep learning-based methods largely omit the specific characteristics of pavement images, such as high image resolution and low distress area ratio, and are not end-to-end trainable. In this paper, we present a series of simple yet effective end-to-end deep learning approaches named Weakly Supervised Patch Label Inference Networks (WSPLIN) for efficiently addressing these tasks under various application settings. To fully exploit the resolution and scale information, WSPLIN first divides the pavement image under different scales into patches with different collection strategies and then employs a Patch Label Inference Network (PLIN) to infer the labels of these patches. Notably, we design a patch label sparsity constraint based on the prior knowledge of distress distribution, and leverage the Comprehensive Decision Network (CDN) to guide the training of PLIN in a weakly supervised way. Therefore, the patch labels produced by PLIN provide interpretable intermediate information, such as the rough location and the type of distress. We evaluate our method on a large-scale bituminous pavement distress dataset named CQU-BPDD. Extensive results demonstrate the superiority of our method over baselines in both performance and efficiency.
Iteratively Optimized Patch Label Inference Network for Automatic Pavement Disease Detection
May 27, 2020
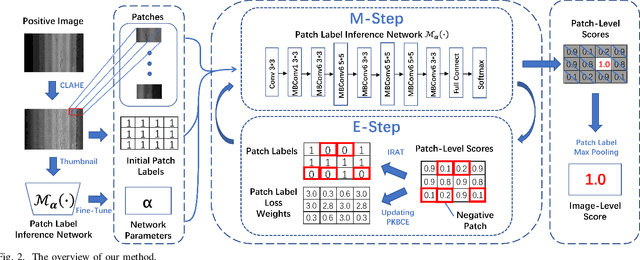
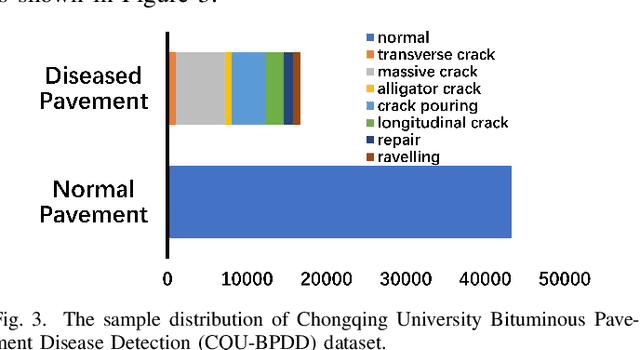
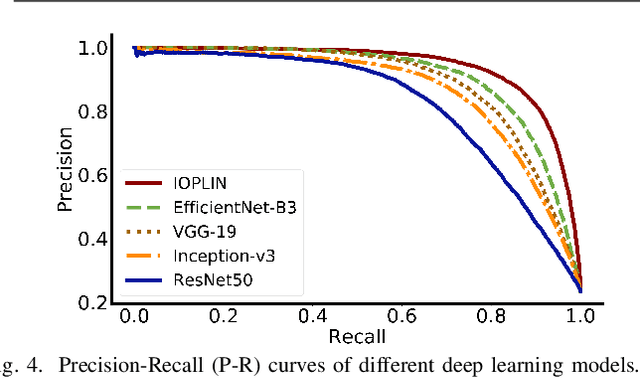
We present a novel deep learning framework named Iteratively Optimized Patch Label Inference Network (IOPLIN) for automatically detecting various pavement diseases not just limited to the specific ones, such as crack and pothole. IOPLIN can be iteratively trained with only the image label via using Expectation-Maximization Inspired Patch Label Distillation (EMIPLD) strategy, and accomplishes this task well by inferring the labels of patches from the pavement images. IOPLIN enjoys many desirable properties over the state-of-the-art single branch CNN models such as GoogLeNet and EfficientNet. It is able to handle any resolution of image and sufficiently utilize image information particularly for the high-resolution ones. Moreover, it can roughly localize the pavement distress without using any prior localization information in training phase. In order to better evaluate the effectiveness of our method in practice, we construct a large-scale Bituminous Pavement Disease Detection dataset named CQU-BPDD consists of 60059 high-resolution pavement images, which are acquired from different areas at different time. Extensive results on this dataset demonstrate the superiority of IOPLIN over the state-of-the-art image classificaiton approaches in automatic pavement disease detection.
Towards using social media to identify individuals at risk for preventable chronic illness
Mar 11, 2016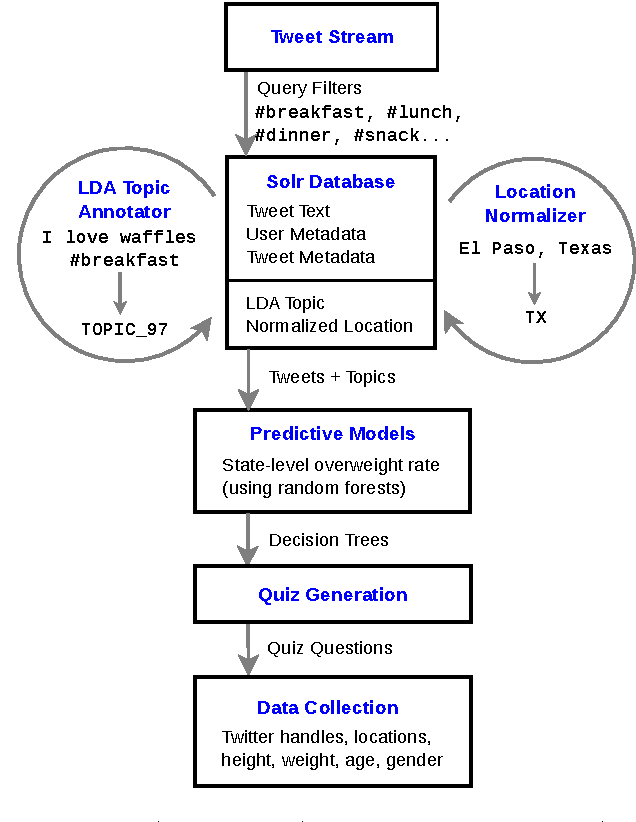

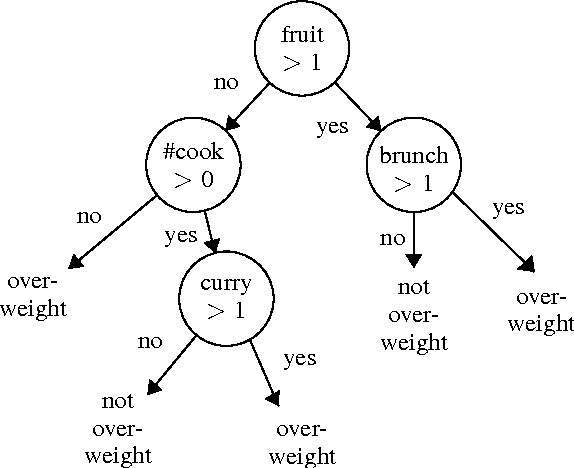
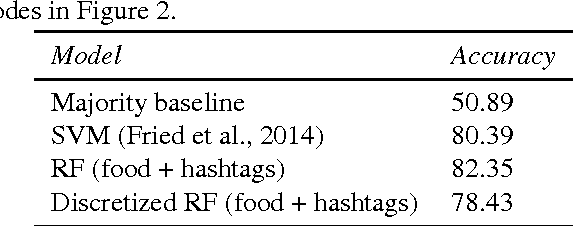
We describe a strategy for the acquisition of training data necessary to build a social-media-driven early detection system for individuals at risk for (preventable) type 2 diabetes mellitus (T2DM). The strategy uses a game-like quiz with data and questions acquired semi-automatically from Twitter. The questions are designed to inspire participant engagement and collect relevant data to train a public-health model applied to individuals. Prior systems designed to use social media such as Twitter to predict obesity (a risk factor for T2DM) operate on entire communities such as states, counties, or cities, based on statistics gathered by government agencies. Because there is considerable variation among individuals within these groups, training data on the individual level would be more effective, but this data is difficult to acquire. The approach proposed here aims to address this issue. Our strategy has two steps. First, we trained a random forest classifier on data gathered from (public) Twitter statuses and state-level statistics with state-of-the-art accuracy. We then converted this classifier into a 20-questions-style quiz and made it available online. In doing so, we achieved high engagement with individuals that took the quiz, while also building a training set of voluntarily supplied individual-level data for future classification.
Sparse Graph-based Transduction for Image Classification
Dec 12, 2014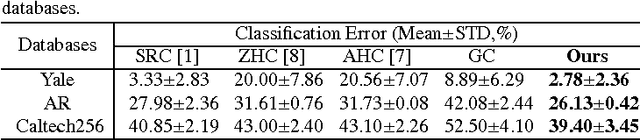
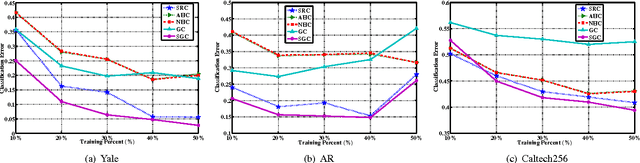
Motivated by the remarkable successes of Graph-based Transduction (GT) and Sparse Representation (SR), we present a novel Classifier named Sparse Graph-based Classifier (SGC) for image classification. In SGC, SR is leveraged to measure the correlation (similarity) of each two samples and a graph is constructed for encoding these correlations. Then the Laplacian eigenmapping is adopted for deriving the graph Laplacian of the graph. Finally, SGC can be obtained by plugging the graph Laplacian into the conventional GT framework. In the image classification procedure, SGC utilizes the correlations, which are encoded in the learned graph Laplacian, to infer the labels of unlabeled images. SGC inherits the merits of both GT and SR. Compared to SR, SGC improves the robustness and the discriminating power of GT. Compared to GT, SGC sufficiently exploits the whole data. Therefore it alleviates the undercomplete dictionary issue suffered by SR. Four popular image databases are employed for evaluation. The results demonstrate that SGC can achieve a promising performance in comparison with the state-of-the-art classifiers, particularly in the small training sample size case and the noisy sample case.