 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel Inversed Pyramidal Resizing Network for Efficient Pavement Distress Recognition
Dec 04, 2022


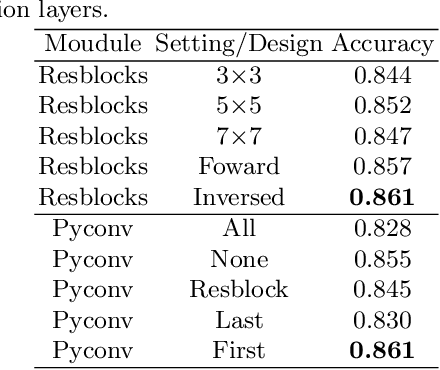
Pavement Distress Recognition (PDR) is an important step in pavement inspection and can be powered by image-based automation to expedite the process and reduce labor costs. Pavement images are often in high-resolution with a low ratio of distressed to non-distressed areas. Advanced approaches leverage these properties via dividing images into patches and explore discriminative features in the scale space. However, these approaches usually suffer from information loss during image resizing and low efficiency due to complex learning frameworks. In this paper, we propose a novel and efficient method for PDR. A light network named the Kernel Inversed Pyramidal Resizing Network (KIPRN) is introduced for image resizing, and can be flexibly plugged into the image classification network as a pre-network to exploit resolution and scale information. In KIPRN, pyramidal convolution and kernel inversed convolution are specifically designed to mine discriminative information across different feature granularities and scales. The mined information is passed along to the resized images to yield an informative image pyramid to assist the image classification network for PDR. We applied our method to three well-known Convolutional Neural Networks (CNNs), and conducted an evaluation on a large-scale pavement image dataset named CQU-BPDD. Extensive results demonstrate that KIPRN can generally improve the pavement distress recognition of these CNN models and show that the simple combination of KIPRN and EfficientNet-B3 significantly outperforms the state-of-the-art patch-based method in both performance and efficiency.
Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task
Oct 25, 2018
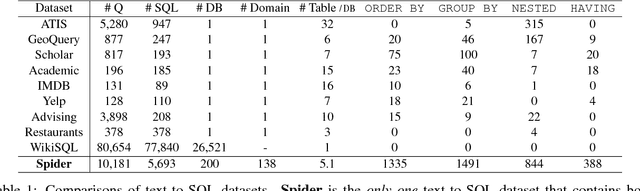
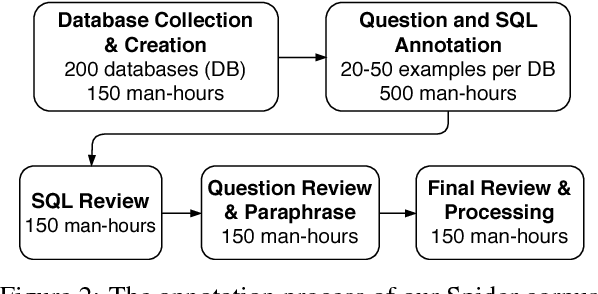

We present Spider, a large-scale, complex and cross-domain semantic parsing and text-to-SQL dataset annotated by 11 college students. It consists of 10,181 questions and 5,693 unique complex SQL queries on 200 databases with multiple tables, covering 138 different domains. We define a new complex and cross-domain semantic parsing and text-to-SQL task where different complex SQL queries and databases appear in train and test sets. In this way, the task requires the model to generalize well to both new SQL queries and new database schemas. Spider is distinct from most of the previous semantic parsing tasks because they all use a single database and the exact same programs in the train set and the test set. We experiment with various state-of-the-art models and the best model achieves only 12.4% exact matching accuracy on a database split setting. This shows that Spider presents a strong challenge for future research. Our dataset and task are publicly available at https://yale-lily.github.io/spider