 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Hierarchical Reinforcement Learning for Adaptive Traffic Signal Control
Apr 07, 2025Multi-agent reinforcement learning (MARL) has shown promise for adaptive traffic signal control (ATSC), enabling multiple intersections to coordinate signal timings in real time. However, in large-scale settings, MARL faces constraints due to extensive data sharing and communication requirements. Federated learning (FL) mitigates these challenges by training shared models without directly exchanging raw data, yet traditional FL methods such as FedAvg struggle with highly heterogeneous intersections. Different intersections exhibit varying traffic patterns, demands, and road structures, so performing FedAvg across all agents is inefficient. To address this gap, we propose Hierarchical Federated Reinforcement Learning (HFRL) for ATSC. HFRL employs clustering-based or optimization-based techniques to dynamically group intersections and perform FedAvg independently within groups of intersections with similar characteristics, enabling more effective coordination and scalability than standard FedAvg. Our experiments on synthetic and real-world traffic networks demonstrate that HFRL not only outperforms both decentralized and standard federated RL approaches but also identifies suitable grouping patterns based on network structure or traffic demand, resulting in a more robust framework for distributed, heterogeneous systems.
From seeing to remembering: Images with harder-to-reconstruct representations leave stronger memory traces
Feb 21, 2023Much of what we remember is not due to intentional selection, but simply a by-product of perceiving. This raises a foundational question about the architecture of the mind: How does perception interface with and influence memory? Here, inspired by a classic proposal relating perceptual processing to memory durability, the level-of-processing theory, we present a sparse coding model for compressing feature embeddings of images, and show that the reconstruction residuals from this model predict how well images are encoded into memory. In an open memorability dataset of scene images, we show that reconstruction error not only explains memory accuracy but also response latencies during retrieval, subsuming, in the latter case, all of the variance explained by powerful vision-only models. We also confirm a prediction of this account with 'model-driven psychophysics'. This work establishes reconstruction error as a novel signal interfacing perception and memory, possibly through adaptive modulation of perceptual processing.
CoSQL: A Conversational Text-to-SQL Challenge Towards Cross-Domain Natural Language Interfaces to Databases
Sep 11, 2019
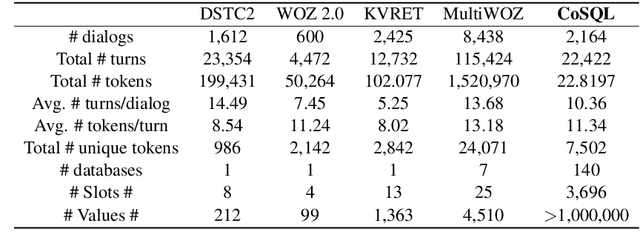
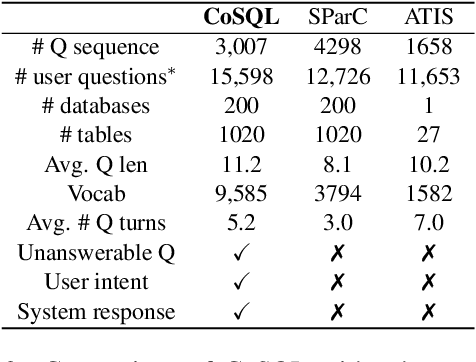
We present CoSQL, a corpus for building cross-domain, general-purpose database (DB) querying dialogue systems. It consists of 30k+ turns plus 10k+ annotated SQL queries, obtained from a Wizard-of-Oz (WOZ) collection of 3k dialogues querying 200 complex DBs spanning 138 domains. Each dialogue simulates a real-world DB query scenario with a crowd worker as a user exploring the DB and a SQL expert retrieving answers with SQL, clarifying ambiguous questions, or otherwise informing of unanswerable questions. When user questions are answerable by SQL, the expert describes the SQL and execution results to the user, hence maintaining a natural interaction flow. CoSQL introduces new challenges compared to existing task-oriented dialogue datasets:(1) the dialogue states are grounded in SQL, a domain-independent executable representation, instead of domain-specific slot-value pairs, and (2) because testing is done on unseen databases, success requires generalizing to new domains. CoSQL includes three tasks: SQL-grounded dialogue state tracking, response generation from query results, and user dialogue act prediction. We evaluate a set of strong baselines for each task and show that CoSQL presents significant challenges for future research. The dataset, baselines, and leaderboard will be released at https://yale-lily.github.io/cosql.
Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task
Oct 25, 2018
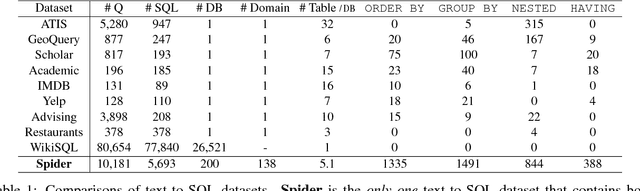
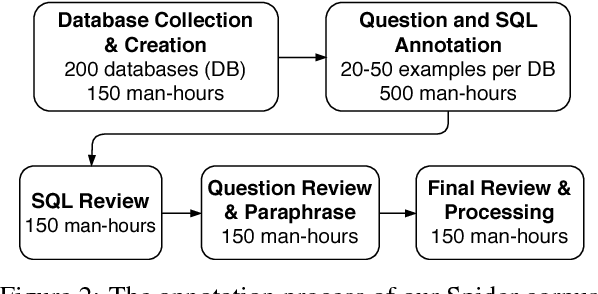

We present Spider, a large-scale, complex and cross-domain semantic parsing and text-to-SQL dataset annotated by 11 college students. It consists of 10,181 questions and 5,693 unique complex SQL queries on 200 databases with multiple tables, covering 138 different domains. We define a new complex and cross-domain semantic parsing and text-to-SQL task where different complex SQL queries and databases appear in train and test sets. In this way, the task requires the model to generalize well to both new SQL queries and new database schemas. Spider is distinct from most of the previous semantic parsing tasks because they all use a single database and the exact same programs in the train set and the test set. We experiment with various state-of-the-art models and the best model achieves only 12.4% exact matching accuracy on a database split setting. This shows that Spider presents a strong challenge for future research. Our dataset and task are publicly available at https://yale-lily.github.io/spider
SyntaxSQLNet: Syntax Tree Networks for Complex and Cross-DomainText-to-SQL Task
Oct 25, 2018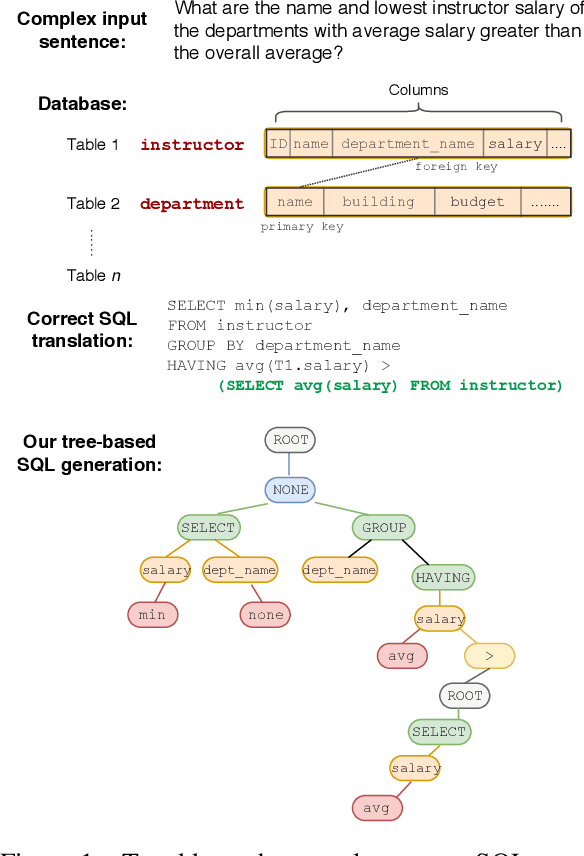
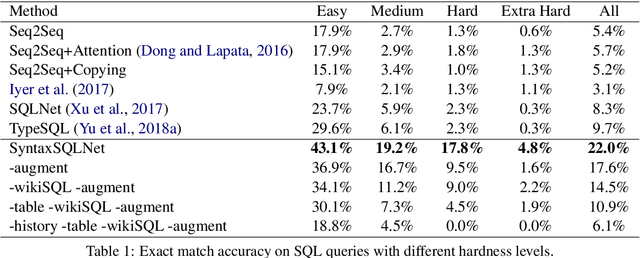
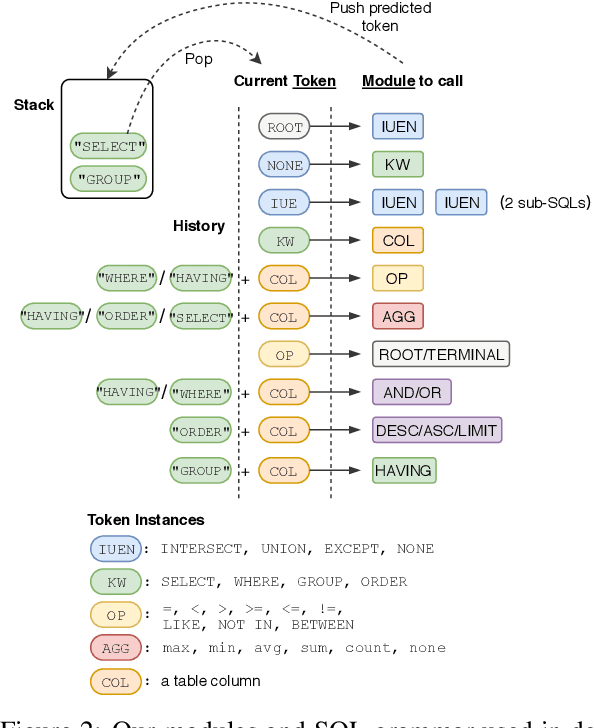
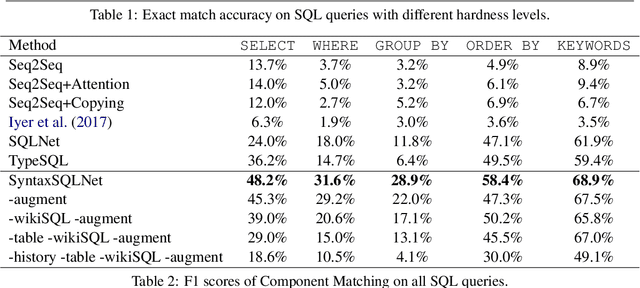
Most existing studies in text-to-SQL tasks do not require generating complex SQL queries with multiple clauses or sub-queries, and generalizing to new, unseen databases. In this paper we propose SyntaxSQLNet, a syntax tree network to address the complex and cross-domain text-to-SQL generation task. SyntaxSQLNet employs a SQL specific syntax tree-based decoder with SQL generation path history and table-aware column attention encoders. We evaluate SyntaxSQLNet on the Spider text-to-SQL task, which contains databases with multiple tables and complex SQL queries with multiple SQL clauses and nested queries. We use a database split setting where databases in the test set are unseen during training. Experimental results show that SyntaxSQLNet can handle a significantly greater number of complex SQL examples than prior work, outperforming the previous state-of-the-art model by 7.3% in exact matching accuracy. We also show that SyntaxSQLNet can further improve the performance by an additional 7.5% using a cross-domain augmentation method, resulting in a 14.8% improvement in total. To our knowledge, we are the first to study this complex and cross-domain text-to-SQL task.
TypeSQL: Knowledge-based Type-Aware Neural Text-to-SQL Generation
Apr 25, 2018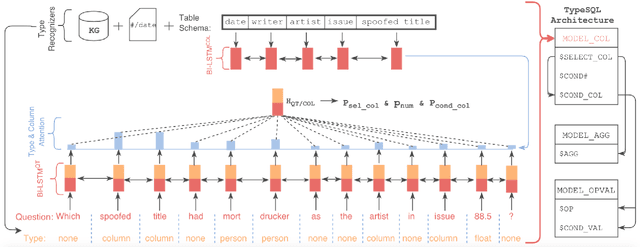

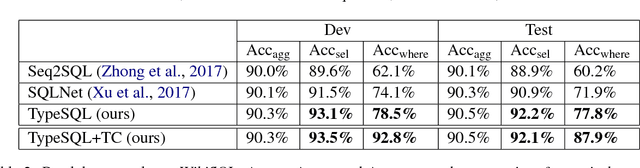
Interacting with relational databases through natural language helps users of any background easily query and analyze a vast amount of data. This requires a system that understands users' questions and converts them to SQL queries automatically. In this paper we present a novel approach, TypeSQL, which views this problem as a slot filling task. Additionally, TypeSQL utilizes type information to better understand rare entities and numbers in natural language questions. We test this idea on the WikiSQL dataset and outperform the prior state-of-the-art by 5.5% in much less time. We also show that accessing the content of databases can significantly improve the performance when users' queries are not well-formed. TypeSQL gets 82.6% accuracy, a 17.5% absolute improvement compared to the previous content-sensitive model.
* NAACL 2018
Lasso Guarantees for Time Series Estimation Under Subgaussian Tails and $ β$-Mixing
Feb 05, 2018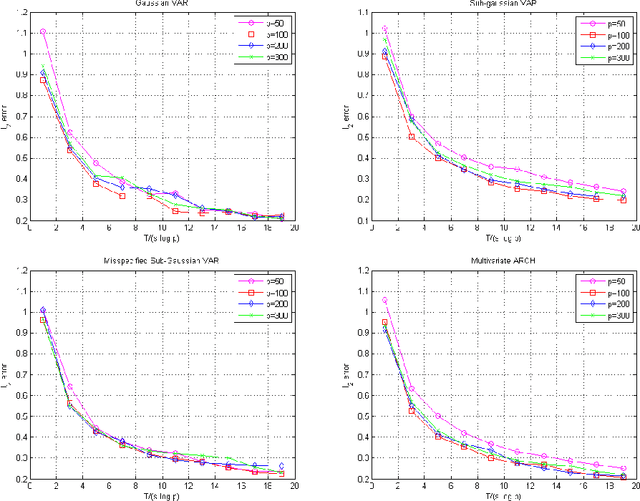
Many theoretical results on estimation of high dimensional time series require specifying an underlying data generating model (DGM). Instead, along the footsteps of~\cite{wong2017lasso}, this paper relies only on (strict) stationarity and $ \beta $-mixing condition to establish consistency of lasso when data comes from a $\beta$-mixing process with marginals having subgaussian tails. Because of the general assumptions, the data can come from DGMs different than standard time series models such as VAR or ARCH. When the true DGM is not VAR, the lasso estimates correspond to those of the best linear predictors using the past observations. We establish non-asymptotic inequalities for estimation and prediction errors of the lasso estimates. Together with~\cite{wong2017lasso}, we provide lasso guarantees that cover full spectrum of the parameters in specifications of $ \beta $-mixing subgaussian time series. Applications of these results potentially extend to non-Gaussian, non-Markovian and non-linear times series models as the examples we provide demonstrate. In order to prove our results, we derive a novel Hanson-Wright type concentration inequality for $\beta$-mixing subgaussian random vectors that may be of independent interest.
Beyond the Hazard Rate: More Perturbation Algorithms for Adversarial Multi-armed Bandits
Jan 05, 2018Recent work on follow the perturbed leader (FTPL) algorithms for the adversarial multi-armed bandit problem has highlighted the role of the hazard rate of the distribution generating the perturbations. Assuming that the hazard rate is bounded, it is possible to provide regret analyses for a variety of FTPL algorithms for the multi-armed bandit problem. This paper pushes the inquiry into regret bounds for FTPL algorithms beyond the bounded hazard rate condition. There are good reasons to do so: natural distributions such as the uniform and Gaussian violate the condition. We give regret bounds for both bounded support and unbounded support distributions without assuming the hazard rate condition. We also disprove a conjecture that the Gaussian distribution cannot lead to a low-regret algorithm. In fact, it turns out that it leads to near optimal regret, up to logarithmic factors. A key ingredient in our approach is the introduction of a new notion called the generalized hazard rate.
Sampled Fictitious Play is Hannan Consistent
Apr 11, 2017Fictitious play is a simple and widely studied adaptive heuristic for playing repeated games. It is well known that fictitious play fails to be Hannan consistent. Several variants of fictitious play including regret matching, generalized regret matching and smooth fictitious play, are known to be Hannan consistent. In this note, we consider sampled fictitious play: at each round, the player samples past times and plays the best response to previous moves of other players at the sampled time points. We show that sampled fictitious play, using Bernoulli sampling, is Hannan consistent. Unlike several existing Hannan consistency proofs that rely on concentration of measure results, ours instead uses anti-concentration results from Littlewood-Offord theory.