 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCEAN: An Openspace Collision-free Trajectory Planner for Autonomous Parking Based on ADMM
Mar 08, 2024



In this paper, we propose an Openspace Collision-freE trAjectory plaNner (OCEAN) for autonomous parking. OCEAN is an optimization-based trajectory planner accelerated by Alternating Direction Method of Multiplier (ADMM) with enhanced computational efficiency and robustness, and is suitable for all scenes with few dynamic obstacles. Starting from a hierarchical optimization-based collision avoidance framework, the trajectory planning problem is first warm-started by a collision-free Hybrid A* trajectory, then the collision avoidance trajectory planning problem is reformulated as a smooth and convex dual form, and solved by ADMM in parallel. The optimization variables are carefully split into several groups so that ADMM sub-problems are formulated as Quadratic Programming (QP), Sequential Quadratic Programming (SQP),and Second Order Cone Programming (SOCP) problems that can be efficiently and robustly solved. We validate our method both in hundreds of simulation scenarios and hundreds of hours of public parking areas. The results show that the proposed method has better system performance compared with other benchmarks.
Related Work on Image Quality Assessment
Nov 11, 2021Due to the existence of quality degradations introduced in various stages of visual signal acquisition, compression, transmission and display, image quality assessment (IQA) plays a vital role in image-based applications. According to whether the reference image is complete and available, image quality evaluation can be divided into three categories: Full-Reference(FR), Reduced- Reference(RR), and Non- Reference(NR). This article will review the state-of-the-art image quality assessment algorithms.
Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task
Oct 25, 2018
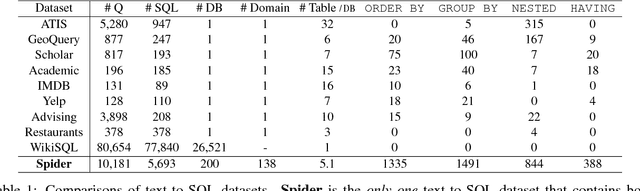
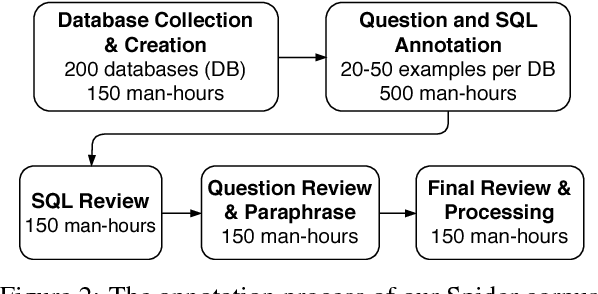

We present Spider, a large-scale, complex and cross-domain semantic parsing and text-to-SQL dataset annotated by 11 college students. It consists of 10,181 questions and 5,693 unique complex SQL queries on 200 databases with multiple tables, covering 138 different domains. We define a new complex and cross-domain semantic parsing and text-to-SQL task where different complex SQL queries and databases appear in train and test sets. In this way, the task requires the model to generalize well to both new SQL queries and new database schemas. Spider is distinct from most of the previous semantic parsing tasks because they all use a single database and the exact same programs in the train set and the test set. We experiment with various state-of-the-art models and the best model achieves only 12.4% exact matching accuracy on a database split setting. This shows that Spider presents a strong challenge for future research. Our dataset and task are publicly available at https://yale-lily.github.io/spider
SyntaxSQLNet: Syntax Tree Networks for Complex and Cross-DomainText-to-SQL Task
Oct 25, 2018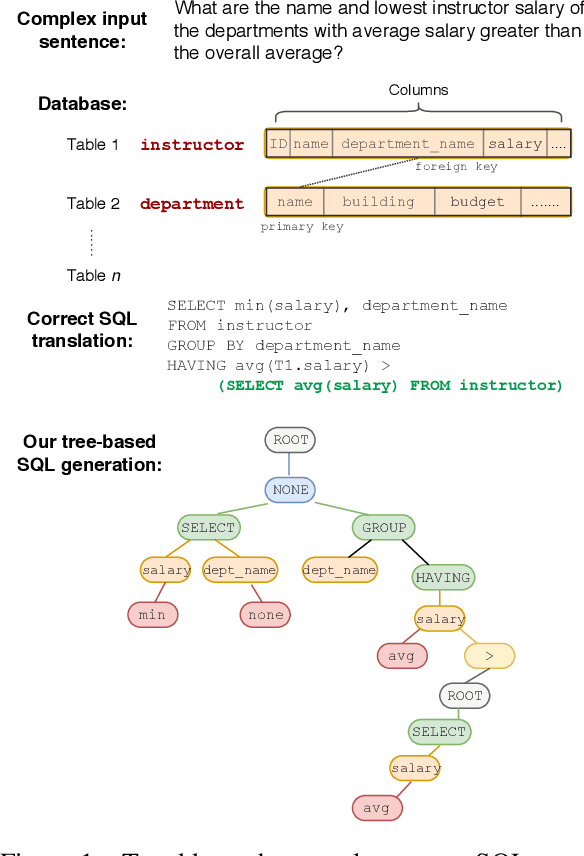
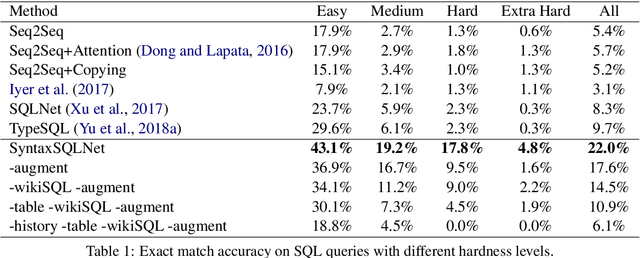
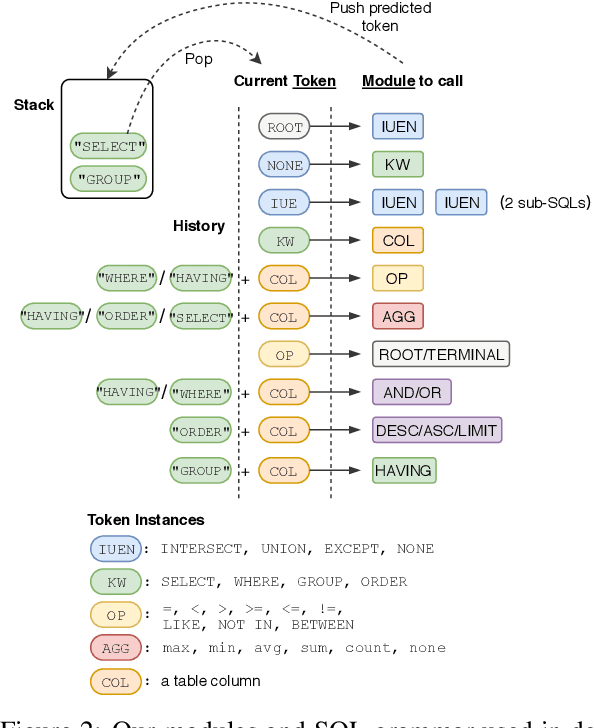
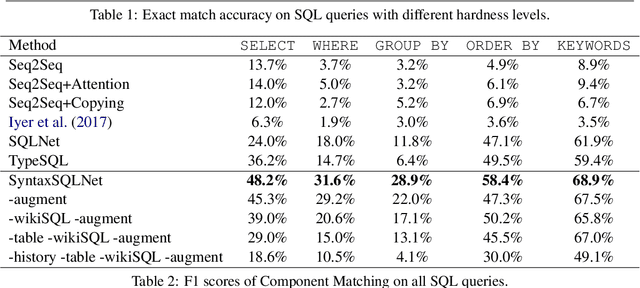
Most existing studies in text-to-SQL tasks do not require generating complex SQL queries with multiple clauses or sub-queries, and generalizing to new, unseen databases. In this paper we propose SyntaxSQLNet, a syntax tree network to address the complex and cross-domain text-to-SQL generation task. SyntaxSQLNet employs a SQL specific syntax tree-based decoder with SQL generation path history and table-aware column attention encoders. We evaluate SyntaxSQLNet on the Spider text-to-SQL task, which contains databases with multiple tables and complex SQL queries with multiple SQL clauses and nested queries. We use a database split setting where databases in the test set are unseen during training. Experimental results show that SyntaxSQLNet can handle a significantly greater number of complex SQL examples than prior work, outperforming the previous state-of-the-art model by 7.3% in exact matching accuracy. We also show that SyntaxSQLNet can further improve the performance by an additional 7.5% using a cross-domain augmentation method, resulting in a 14.8% improvement in total. To our knowledge, we are the first to study this complex and cross-domain text-to-SQL task.
BEBP: An Poisoning Method Against Machine Learning Based IDSs
Mar 11, 2018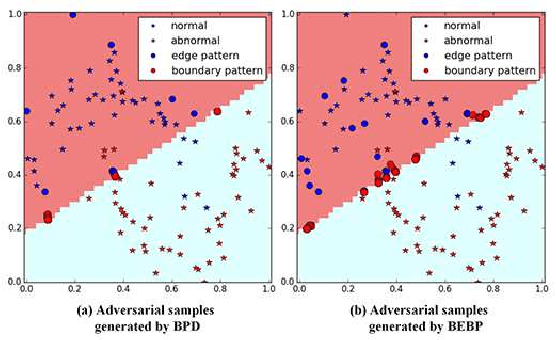



In big data era, machine learning is one of fundamental techniques in intrusion detection systems (IDSs). However, practical IDSs generally update their decision module by feeding new data then retraining learning models in a periodical way. Hence, some attacks that comprise the data for training or testing classifiers significantly challenge the detecting capability of machine learning-based IDSs. Poisoning attack, which is one of the most recognized security threats towards machine learning-based IDSs, injects some adversarial samples into the training phase, inducing data drifting of training data and a significant performance decrease of target IDSs over testing data. In this paper, we adopt the Edge Pattern Detection (EPD) algorithm to design a novel poisoning method that attack against several machine learning algorithms used in IDSs. Specifically, we propose a boundary pattern detection algorithm to efficiently generate the points that are near to abnormal data but considered to be normal ones by current classifiers. Then, we introduce a Batch-EPD Boundary Pattern (BEBP) detection algorithm to overcome the limitation of the number of edge pattern points generated by EPD and to obtain more useful adversarial samples. Based on BEBP, we further present a moderate but effective poisoning method called chronic poisoning attack. Extensive experiments on synthetic and three real network data sets demonstrate the performance of the proposed poisoning method against several well-known machine learning algorithms and a practical intrusion detection method named FMIFS-LSSVM-IDS.